Introduction
Artificial intelligence is now more than a topic for chips and system design; it is being tasked with increasingly complex functions that have become competitive requirements across many markets. The addition of machine learning and deep learning brings broad disruption and uncertainty to many aspects of electronic products. This is partly because AI involves many different devices and processes and partly because AI itself is evolving rapidly.
Scope and Common Goals
AI spans everything from training algorithms to inference. It includes large-scale training programs as well as tinyML algorithms that can run on micro IoT devices. AI is increasingly used in many aspects of chip design and in fabs to correlate manufacturing, inspection, metrology, and test data from those chips. It is even used in the field to identify failure modes that can feed back into future design and manufacturing.
Across this broad set of applications and technologies, several common objectives emerge:
- Reduce the energy required for AI/ML/DL computation;
- Obtain results faster, which requires greater parallelism and throughput and fundamental architecture changes in both hardware and software;
- Improve result accuracy, which affects power and performance;
- Increase overall efficiency.
For any AI style or application, performance per watt or per operation is a key metric. Energy must be generated and stored to perform AI/ML/DL computation, and there are associated costs in terms of resources, utilities, and area.
Training, Sparsity, and Adaptive Compute
Training algorithms typically involve massive parallelization of multiply-accumulate operations. Efficiency comes from elasticity in compute elements within hyperscale data centers—being able to scale compute up when needed and reallocate it when not—and from smarter use of those resources combined with increasingly fine-grained sparse models.
Google Chief Scientist Jeff Dean identified three trends in machine learning: sparsity, adaptive compute, and dynamically changing neural networks. "Dense models activate the entire model for each input example or each generated token," he explained at a recent Hot Chips presentation. "While they are great and have achieved important results, sparse computation will become a future trend. Sparse models have different paths that can be adaptively invoked as needed."
People are beginning to realize that sparse models can be partitioned more intelligently across processing elements. "Spending the same amount of computation on every example does not make sense, because some examples can be 100 times harder than others," Dean said. "So we should spend 100 times the computation on the really difficult items, while most items are very simple."
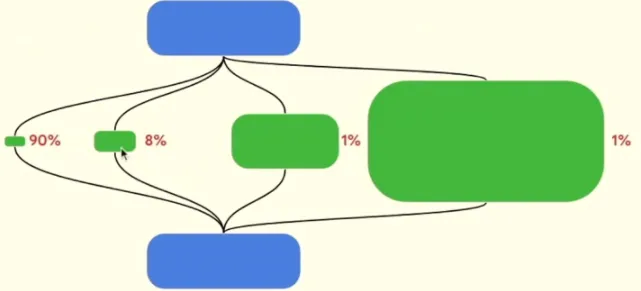
Figure 1: Adaptive compute with granular sparsity. Source: Google/Hot Chips 2023
Abstraction and Local/System-Level Tradeoffs
Edge resource and compute models differ significantly, but the same basic principles of abstraction, customization, and scaling apply. Abstraction focuses on local and system-level tradeoffs. For example, some elements of processors or accelerators can be hardwired while providing enough flexibility to integrate future changes. This is especially useful when a device may be used for multiple applications and the chip's expected lifetime justifies a degree of programmability. This approach resembles how some analog IP for advanced-node SoCs is developed, where much of the architecture is digital.
Cheng Wang, CTO and cofounder of Flex Logix, noted that the memory and data paths feeding into and out of those hardwired blocks must support the permutations required by AI workloads, since access patterns can be somewhat irregular. "It is also common in AI to add offsets or scale factors to data before feeding it into an engine. Of course the engine is hardwired, but outputs must pass through flexible activation functions and be routed to SRAM or DRAM or both depending on workload demands. All that flexibility is necessary to keep MAC efficiency. If your memory bandwidth is insufficient, you must stall; in that case, the speed of the MACs does not matter. If you are stalled, you run at the speed of memory, not the speed of the compute."
Right-Sizing Memory and Interfaces
For similar reasons, memory architectures are evolving. "AI is increasingly used to extract meaningful data and monetize it," said Steven Woo, researcher and distinguished inventor at Rambus. "It demands very fast memory and fast interfaces, not just in servers but also for accelerators. We see relentless demand for faster memory and interconnects, and we expect that trend to continue. The industry is responding. Data centers are evolving to support data-driven applications such as AI and other server workloads. As we transition from DDR4 to DDR5, the main memory roadmap is shifting, and new technologies like CXL are entering the market as data centers evolve from dedicated resources to pooled resources."
The same trend is redefining the edge. "Chipset vendors are working with chip development teams to view performance and power from a system perspective," said C.S. Lin, a market lead at Winbond. "So for a product like this, what bandwidth do you need? What process node does the SoC need, and what memory? For example, these elements must be paired to achieve speeds such as 32 Gb per second (for NVMe PCIe Gen 3). To do that, you may need an on-chip protocol that only the most advanced process nodes can provide."
Whether in the cloud or at the edge, AI applications increasingly require customization and right-sizing. Today, most algorithm training occurs in large data centers where the number of MACs can scale and computation can be partitioned among different elements. As algorithms become more mature, sparser, and increasingly personalized, that pattern may change. But for now, most of the computing world will use these AI algorithms primarily for inference.
"By 2025, about 75% of data will come from the network edge and endpoints," said Sailesh Chittipeddi, executive vice president at Renesas Electronics, in a SEMICON West panel. "The ability to predict what happens at the edge and endpoints has enormous impact. When you think about compute, you think about microcontrollers, microprocessors, CPUs, and GPUs. The latest buzz is about GPUs and what is happening with GPT-3 and GPT-4. But those are large language models. For most datasets, you do not need such massive compute."
Edge Challenges
One challenge at the edge is quickly discarding unnecessary data, retaining what is needed, and processing it faster. "When AI is at the edge, it interacts with sensors," said Sharad Chole, chief scientist and cofounder at Ereb. "Data is generated in real time and needs processing. How sensor data is ingested and the speed at which an AI NPU processes it affects buffering requirements, bandwidth needs, and overall latency. The goal is always as low latency as possible. That means the latency from sensor input to output should be minimized; the output may go to an application processor for further post-processing. We must ensure deterministic delivery of this data."
The Cost of Accuracy
Across AI applications, performance measures how quickly results are obtained. AI systems typically partition computation across MAC elements to run in parallel and then collect and combine results as fast as possible. The shorter the time to result, the more energy is required, which is why there is so much focus on customizing processing elements and architectures.
Generally, more compute elements are needed to produce more accurate results in less time. That depends to some extent on data quality, which must be good, relevant, and properly trained for the task. General-purpose processors and algorithms are less efficient. In many end applications, AI deployment may be constrained by the overall system design.
Architecture-level improvements are a mature field, and new tradeoffs are emerging. For example, Magnus Bruce, chief CPU architect and researcher at Arm, said that Arm created the Neoverse V2 platform for cloud, high-performance computing, and AI/ML workloads. In a Hot Chips presentation he emphasized separating branch prediction from fetch to improve performance in the branch predictor pipeline and included advanced prefetching with accuracy monitoring. The goal is finer-grained prediction of the chip's next actions and shorter recovery time on misprediction.
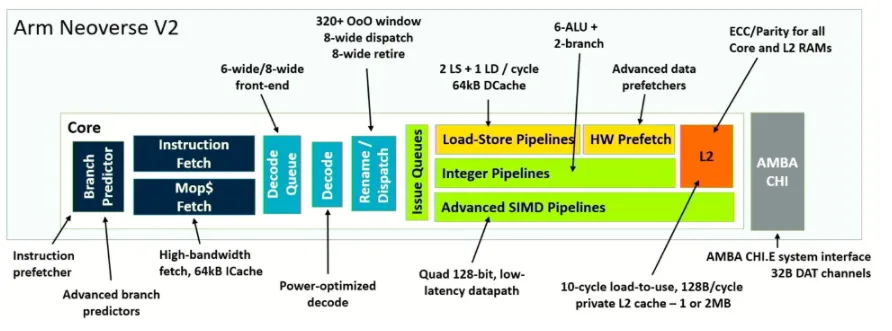
Figure 2: Architectural and microarchitectural efficiency via precision improvements. Source: Arm/Hot Chips 2023
Using AI to Improve Design
Beyond architecture changes, AI can help improve and accelerate hardware design. "Fundamental metrics customers care about remain power, performance, area, and schedule," said Shankar Krishnamoorthy, general manager of Synopsys' EDA division. "What has changed is that engineering cost has risen sharply because of workload complexity, design complexity, and verification complexity. Some customers tell us it is four times the work. They cannot simply add 10% or 20% more engineers. This is where AI becomes essential and has been a major disruptor in helping address that gap."
Others agree. "AI/ML is a hot topic, but which markets does it change and which markets did we not expect it to disrupt? EDA is a good example," said Steve Roddy, marketing vice president at Quadric. "The core of classical synthesis/place-and-route is transforming one abstraction to another. Historically this was done with heuristics and compiler-like generators. Suddenly, if you can use machine learning algorithms to speed up or get better results, you disrupt the industry. Will machine learning shake up some silicon platforms? Will laptops continue with quad-core processors or will ML processors routinely handle a lot of work? Graphics has been a continuous race to provide higher-quality rendering on phones and TVs, but people increasingly discuss deploying ML-based upscaling. That lets you render at much lower resolution on a GPU and use ML to upscale. You are constrained by how many GPUs you can integrate into a phone and power envelope; instead you might use smaller, lower-power GPUs with ML upscaling. Or you might vary upscaling based on lighting and time of day. These developments can make previous standards obsolete."
This can be particularly useful for accelerating complex modeling in design, especially when many different compute elements exist within the same chip or package. "If you include too many dependencies in your model, simulating them takes longer than doing the real thing," said Roland Jancke, head of design methodology for adaptive systems engineering at Fraunhofer IIS. "Then you overdesign the model. Modeling is always the tradeoff between abstraction and accuracy. Over the years we have recommended a multi-level approach so you have models at different levels of abstraction, and you dive deeper where you really need details."
AI can be helpful because it can correlate data, which in turn should support the AI market as design processes can be automated for both AI chip development and the chips themselves.
Krishnamoorthy added: "Currently, AI chip community revenue is around $2–3 billion and is expected to grow to $10 billion by the end of the decade. In EDA, AI is about optimizing designs for better PPA and achieving expert-level quality early in the design cycle. In verification, AI can achieve higher coverage than current methods by autonomously searching larger spaces. In test, it reduces pattern counts on handlers, directly cutting test cost and time. In custom design, it automates migrating analog circuits from 5 nm to 3 nm or from 8 nm to 5 nm, tasks that were previously manual."
Customization Costs and Operational Variability
Even in well-designed systems, many variables and unexpected outcomes can affect everything from data-path modeling to how MAC functions are partitioned across elements. For example, partitioning may be perfectly tuned in a fab or packaging facility, but processing elements may age out of sync and cause some elements to idle while waiting for others, wasting power. Interconnects, memory, and PHY may degrade over time and create timing issues. Worse, almost-constant changes in algorithms can significantly affect system performance far beyond individual MAC elements.
Many of these problems have been addressed inside large system companies that increasingly design chips for internal use. As more compute moves to the edge, that is changing—at the edge, power directly affects vehicle range per charge, and the usefulness of a wearable device depends on whether it can do more than basic tasks without excessive power draw.
The key is understanding how much AI to integrate into a design and what AI should actually do. Efficient SoCs often selectively enable and disable processing cores based on demand. But an efficient AI architecture can run many processing elements at top speed by breaking computation into parallel operations and then collecting results. If any element is delayed, time and energy are wasted. If done well, this can yield ultra-fast computation, but such speed comes at a cost.
One issue is that learning is not widely shared across the industry because many leading-edge designs are developed for internal use by system companies. That slows knowledge transfer and industry learning that typically occurs with each new processor generation or user-reviewed consumer product.
Conclusion
AI/ML/DL is no longer hype; it is being deployed in real applications. As design teams determine the most effective methods and how to apply them, AI will continue improving efficiency, performance, and accuracy. There will almost certainly be issues and uncertainties, such as how AI ages while adapting and optimizing systems over time. But AI is present in the foreseeable future and will continue to advance as long as resources and interest persist.







