With the development of internet technologies, network applications have become increasingly complex, evolving from traditional Web and email services to a wide range of P2P applications and custom business protocols. Identifying application-layer protocols within network traffic is an important task in network management. Traditional pattern matching and handcrafted feature extraction methods face limitations when dealing with diverse and complex application protocols. Recently, large language models from the field of artificial intelligence have opened new opportunities for protocol identification. By pretraining on large corpora, these models acquire deep language understanding that can be applied to semantic analysis of network traffic.
Specifically, large language models can interpret application-layer protocol semantics in traffic, recognize formats of common protocols such as HTTP and DNS, and detect anomalies in uncommon protocols. The knowledge learned by these models also supports zero-shot and few-shot learning, enabling recognition of novel or low-sample protocols. Recent industry research has demonstrated promising results for large language models in protocol identification, including systems built on RoBERTa and BERT variants that achieve high accuracy. These findings indicate the potential of large language models in this area.
Part 1 — What Is Application Protocol Identification
Application protocol identification refers to methods for recognizing which application-layer protocol is used by network traffic. Internet applications communicate using application-layer protocols: for example, HTTP for web browsing and DNS for domain name resolution. Automated identification of the protocol used by traffic is required for traffic management, monitoring, and security.
Common approaches to protocol identification include:
- Port-based identification: Determine protocol by sampling port numbers (for example, port 80 often indicates HTTP). This method has clear limitations.
- Pattern matching: Match protocol-specific byte patterns within payloads.
- Statistical analysis: Extract traffic statistical features and apply machine learning methods to classify protocols.
- Deep learning: Use LSTM, CNN, or other end-to-end deep networks to automatically extract features from traffic.
- Grammar parsing: Parse application-layer data and infer the protocol syntax.
- Semantic analysis: Apply large language models to analyze application-layer semantics and identify protocol meaning.
Protocol identification is essential for traffic monitoring and security. As applications grow in complexity, more intelligent and efficient identification techniques become increasingly important.
Part 2 — Characteristics of Large Language Models
Large language models have several key characteristics: (1) strong semantic understanding, (2) powerful transfer learning capability, and (3) flexible deployment forms.
(1) Strong semantic understanding
Pretrained language models can deeply understand context and semantic relationships, including vocabulary, grammar, and commonsense knowledge. This enables complex semantic analysis and advanced language processing tasks.
(2) Transfer learning capability
Knowledge acquired during pretraining is broadly applicable and can be transferred to downstream tasks. Even when downstream data is limited, pretrained models often achieve good results, enabling application to diverse domains.
(3) Diverse deployment forms
Large language models can be integrated in different ways: fine-tuning for classification or sentence matching; using the encoder to extract semantic features; or generating text. This flexibility supports a wide range of natural language processing applications.
Part 3 — Data Structures and Core Mechanisms
Large language models combine several specialized data structures to model human language capabilities. They use embeddings to transform tokens into numeric vectors. Attention mechanisms allow tokens to interact and convey contextual information. Deep networks extract semantic features, residual connections preserve information across layers, positional encodings provide order information, and masked language modeling enables self-supervised learning. Hundreds of millions or billions of parameters help the model memorize knowledge. Together, these components form a system capable of deep language understanding and generation.
Key components and their roles:
- Embedding layer: maps token symbols to dense vector representations.
- Multi-head attention: allows the model to attend to different positions in the text simultaneously.
- Feed-forward networks: perform semantic feature extraction after attention layers.
- Residual connections: add previous layer outputs to current outputs to alleviate vanishing gradients.
- Layer normalization: stabilizes and accelerates training in deep networks.
- Positional encoding: provides word order information to the model.
- Mask mechanism: hides parts of the input during pretraining to enable self-supervised learning.
- Weight matrices: compute attention scores and linear transformations, consuming significant storage and computation.
The operational principle of a large language model can be summarized as follows:
First, the input text sequence is converted into numeric token vectors using an embedding layer. These vectors are then fed into a stack of Transformer modules in an encoder structure. Inside each Transformer, multi-head attention allows token vectors to interact and compute pairwise relevance, learning contextual semantics.
Next, a feed-forward network extracts features and transforms representations. Techniques such as residual connections and layer normalization enable deep model training. Positional encodings inject sequence order information. Large parameter counts support complex semantic computations. During pretraining, self-supervised objectives such as masked language modeling teach general language knowledge. During fine-tuning, supervised learning adapts the pretrained representation to specific downstream tasks. This pretrain-then-finetune workflow yields strong semantic understanding and generation capabilities, mimicking how humans learn language and then apply it.
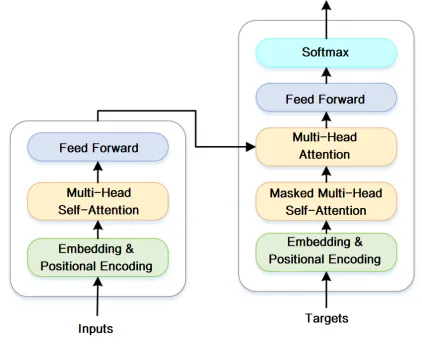
Figure: Core module operation of a large language model
Various data sources are ingested into the data platform layer via Kafka. The data platform stores detailed records in ClickHouse, with retention periods configured per business requirements. ClickHouse materialized views can produce pre-aggregated data by common report dimensions to improve query performance. Periodic tasks in the data service layer query ClickHouse pre-aggregations to produce display data and store results in MySQL. The reporting service serves queries from the data presentation layer by reading MySQL, ensuring query efficiency and concurrency.
Part 4 — Applying Large Language Models to Protocol Identification
Large language models' language understanding and modeling capabilities make them suitable for application protocol identification.
The protocol identification task determines the application-layer protocol category for captured network messages. Compared with rule-based methods, model-based approaches offer greater adaptability and extensibility.
A typical workflow for applying large language models to protocol identification includes:
(1) Data preprocessing: Collect large-scale protocol message datasets, such as HTTP and DNS messages, clean the data, and extract pure protocol corpora.
(2) Build a protocol vocabulary: Convert messages into numeric ID sequences via a vocabulary for model input. Pretrain a language model on the processed dataset to learn general protocol semantic features. Common pretraining bases include BERT variants. Pretraining with masked tokens and other techniques helps the model learn protocol-specific patterns.
(3) Fine-tune the model for protocol classification: Create a classifier that maps protocol messages to protocol categories. Use labeled protocol messages for supervised training and optimize parameters via backpropagation until the model can accurately classify messages.
(4) Deploy the fine-tuned model: Export the trained model and integrate it into an online network traffic analysis system. In production, capture real-time traffic, extract protocol messages, and feed them to the deployed model to perform online intelligent protocol analysis.
This workflow leverages transfer learning: pretrain on large unlabeled corpora to learn general representations, then quickly adapt to downstream tasks. Compared with training models from scratch, this approach reduces manual feature engineering and dependency on large task-specific labeled datasets, while improving generalization.
In summary, the pretrain-and-finetune paradigm enables large language models to efficiently adapt to specialized tasks such as protocol identification. By learning semantics from large unlabeled corpora and then transferring that knowledge, these models provide a general technical route for solving domain-specific language understanding problems.
As described above, various data sources are ingested through Kafka into a data platform. Detailed records are stored in ClickHouse with configurable retention. ClickHouse materialized views provide pre-aggregations for common reporting dimensions. Periodic tasks in the data service layer query these pre-aggregations to populate MySQL with report-ready data. The reporting service queries MySQL for efficient, concurrent access by the data presentation layer.
Part 5 — Conclusion and Outlook
In summary, large language models following a pretrain-then-finetune framework can learn general semantic representations from large protocol corpora and transfer them to specific protocol identification tasks, enabling intelligent parsing of network traffic. Compared with rule-based methods, this approach improves adaptability and extensibility.
Future research directions include: (1) building larger cross-protocol pretraining corpora to strengthen protocol language understanding; (2) exploring alternative architectures such as encoder-decoder models like BART to improve modeling; (3) using multi-task learning to jointly train related tasks such as protocol semantic parsing and share knowledge; (4) online incremental learning to allow deployed models to update as new protocols emerge; (5) model compression techniques to deploy lightweight and efficient protocol identification engines; and (6) enhancing interpretability and security to increase transparency and control in model decisions. As models and data scale, large language models will continue to improve protocol understanding and play an important role in network analysis tasks.
References:
[1] Introduction to large natural language models, 2023-04-01







