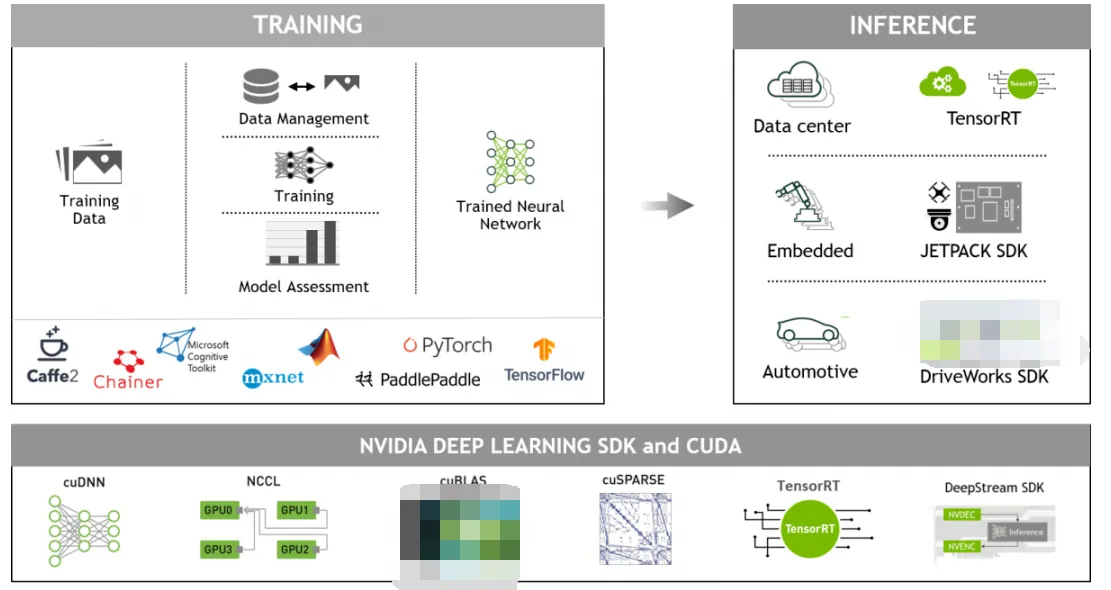
Introduction
Recommendation systems are a class of machine learning methods that use data to predict, narrow choices, and help users find items within rapidly expanding catalogs.
1. What Is a Recommendation System?
A recommendation system is an artificial intelligence algorithm, often tied to machine learning, that uses large-scale data to suggest products or content to consumers. Recommendations can rely on various signals, including past purchases, search history, demographic information, and other factors. These systems learn from interaction data such as impressions, clicks, likes, and purchases to infer user and item preferences and predict future interests.
Because they can provide highly personalized predictions of user interests and needs, recommendation systems are widely used by content and product providers across domains from books and video to courses and apparel.
Recommendation System Types
Most recommendation algorithms fall into three broad categories: collaborative filtering, content-based filtering, and context-aware filtering.
Collaborative Filtering
Collaborative filtering recommends items based on preference information aggregated across many users. It leverages similarity in user behavior and past user-item interactions to predict future interactions. The intuition is that if multiple users made similar choices in the past, they are likely to agree on other items in the future. For example, if a collaborative filtering system identifies that you and another user have similar tastes in movies, it may recommend a movie that the other user liked.
Content-Based Filtering
Content-based filtering recommends items based on item attributes or features. This method models similarity among items and users based on descriptive information, such as user age, cuisine type for a restaurant, or average rating of a movie, to estimate the likelihood of new interactions. For instance, if a content-based system knows you liked two romantic comedies, it may recommend another movie in the same genre or with overlapping cast.
Hybrid Systems
Hybrid recommendation systems combine methods from collaborative and content-based filtering to create more comprehensive recommendations.
Context-Aware Filtering
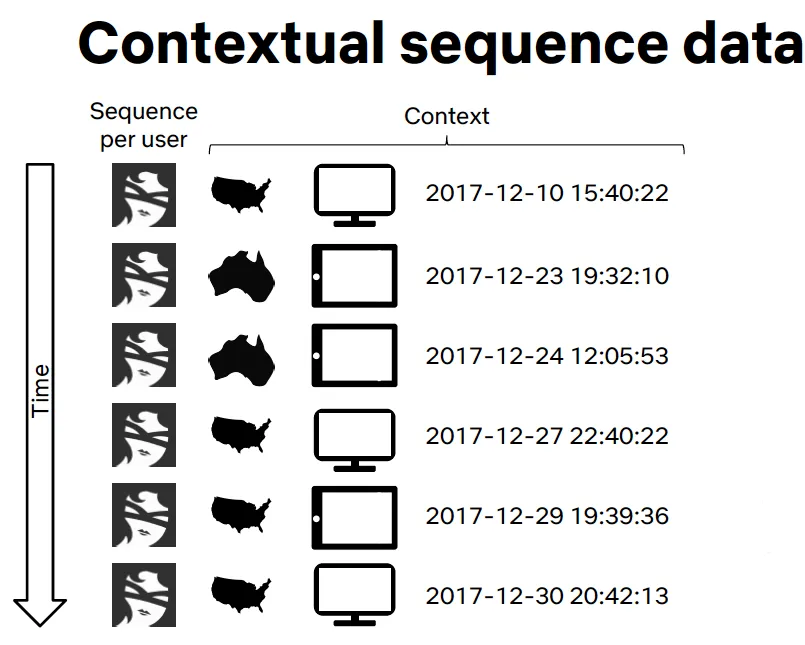
Context-aware methods incorporate background information about the user and session. For example, Netflix framed recommendations as a contextual sequence prediction problem, using sequences of contextual user actions and current context (country, device, date, time) to predict the next item a user is likely to watch.
2. Use Cases and Applications
E-commerce and Retail: Personalized Merchandising
When a user buys a scarf, recommending a matching hat can complete the look. E-commerce platforms implement such features as "complete the outfit" or "you may also like" using AI algorithms. Well-designed recommendation systems can significantly increase conversion rates.
Media and Entertainment: Personalized Content
AI recommendation engines analyze user behavior and detect patterns to suggest content that is more likely to match individual interests. This approach underpins targeted advertising and personalized content feeds on major platforms, as well as movie and show recommendations on streaming services.
Personalized Banking
Banks can use recommendation systems to offer relevant financial products by combining detailed customer financial profiles and historical preferences with aggregated data from similar customers.
3. Benefits of Recommendation Systems
Recommendation systems drive personalized experiences, deeper customer engagement, and serve as decision-support tools across retail, entertainment, healthcare, and finance. On large commercial platforms, recommendations can account for a substantial share of revenue, and small improvements in recommendation quality can translate into significant financial impact.
Common business objectives for deploying recommendation systems include:
- Improved retention. By continuously aligning with user preferences, businesses can increase the likelihood of retaining subscribers or shoppers.
- Increased sales. Accurate "you may also like" suggestions can raise revenue substantially by promoting additional purchases.
- Shaping habits and trends. Consistent delivery of relevant content can influence user behavior and usage patterns.
- Faster research and discovery. Analysts and researchers can save time when customized suggestions speed up access to relevant resources.
- Higher cart value. Recommendation strategies—such as suggesting complementary items, recovering abandoned carts, and surfacing popular purchases—can increase average order size.
4. How Recommendation Systems Work
The choice of recommendation model depends on the available data. If only historical interaction data is available, collaborative filtering is often used. If descriptive features about users and items exist, content and context can be added to model the likelihood of new interactions under those attributes.
Matrix Factorization
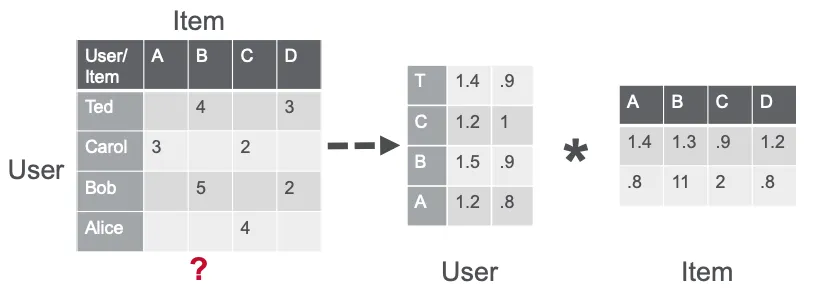
Matrix factorization (MF) is a core technique for many algorithms, including embeddings and topic models, and is a primary approach in collaborative filtering. MF estimates similarity in user ratings or interactions to generate recommendations.
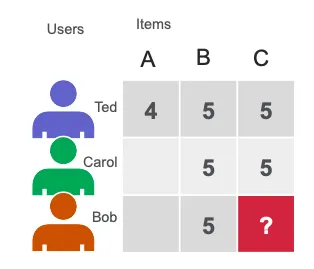
For example, in a simple user-item matrix where Ted and Carol liked movies B and C while Bob liked movie B, matrix factorization can identify that users who liked B also liked C and thus suggest C to Bob.
Alternating Least Squares (ALS) approximates a sparse user-item rating matrix as the product of two dense factor matrices of sizes u x f and f x i, where u is the number of users, i is the number of items, and f is the number of latent features. ALS iteratively optimizes one factor matrix while fixing the other until convergence.
CuMF is a CUDA-based matrix factorization library that optimizes ALS for large-scale MF. It uses techniques such as intelligent sparse data access patterns for GPU memory hierarchies, hybrid data and model parallelism to reduce inter-GPU communication, and topology-aware parallel reduction strategies.
5. Deep Neural Network Models for Recommendations
Artificial neural networks (ANNs) appear in several variants used for recommendation tasks:
- Feedforward networks such as multilayer perceptrons (MLPs) with input, hidden, and output layers.
- Convolutional neural networks (CNNs) for image feature extraction.
- Recurrent neural networks (RNNs) for modeling sequential and language patterns.
Deep learning (DL) models extend classical techniques by modeling interactions among variables and embeddings, where embeddings are learned dense vectors representing entities so that similar entities are nearby in vector space. DL methods can learn user and item embeddings and handle large datasets with expressive architectures and optimization algorithms.
Common DL-based recommendation models include DLRM, Wide & Deep, Neural Collaborative Filtering (NCF), variational autoencoders (VAE) for collaborative filtering, and Transformer-based models such as BERT for NLP tasks. These models are typically trained and optimized with frameworks like TensorFlow and PyTorch.
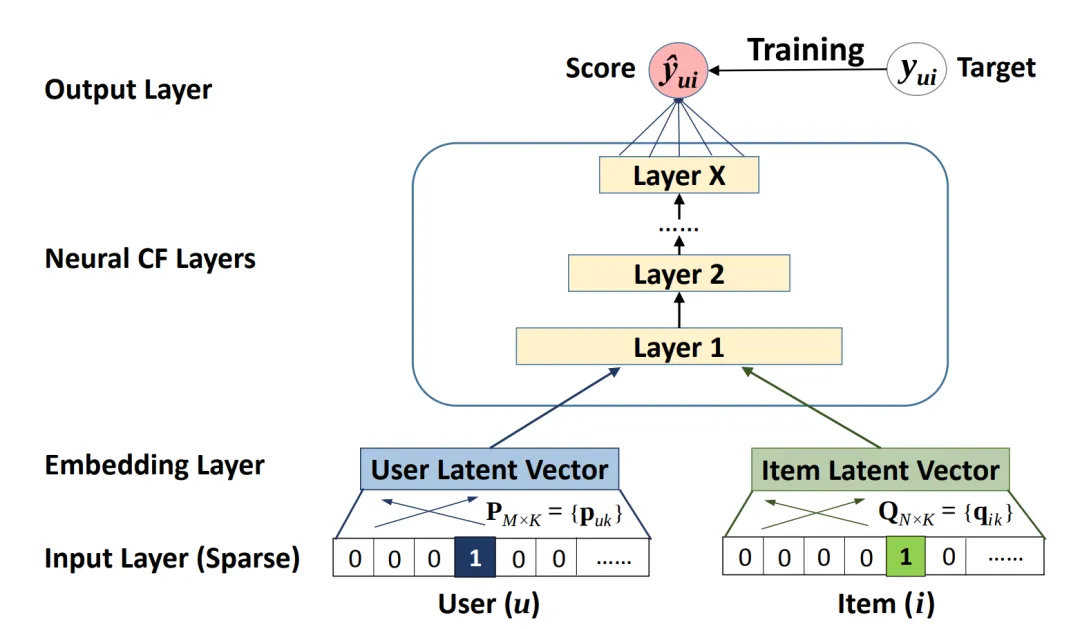
Neural Collaborative Filtering
Neural Collaborative Filtering (NCF) is a neural network that implements collaborative filtering from a nonlinear perspective. NCF takes (user ID, item ID) pairs as input, maps them to embeddings, and inputs the embeddings into MLPs. Outputs from factorization-style and MLP components are combined in a dense layer to predict the probability of interaction between the input user and item.
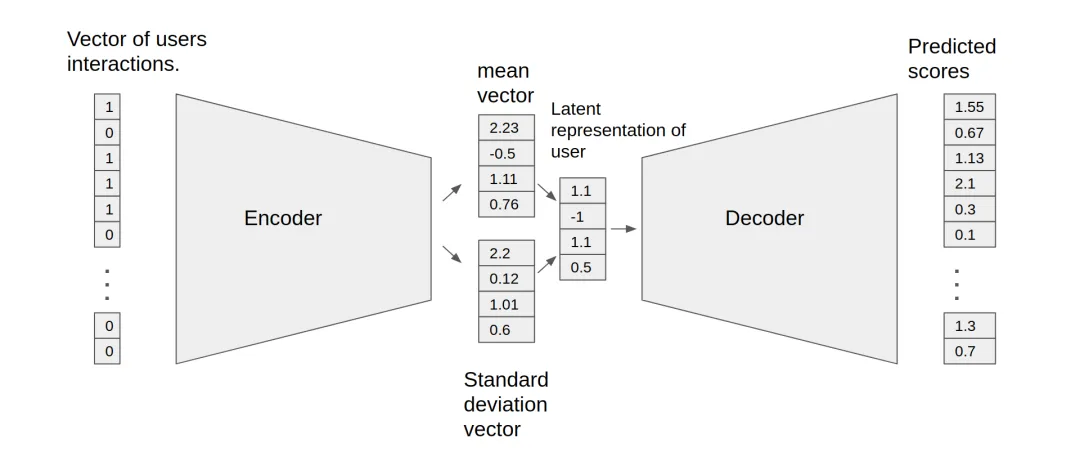
Variational Autoencoders for Collaborative Filtering
Autoencoders reconstruct input vectors from representations learned in hidden layers. For collaborative filtering, autoencoders can learn nonlinear representations of the user-item matrix and reconstruct missing values. VAE-based collaborative filtering models consist of an encoder that maps user interaction vectors to an n-dimensional variational distribution and a decoder that maps sampled latent representations back to predicted item interaction probabilities.
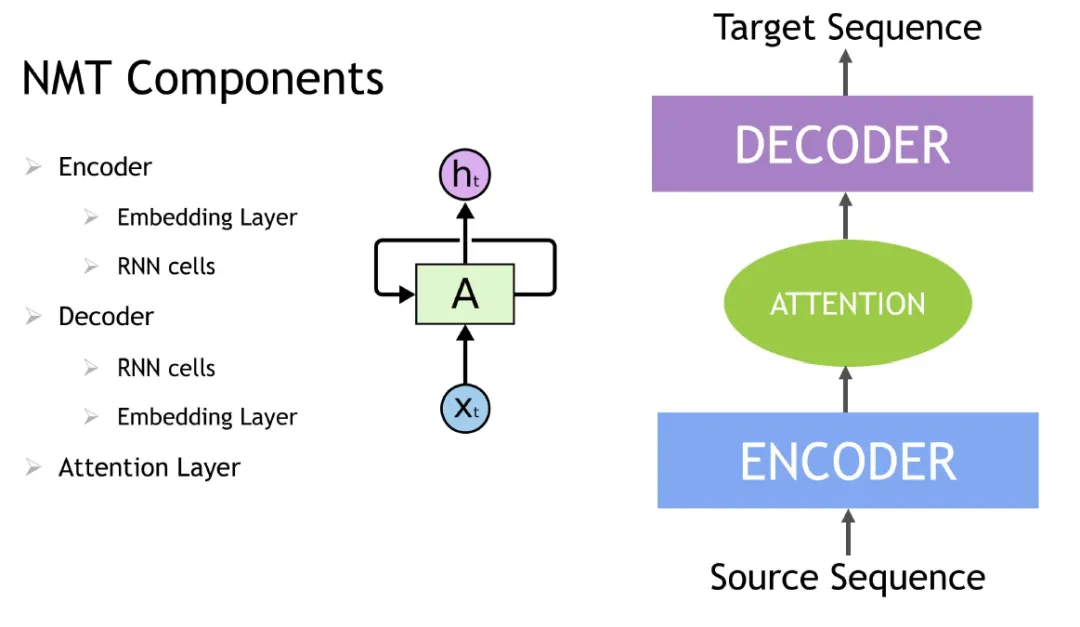
Contextual Sequence Learning
RNNs, including LSTM and GRU variants, are used to model sequential and contextual dependencies and are suitable for session-based or sequential recommendation tasks. Transformer architectures, such as BERT, provide an alternative to RNNs by using attention mechanisms that focus on the most relevant items in context. Transformer-based models enable greater parallelism on GPUs and can reduce training time compared with RNNs.
For NLP-related inputs, word embedding techniques convert text into numerical vectors that are then processed by RNN variants or Transformer models to capture semantic and contextual information for downstream sequence prediction tasks.
Session-based recommendations apply DL and NLP sequence modeling advances to predict the next item in a user session based on the sequence of events such as viewed products and interaction timestamps. Items in the session are embedded into vectors before being input to an RNN, LSTM, GRU, or Transformer to understand session context.
Wide & Deep
Wide & Deep models combine a linear "wide" component and a nonlinear "deep" component in parallel and sum their outputs to estimate interaction probabilities. The wide component is a generalized linear model over raw and transformed features. The deep component is a dense neural network fed by dense feature embeddings. This combination captures both memorization (wide) and generalization (deep) behaviors, often improving performance over single-channel models.
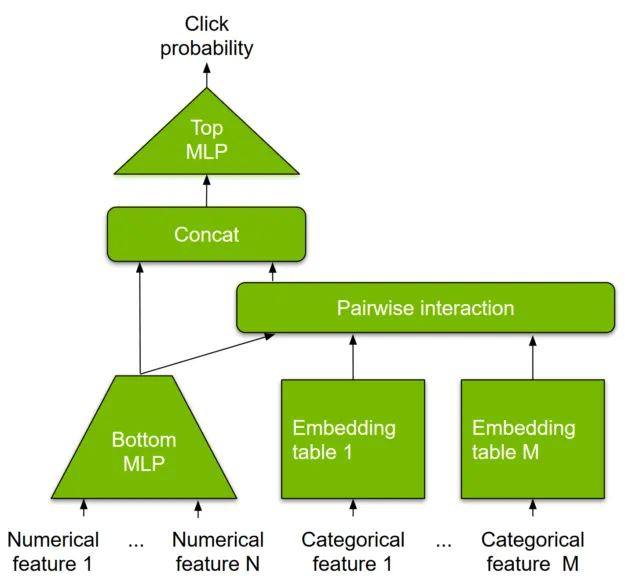
DLRM
DLRM is a deep learning model designed for recommendation that handles categorical and numerical inputs commonly found in recommendation datasets. Categorical features are mapped via embedding layers to dense representations and passed to MLPs, while numerical features feed directly into the MLP. Pairwise feature interactions are computed explicitly via dot products among embedding vectors and processed by top-level MLPs to compute interaction probabilities. DLRM emphasizes efficient representation and pairwise interaction computation to reduce compute and memory cost while maintaining competitive accuracy.
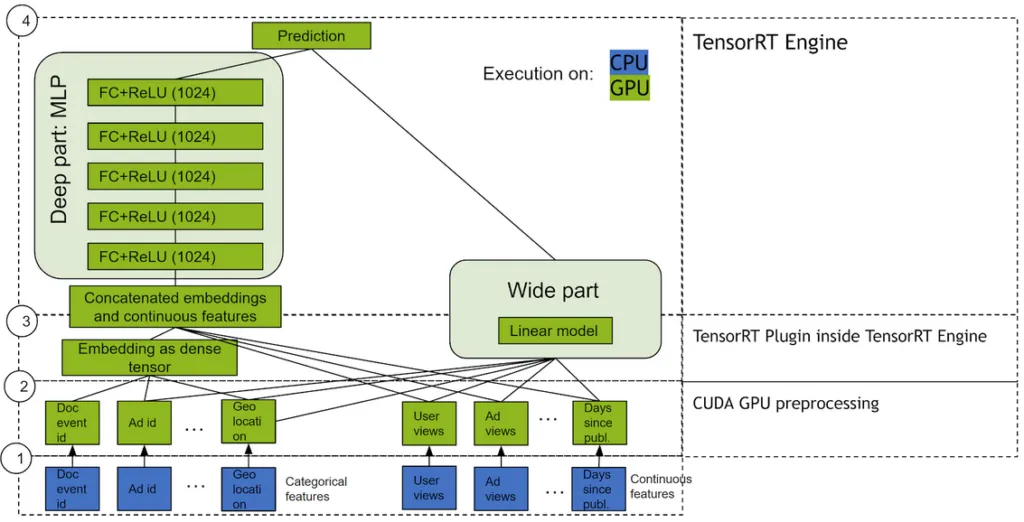
6. Why Recommendation Systems Run Better on GPUs
As datasets scale from tens of millions to billions of examples, deep learning techniques outperform some traditional methods. Many underlying math operations in machine learning are matrix multiplications, which are highly parallelizable and can be accelerated on GPUs. GPUs with hundreds of cores can process thousands of threads in parallel, a natural fit for neural networks composed of many similar neurons. Compared with CPU-only platforms, GPUs often yield significantly higher throughput for both training and inference, making them the preferred platform for large, complex neural recommendation systems.

7. Merlin Recommendation System Framework
Large-scale recommendation systems face performance challenges including large datasets, complex preprocessing and feature engineering, and repeated experimentation. GPU-based solutions can provide fast feature engineering, high training throughput for rapid experimentation and retraining, and low-latency, high-throughput inference for production deployment.
Merlin is an open-source framework and ecosystem designed to support recommendation system development across the lifecycle, accelerated by NVIDIA GPUs. The framework provides optimized feature engineering and preprocessing operators commonly used in recommendation datasets, and it supports several DL recommendation architectures for high-throughput training and production retraining, including Wide & Deep, Deep Cross Networks, DeepFM, and DLRM. For production, components provide low-latency, high-throughput inference for deployment.
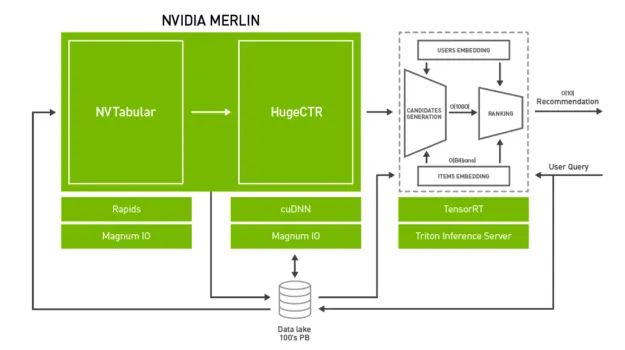
Merlin includes tools for building DL-based recommender systems and supports pipelines for datasets at scale. NVTabular accelerates feature transforms and preprocessing on GPUs to reduce data preparation time. HugeCTR is a GPU-accelerated training framework that supports model parallel embedding tables and data-parallel neural networks for models such as WDL, DCN, DeepFM, and DLRM. NVIDIA Triton inference server and TensorRT accelerate production inference on GPUs for feature transforms and neural network execution.
8. GPU-Accelerated End-to-End Data Science and Deep Learning
Merlin is built on the RAPIDS ecosystem. RAPIDS is a suite of open-source libraries built on CUDA that enables end-to-end data science and analytics entirely on GPUs while providing familiar APIs similar to Pandas and Scikit-Learn.
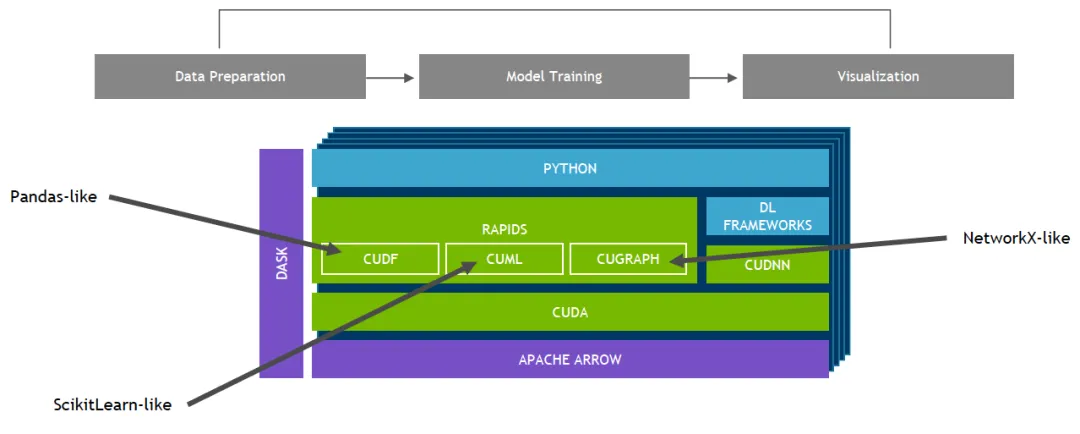
9. GPU-Accelerated Deep Learning Frameworks
GPU-accelerated deep learning frameworks provide flexibility for designing and training custom deep neural networks and offer programming interfaces for common languages such as Python and C/C++. Widely used frameworks like MXNet, PyTorch, and TensorFlow rely on NVIDIA GPU-accelerated libraries to deliver high-performance multi-GPU training.