Overview
Siri is a personal assistant that uses speech synthesis to communicate with users. Since iOS 10, Apple has applied deep learning to Siri's voice, and iOS 11 continues to use this technology. Deep learning has made Siri's voice more natural, fluent, and humanlike.
Introduction
Speech synthesis, the artificial production of human voice, is widely used across assistants, games, and entertainment. Recently, together with speech recognition, speech synthesis has become an essential part of voice assistants such as Siri.
There are two main speech synthesis approaches in industry today: unit selection [1] and parametric synthesis [2]. Unit selection can produce the highest quality when sufficiently large, high-quality recordings are available, which is why it is common in commercial products. Parametric synthesis produces intelligible and smooth speech with lower overall quality, but it is suitable when the training corpus is small or resource constraints exist. Modern unit selection systems combine strengths of both approaches and are therefore called hybrid systems. The hybrid unit selection approach is similar to traditional unit selection, but it uses parametric synthesis techniques to predict which units to select.
Deep learning has recently had a major impact on speech technologies, greatly outperforming traditional methods such as hidden Markov models. Parametric synthesis has also benefited from deep learning. Deep learning has enabled a new approach that directly models waveforms (for example, WaveNet). This approach has high potential, offering both the quality of unit selection and the flexibility of parametric methods. However, it remains computationally expensive and is not yet mature for all product deployment. To deliver the best quality across platforms, Apple adopted deep learning within an on-device hybrid unit selection system for Siri.
How Apple's Deep Speech Synthesis Works
Building a high-quality text-to-speech (TTS) system for a personal assistant is a complex task. The first stage is finding a professional voice talent whose voice is pleasant, intelligible, and matches the assistant's character. To cover a variety of utterances, the team records 10–20 hours in the studio. The recording scripts range from audio prompts to navigation directions, from canned responses to jokes. Naturally recorded speech cannot cover every possible sentence the assistant may need, so a unit selection TTS system slices the recorded speech into basic units, such as half-phones, and recombines them according to input text to create new speech. In practice, selecting and concatenating appropriate units is difficult because each unit's acoustic properties depend on neighboring units and prosody, often making units incompatible. Figure 1 shows synthesis using a database segmented into half-phones.
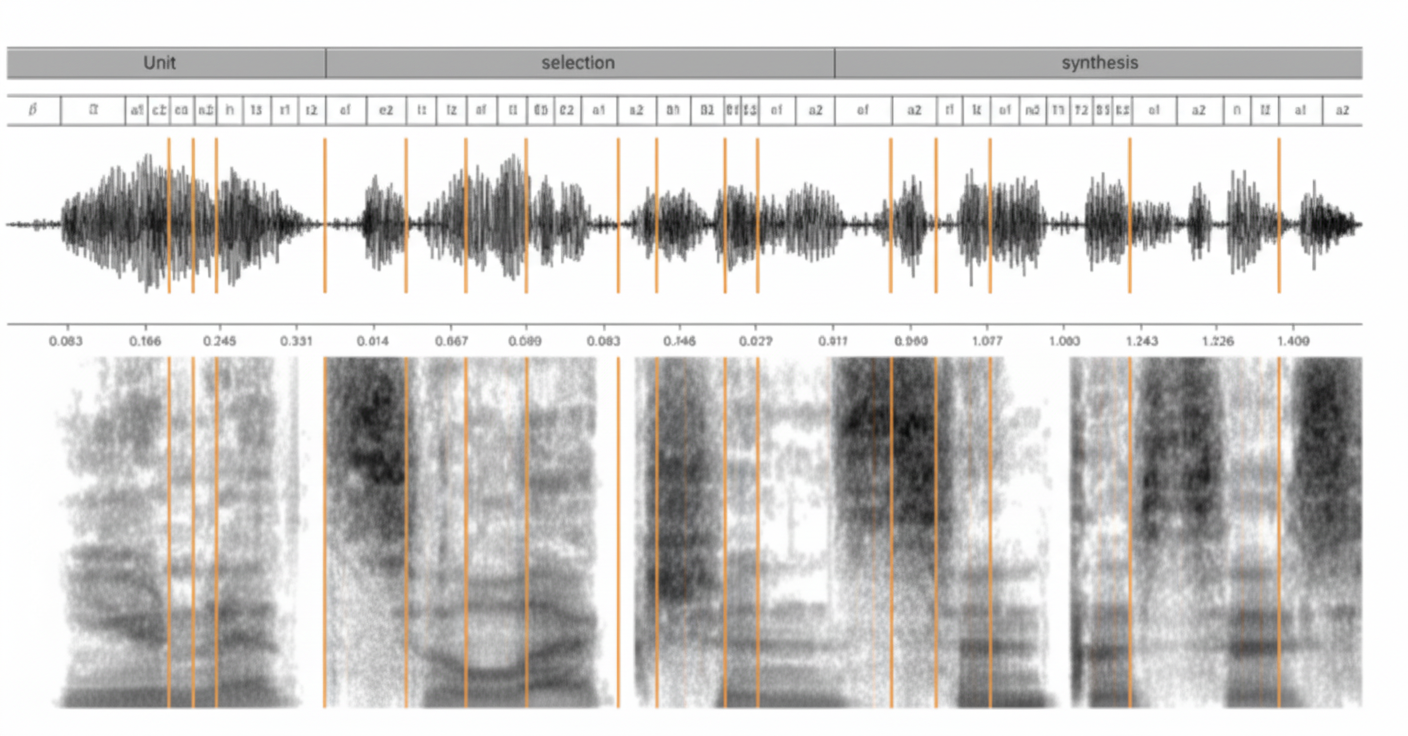
Figure 1: Unit selection synthesis using half-phones. The target utterance is "Unit selection synthesis". The top shows the phonetic transcription using half-phones. The synthesized waveform and spectrogram are shown below. Vertical divisions mark speech segments from the dataset, which may contain one or more half-phones.
The main challenge for unit selection TTS is to find a sequence of units (for example, half-phones) that both matches the input text and predicted target prosody, and can be concatenated without audible artifacts. Traditionally this process has two parts: a front end and a back end (see Figure 2), although modern systems can blur this boundary. The front end produces phonetic transcriptions and prosodic information from raw text. This includes normalizing raw text with numbers and abbreviations into words, assigning phonetic transcriptions to words, and parsing syntactic, syllable, lexical stress, and phrase boundary information. The front end is highly language dependent.
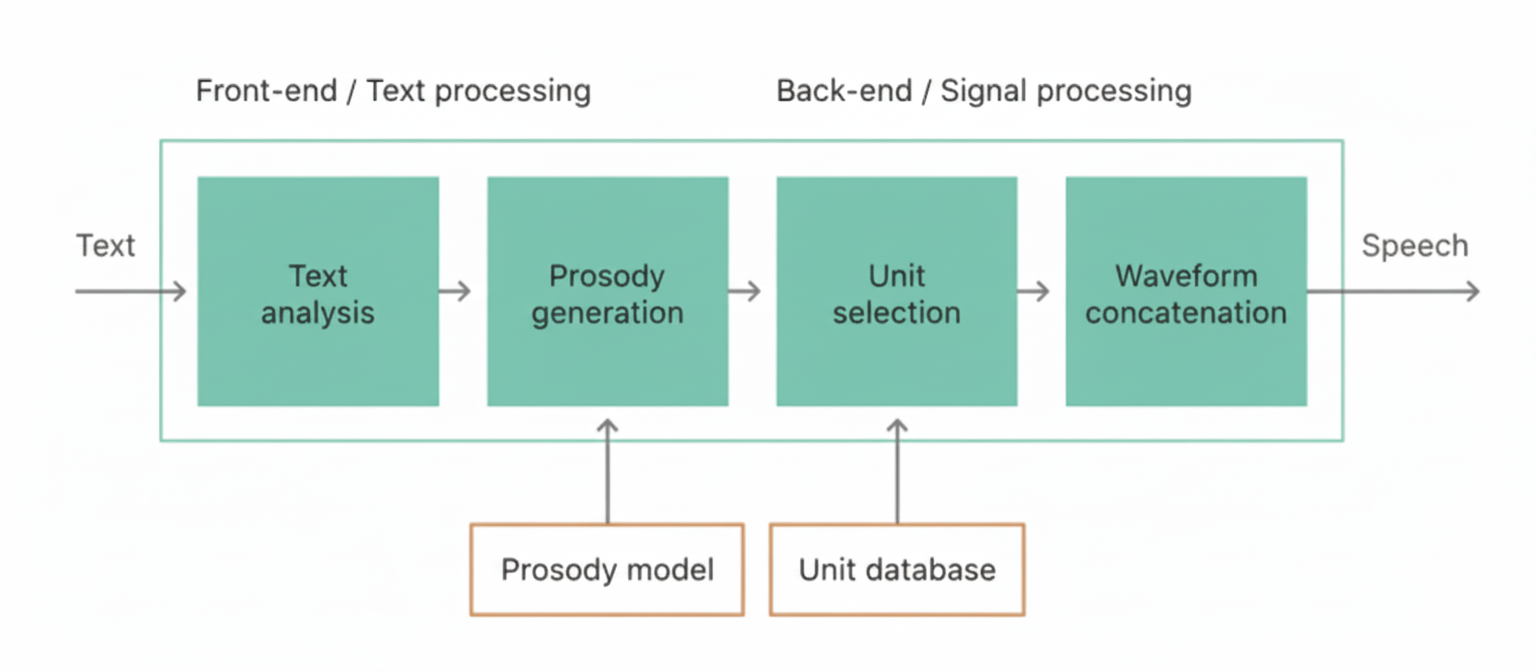
Figure 2: Text-to-speech synthesis flow.
Using symbolic linguistic representations created by the text analysis module, the prosody prediction module predicts acoustic feature values such as pitch and duration. These values are used to guide unit selection. Unit selection is a complex optimization, so modern synthesizers use machine learning to learn mappings between text and speech and to predict acoustic feature values for unseen text. This module is trained on large amounts of text and speech data. Its inputs are numeric linguistic features, such as phoneme identity, phoneme context, syllable and word position features converted into numeric form. Its outputs are numeric acoustic features of speech, such as spectral features, fundamental frequency, and phoneme durations. During synthesis, the trained statistical model maps input text features to acoustic targets, which guide the unit selection back end; matching pitch and duration is particularly important.
Unlike the front end, the back end is typically language independent. It includes unit selection and waveform concatenation. During system training, forced alignment is used to align recorded speech with script text (using an acoustic model from speech recognition) so the recordings can be segmented into individual units. A unit database is then created from the segmented speech. The database is enriched with important information, such as the linguistic context and acoustic features extracted for each unit. This collection is called the unit index. Using the unit database and predicted prosodic features, a Viterbi search is performed in speech space to find the best path for unit synthesis (see Figure 3).
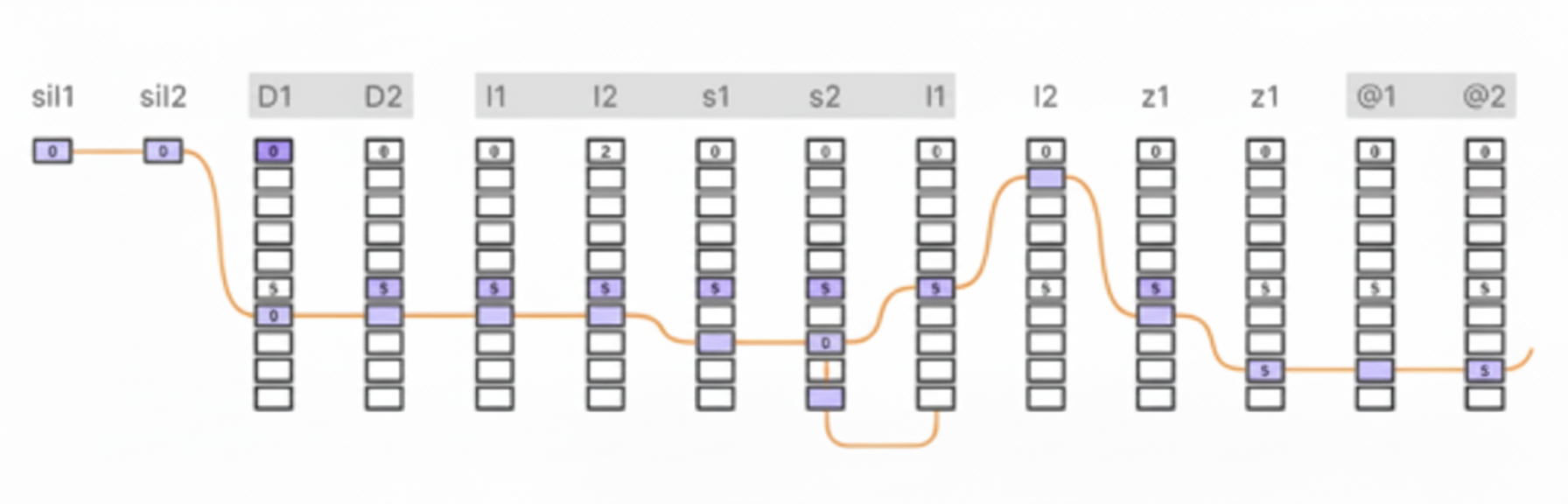
Figure 3: Viterbi search over a lattice to find the best unit concatenation path. The top shows target half-phones for synthesis; each cell below corresponds to a candidate unit from the database. The Viterbi search finds the best path that connects selected units.
The selection is based on two criteria: (1) units must follow the target prosody; and (2) units should be concatenated with no audible discontinuities at boundaries whenever possible. These criteria are called target cost and concatenation cost respectively. Target cost is the difference between predicted target acoustic features and acoustic features extracted from each candidate unit (stored in the unit index). Concatenation cost measures acoustic differences between adjacent units. The total cost is computed as:
where u_n denotes the nth unit, N denotes the number of units, and w_t and w_c are weights for target and concatenation costs. After determining the optimal sequence, unit waveforms are concatenated to create continuous synthesized speech.
Technical Details Behind Siri's New Voice
Hidden Markov models directly model distributions of acoustic parameters, so they have commonly been used for statistical prediction of targets [5][6], making it straightforward to compute target cost using functions such as KL divergence. However, deep learning methods typically outperform HMMs for parametric synthesis, so the goal was to translate deep learning advantages into hybrid unit selection synthesis.
The TTS objective for Siri is to train a single deep model that can automatically and accurately predict both target costs and concatenation costs for units in the database. Instead of HMMs, Siri uses a deep mixture density network (MDN) to predict distributions of feature values. MDNs combine conventional deep neural networks (DNNs) with Gaussian mixture models (GMMs).
A conventional DNN is a neural network with multiple hidden layers between input and output, enabling modeling of complex, nonlinear mappings between input and output features. DNNs are typically trained with backpropagation. In contrast, GMMs model output distributions using a mixture of Gaussian components and are commonly trained with expectation-maximization (EM). MDNs combine the advantages of DNNs and GMMs by using a DNN to model complex input-output relations while producing probability distributions as outputs (see Figure 5).
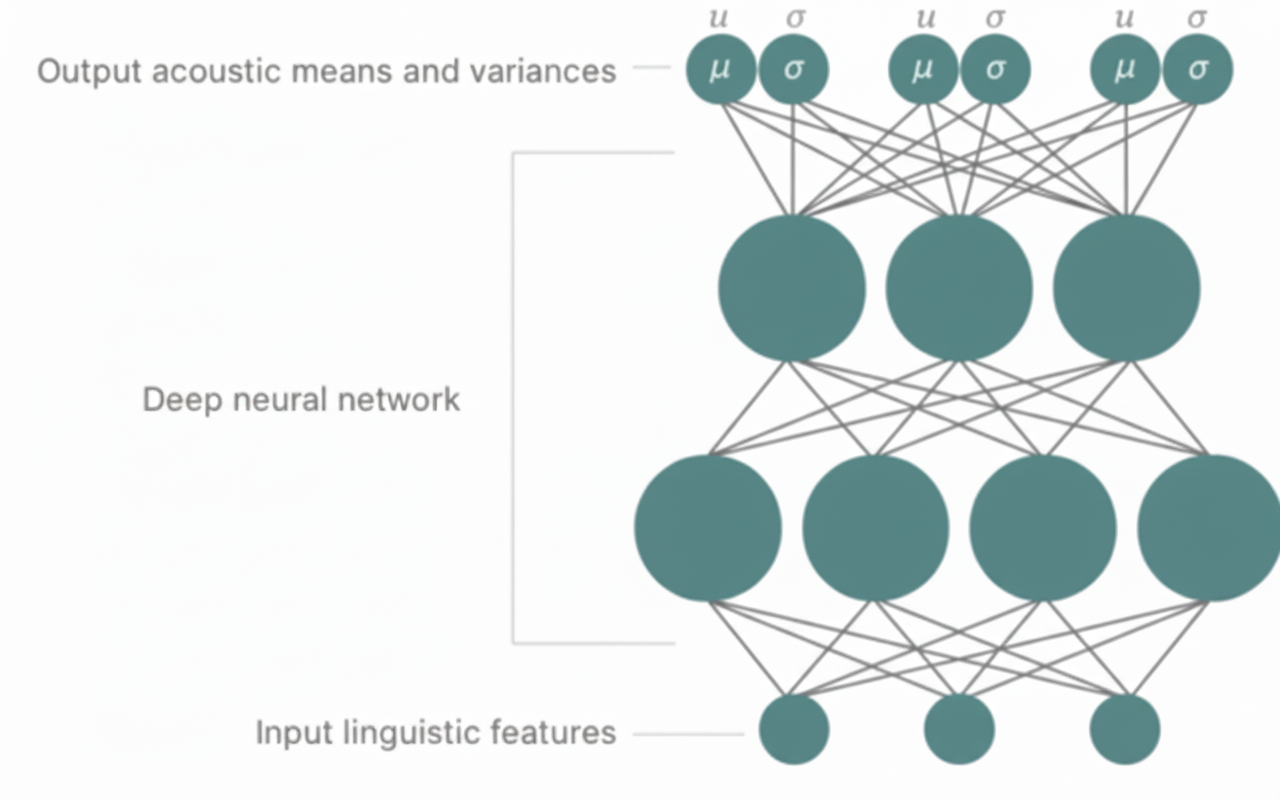
Figure 4: Deep mixture density network for modeling acoustic mean and variance. The predicted acoustic means and variances can guide unit selection synthesis.
For Siri, a unified MDN predicts prosodic target features (spectrum, pitch, and duration) and concatenation cost distributions to guide unit search. Because MDN outputs are in a Gaussian mixture form, likelihood functions can be used as loss functions for target and concatenation costs:
where x_i is the ith target feature, μ_i is the predicted mean, and σ_i^2 is the predicted variance. In practice, negative log-likelihood is used and constant terms are removed, which simplifies to a weighted loss function:
where w_i denotes per-feature weights.
Considering natural language variability, this approach has clear advantages. Some speech features, such as vowels, are stable and change slowly, while other features change rapidly, such as voiced-to-unvoiced transitions. The model must adapt parameters according to this variability. Deep MDNs embed variances that are context dependent; predicted variances act as automatic, context-dependent weights for costs. This is important for synthesis quality because target and concatenation costs should be computed under the current contextual conditions:
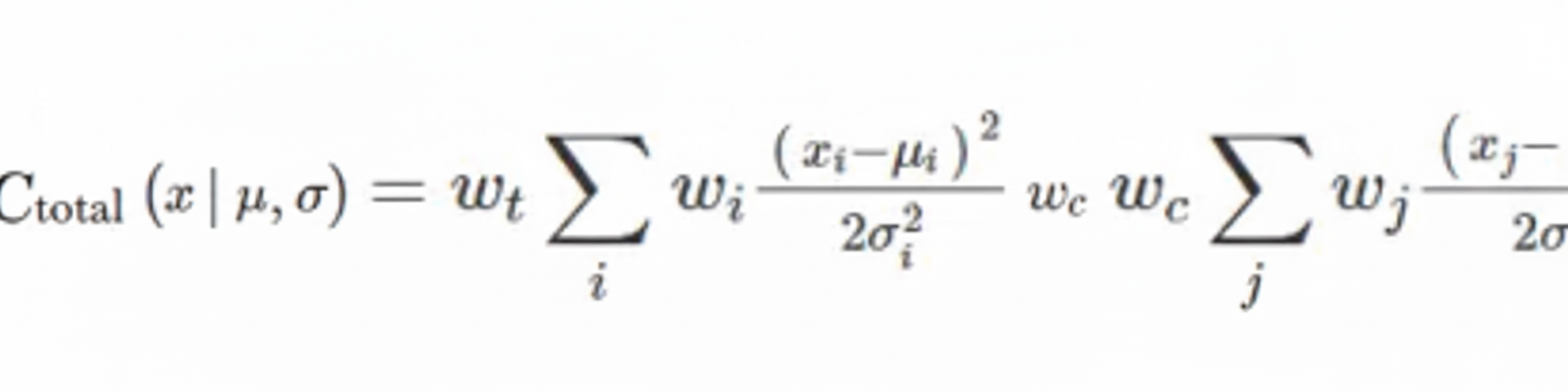
where w_t and w_c are weights for target and concatenation costs. The target cost term ensures reproduction of prosody (pitch and duration) in synthesized speech, while the concatenation cost term enforces smooth prosody and seamless concatenation.
After scoring units with the deep MDN-derived total cost, a traditional Viterbi search finds the optimal unit path. The waveform similarity overlap-add algorithm (WSOLA) is then used to find optimal splice points, generating smooth and continuous synthesized speech.