0. Notes
Visual and lidar sensing both face the challenge of removing the influence of moving objects. The tasks are twofold: detect dynamic objects and update a static environment map that excludes those objects. Existing methods for removing dynamic objects often struggle with false positives and false negatives in segmentation results, which raises the classic question of how much to trust deep learning outputs. The paper introduced below addresses this issue by feeding both the current LiDAR scan and a local map into a network to correct missed detections and false detections in historical frames. MOS is used below as an abbreviation for Moving Object Segmentation.
1. Results Overview
The method takes LiDAR point clouds as input and classifies points as dynamic or non-dynamic. It also constructs a Volumetric Belief map that stores the probability that each region contains dynamic objects. Once the map is built, queries can determine whether specific points are likely dynamic. A key capability is correcting false positives and false negatives in past frames, which many algorithms do not address.
The mapping result in dynamic scenes shows residual traces of dynamic objects in solid circles and static regions removed by the method due to false positives in dashed circles. Overall, the resulting dynamic environment map appears cleaner.
2. Abstract
Mobile robots navigating unknown environments must continually perceive dynamic objects for mapping, localization, and planning. Inferring moving objects in current observations while updating an internal model of the static world is critical for safety. This work addresses joint estimation of moving objects from the current 3D LiDAR scan and a local environment map. Sparse 4D convolutions extract spatiotemporal features from both the scan and the local map, and all 3D points are segmented into moving and non-moving categories. The method fuses these predictions into a probabilistic representation of the dynamic environment using a Bayesian filter. The Volumetric Belief model represents which parts of the environment can be occupied by moving objects. Experiments show the method outperforms existing MOS baselines and can generalize across different LiDAR sensors. In online mapping scenarios, the Volumetric Belief fusion improves MOS precision and recall and can recover previously lost moving objects.
3. Algorithm Details
The overall objective is to identify dynamic objects in the current LiDAR scan and local map and to fuse predictions into a probabilistic Volumetric Belief map.
Incoming LiDAR scans are first registered using KISS-ICP and voxelized before segmentation. The Scan2Map input consists of 4D information (position plus timestamp) from the current LiDAR scan and the local map, without requiring poses. A 4D convolutional network, MinkUNet, predicts moving objects, and the predictions are fused into the Volumetric Belief map. The segmentation uses two key observations:
- There are differences between LiDAR scans of moving objects and the local map.
- Timestamp patterns of points on moving objects differ from those of static points.
Why include time information? Due to occlusion and limited FoV, moving objects may be occluded for short periods; fixed-length sliding windows cannot handle this well. The approach normalizes timestamps across the sequence to avoid overfitting to a particular sequence length during training.
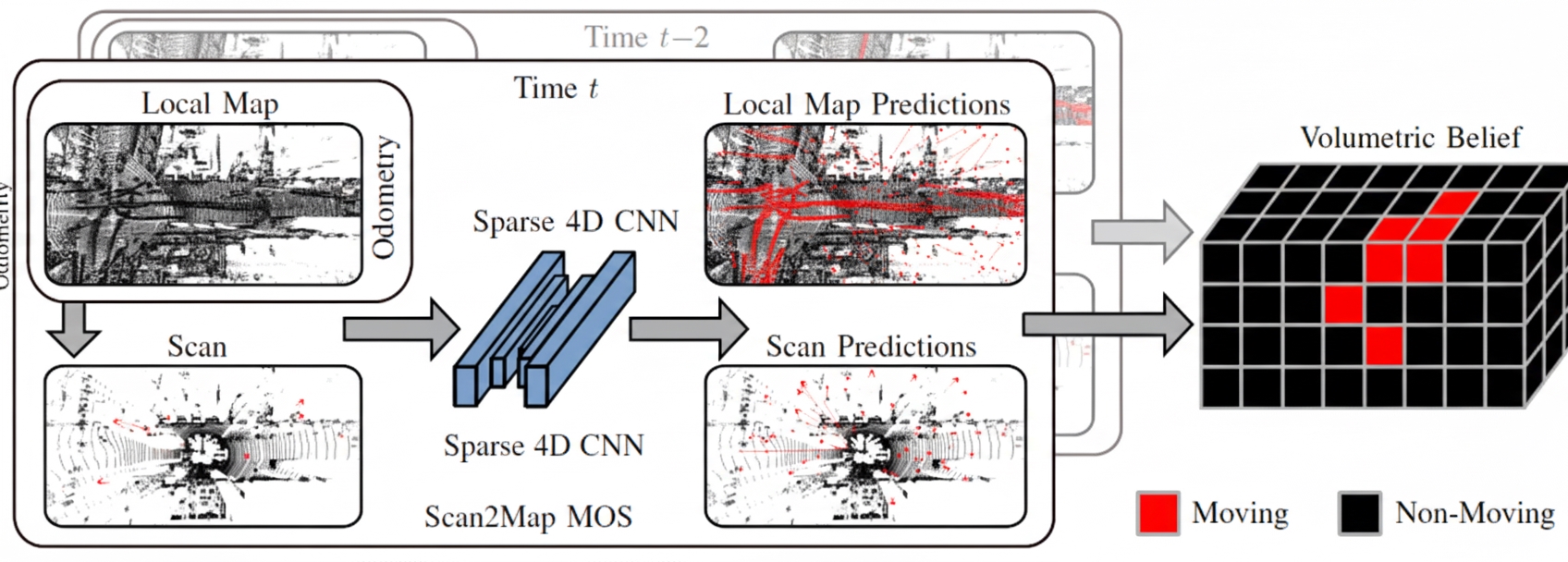
Why input the local map rather than only the current scan? This addresses false negatives and false positives in segmentation. If previous frames failed to identify a dynamic object, the local map enables retrospective correction.
The Volumetric Belief fuses multiple independent predictions over time. Importantly, the Volumetric Belief stores not per-point predictions but the probability that parts of the environment contain dynamic objects. In other words, it identifies which map regions are likely to have been occupied by moving objects (dynamic occupancy). For example, if a point falls into a dynamic voxel, the point is treated as dynamic; if a voxel is occupied by static points, the voxel is not expected to contain moving objects. Once the Volumetric Belief is built, one can query the probability that a given point is dynamic.
4. Experiments
The experiments address four questions:
- Can input LiDAR scans be accurately segmented into dynamic and non-dynamic objects using a local map built from past observations?
- Can the method achieve state-of-the-art performance while generalizing to new environments and sensor setups?
- Does fusing multiple predictions into the Volumetric Belief improve MOS precision and recall?
- Can the Volumetric Belief help recover from incorrect predictions during online mapping?
Datasets used include Semantic KITTI and Semantic KITTI MOS, and annotated subsequences from KITTI Tracking, Apollo Columbia Park MapData, and nuScenes. The evaluation metric is IoU, standard for segmentation tasks.
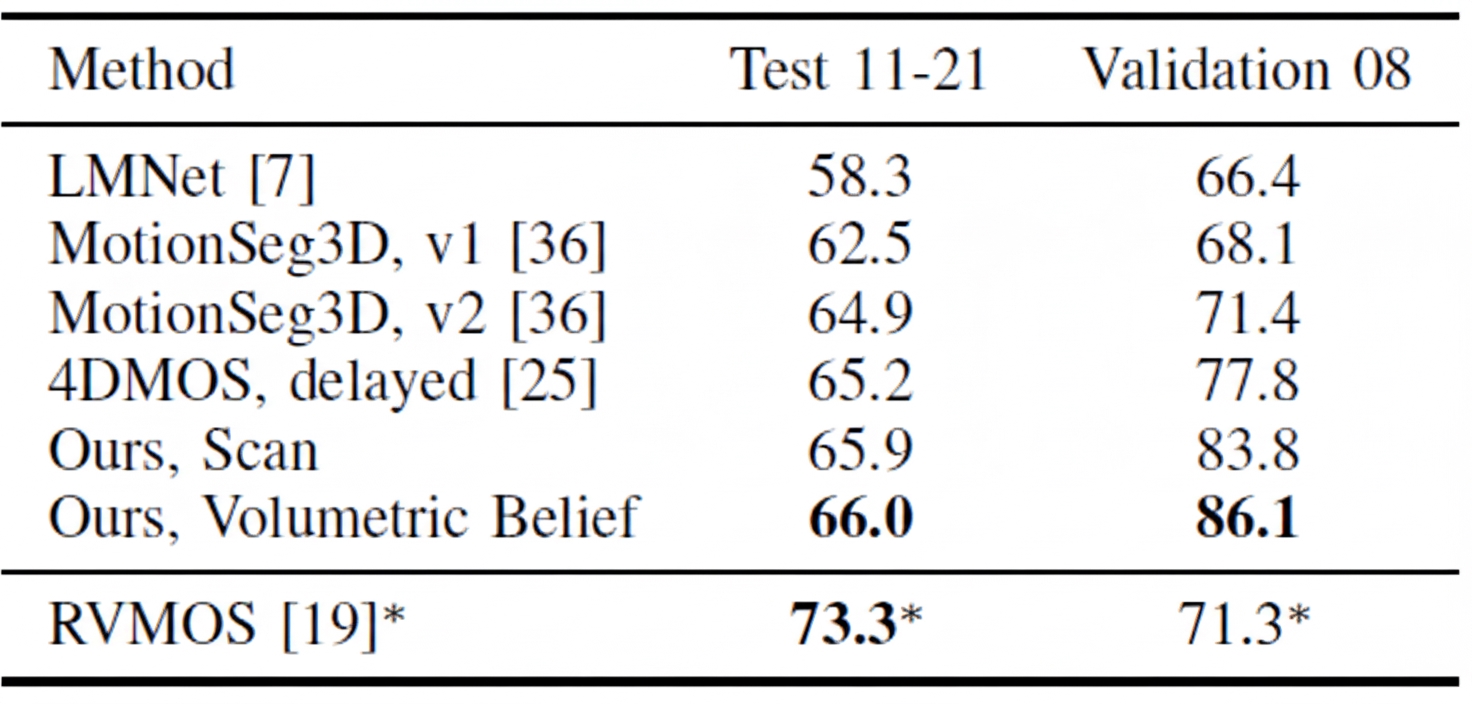
Results on Semantic KITTI and Semantic KITTI MOS compare using only the current frame (Scan) versus using a 10-frame local map (Volumetric Belief). Validation set results are strong; test set improvements are less pronounced. The improvement over 4DMOS demonstrates that using time information benefits MOS. LMNet refers to a prior method by the same author. RVMOS shows strong performance when trained with extra labels.
Generalization experiments are important because MOS is a supervised task with high labeling cost. LMNet and MotionSeg3D perform poorly when overfitted to lidar mounting and point intensity. Methods using only time information, such as 4DMOS and the method discussed here, adapt better to different LiDAR calibrations.
The final experiment shows how Volumetric Belief settings affect IoU, recall, and precision. "No Delay" indicates that points from the local map are treated as dynamic points for runtime balance. Results indicate Volumetric Belief can exclude false positives from the prior map. While precision and recall can vary, IoU improvement is significant.
5. Conclusion
Compared with dynamic visual SLAM, dynamic LiDAR SLAM still has many research directions. The core idea remains exploiting contradictions between scans and between scan and map. Such contradictions can be used directly as geometric consistency checks or fed into a network for learning. From this perspective, readers can design new discriminators and new dynamic point cloud detection algorithms.


