Overview
This article summarizes a floating-point (FP) quantization approach for compressing large language models. Post-training quantization (PTQ) is a common method, but most existing PTQ techniques use integer (INT) quantization and suffer large accuracy drops when bit width falls below 8. Compared with INT quantization, FP quantization can better represent long-tail distributions, and an increasing number of hardware platforms support FP quantization. This article describes an FP quantization solution published at EMNLP 2023.
Floating Point Format
A floating point number is represented by sign, exponent, and mantissa fields. The usual notation uses s for the sign bit, m for mantissa bits, and e for exponent bits. The variable p ranges from 0 to 2^e - 1 and indicates the exponent interval. The variable d takes values 0 or 1 and denotes the i-th mantissa bit. The value b is the exponent bias, an integer used to shift the exponent range.
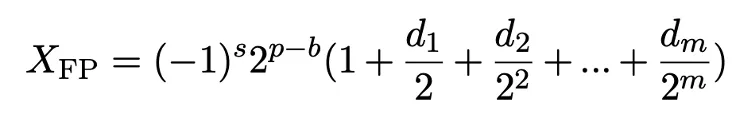
Floating Point Quantization Workflow
FP quantization first applies a scale-and-clip step: inputs are clipped to the maximum range representable by the target FP format (±Qmax) and scaled accordingly. Similar to integer quantization, FP quantization uses a full-precision scaling factor to map inputs into the representable range. During matrix multiplication, the scaling factors are handled separately from the low-bit matrix operations, so they do not introduce large overhead.
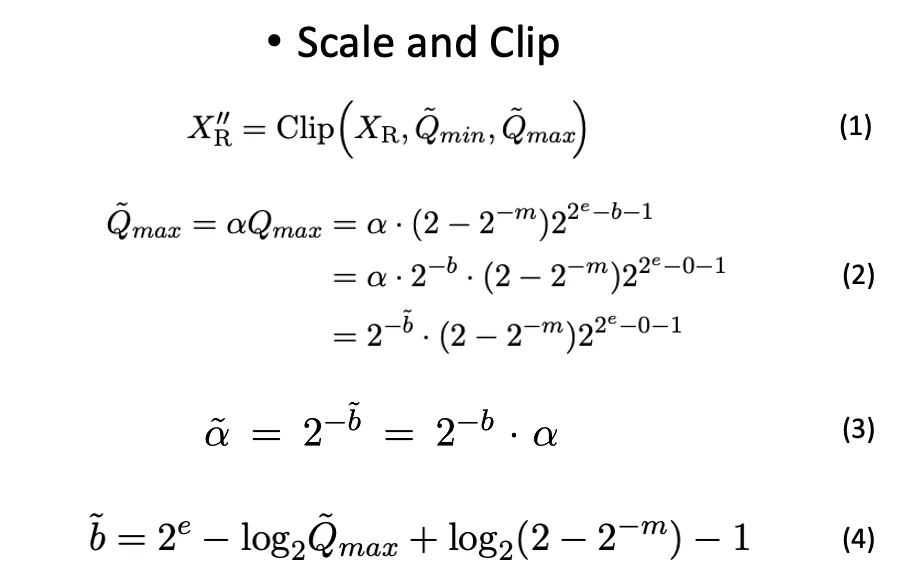
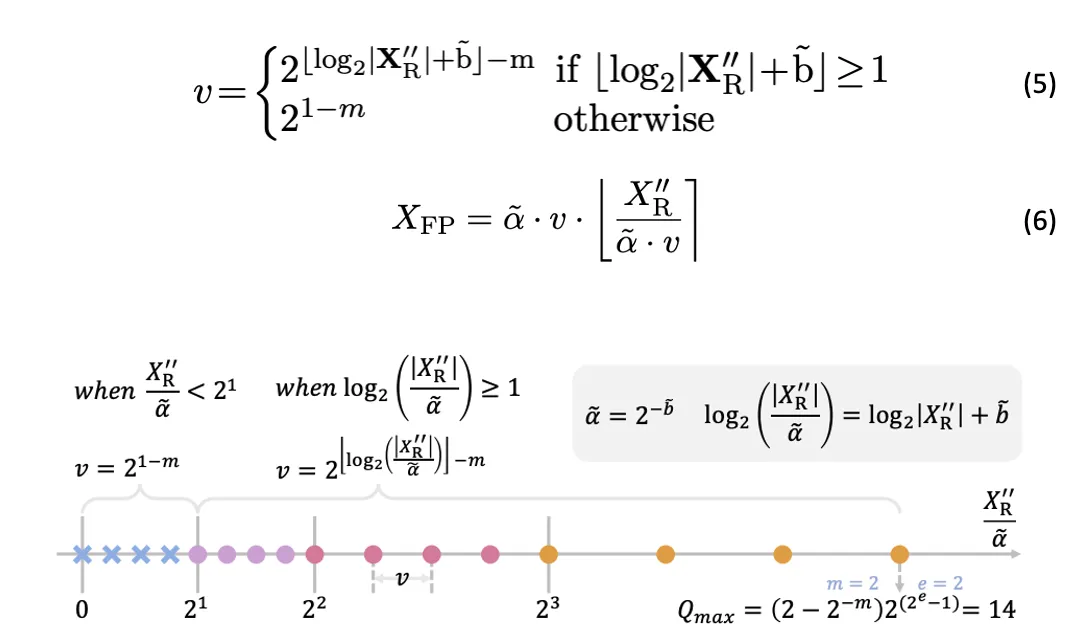
After determining the required quantization range based on the input tensor dynamic range and deriving the corresponding bias (see formula 4 in the original paper), values within the range are mapped to discrete FP quantized levels in a compare-and-quantize step.
Efficient Matrix Multiplication with FP Quantized Tensors
With quantized activations and weights, the precomputed full-precision scaling factors enable efficient matrix multiplication and acceleration. The scaling factors allow different quantized tensors to be clipped to different min/max ranges while keeping matrix operations efficient.
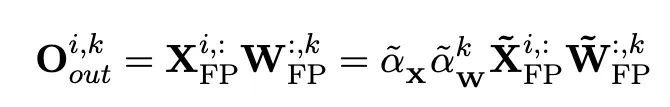
Impact of FP Format Choice
The accuracy of FP quantization depends strongly on the choice of exponent and mantissa bit widths and on the selected quantization intervals. Different FP formats show large differences in quantization error; with the right FP format, FP quantization can better represent long-tail distributions than INT quantization. This behavior has been observed in prior work as well.
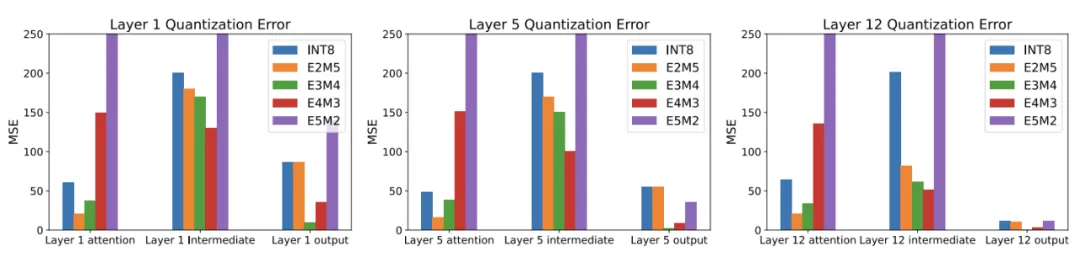
Channel-Level Activation Imbalance
Another challenge that affects quantization is large magnitude differences between channels in activation tensors: activations across different channels can vary by orders of magnitude, while values within the same channel are relatively consistent. Similar observations were reported in prior studies, but the paper highlights that this phenomenon appears across diverse Transformer models such as BERT, LLaMA, and ViT.
Outlier channels with much larger magnitudes dominate the quantization range, restricting the quantization intervals for other channels and degrading overall quantization accuracy. This effect can cause quantized models to fail, particularly at low bit widths.
Maintaining Efficiency: Tensor-wise vs Channel-wise Quantization
Only tensor-wise and token-wise quantization allow extraction of the scaling factor for efficient matrix multiplication; channel-wise quantization does not support the same efficient matrix multiplication pattern. To address channel-level imbalance while preserving efficient matrix multiplication, the paper uses a small calibration dataset to compute the maximum value per activation channel, then derives per-channel scaling factors.
The per-channel scaling factor is decomposed into a per-tensor real multiplier times a per-channel power-of-two factor. The integer power-of-two component is represented by the FP exponent bias. The decomposition can be expressed as follows.
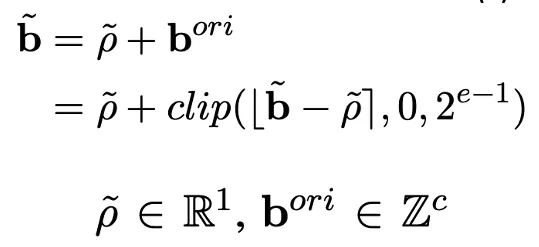
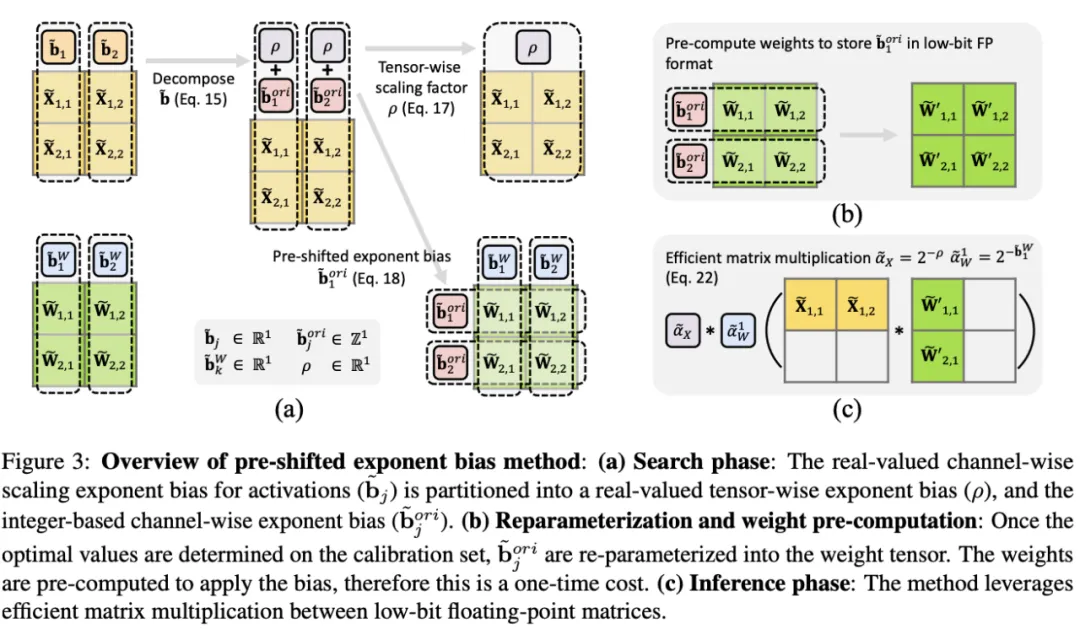
Pre-shifted Exponent Bias
After calibration, the per-channel exponent bias is fixed and can be precomputed along with weight quantization. By incorporating the per-channel exponent bias into the quantized weights, the original full-precision per-channel biases from activations become a single tensor-wise real scaling factor, while the integer per-channel biases are moved into the weight representation. This pre-shifted exponent bias method improves quantization accuracy while preserving efficient matrix multiplication.

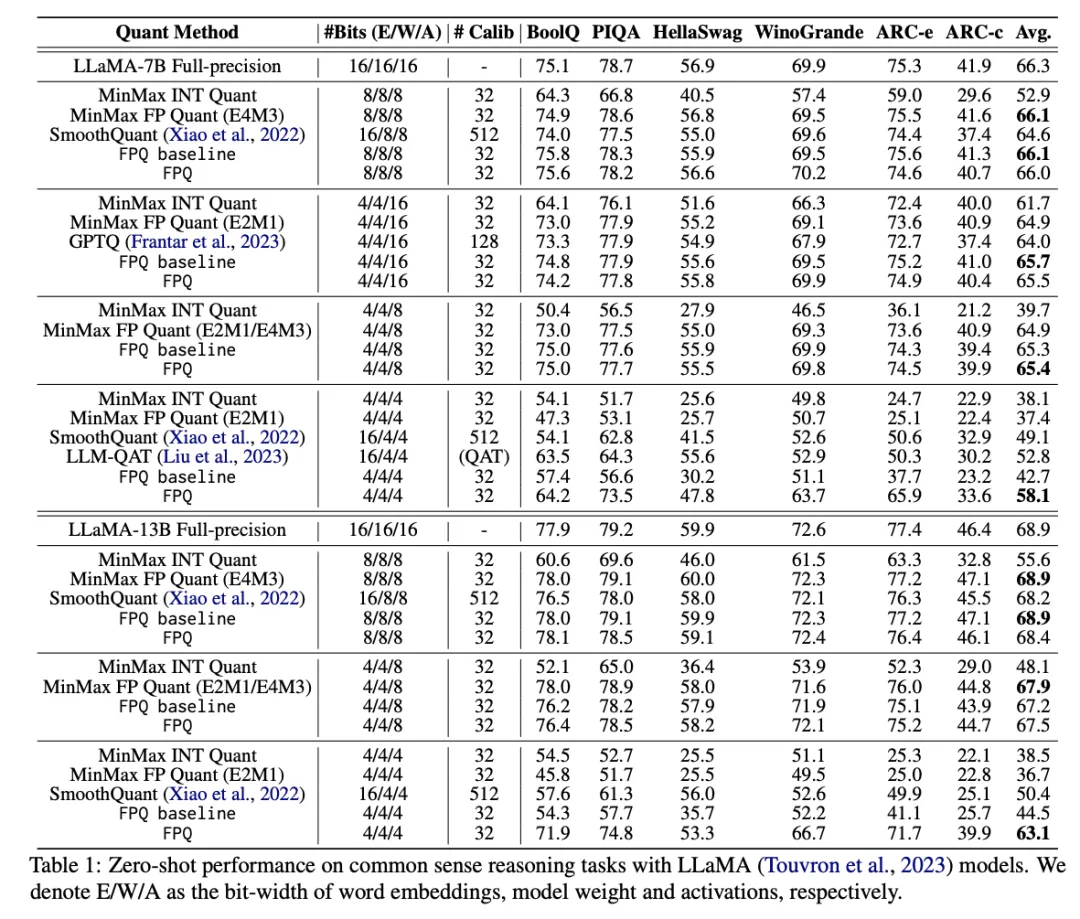
Results
The paper demonstrates that Floating Point Quantization (FPQ) achieves strong results on LLaMA, BERT, and ViT models at 4-bit precision, outperforming prior state of the art. Notably, a 4-bit quantized LLaMA-13B model reaches an average zero-shot score of 63.1, only 5.8 points below the full-precision model and 12.7 points higher than the previous best method on the same evaluation. This represents one of the few practical 4-bit quantization solutions for large models to date.