Introduction
The "No Free Lunch" theorem, especially relevant to supervised learning, states that there is no single algorithm that performs best for every problem. An algorithm that works well for one problem may not outperform others on a different problem. Factors such as the size and structure of the dataset influence algorithm performance.
When facing a problem, it is common practice to try multiple algorithms, evaluate their performance on a held-out test set, and select the best-performing approach. The chosen algorithm should be appropriate for the problem at hand.
Background
Supervised machine learning algorithms can be viewed as methods for learning a target function f that maps input variables X to output variables Y: Y = f(X). The goal is to learn f from training data so that, given new inputs X, the model can accurately predict Y.
This article summarizes ten commonly used machine learning algorithms for readers who are new to the field.
1. Linear Regression
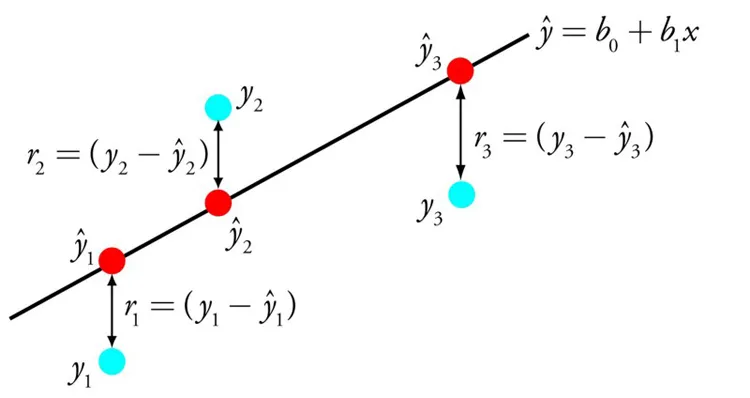
Linear regression is a widely known and easy-to-understand method from statistics and machine learning. It models the relationship between input variables and a continuous output by fitting a linear equation. The model finds coefficients B that describe a line approximating the relationship between x and y, for example y = B0 + B1 * x.
Given input x, the model predicts y. Linear regression methods find the coefficients B0 and B1, for example using ordinary least squares or gradient descent optimization.
2. Logistic Regression
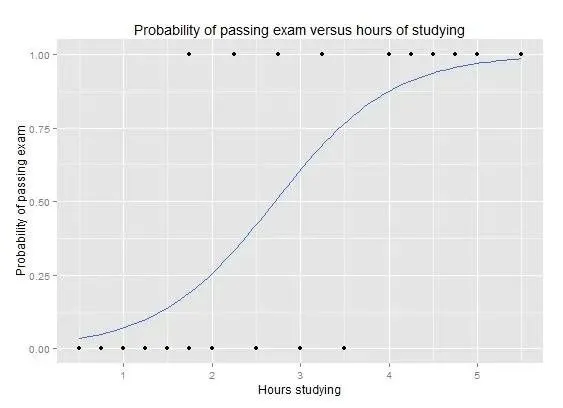
Logistic regression is another technique adapted from statistics and is a common choice for binary classification problems. Like linear regression, it finds weights for input variables, but applies a nonlinear logistic function to the linear combination of inputs to produce outputs in the range 0 to 1. A decision rule then maps these outputs to discrete class labels.
Logistic regression performs well when irrelevant and highly correlated features are removed. It is a fast and efficient model for binary classification.
3. Linear Discriminant Analysis
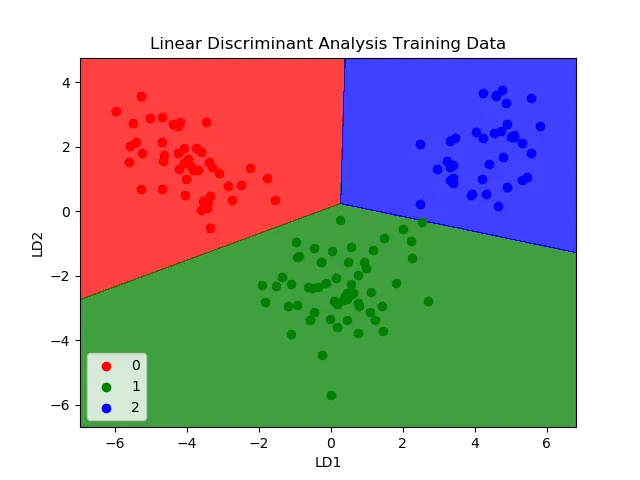
Linear discriminant analysis (LDA) is a classification algorithm suited to multi-class problems. LDA represents each class using statistical properties computed from the data, such as per-class means and the common variance across classes. For a single input variable, these include the mean of each class and the overall variance.
Prediction is performed by computing a discriminant score for each class and selecting the class with the highest score. LDA assumes that the data for each class are Gaussian-distributed, so it performs best after outlier removal.
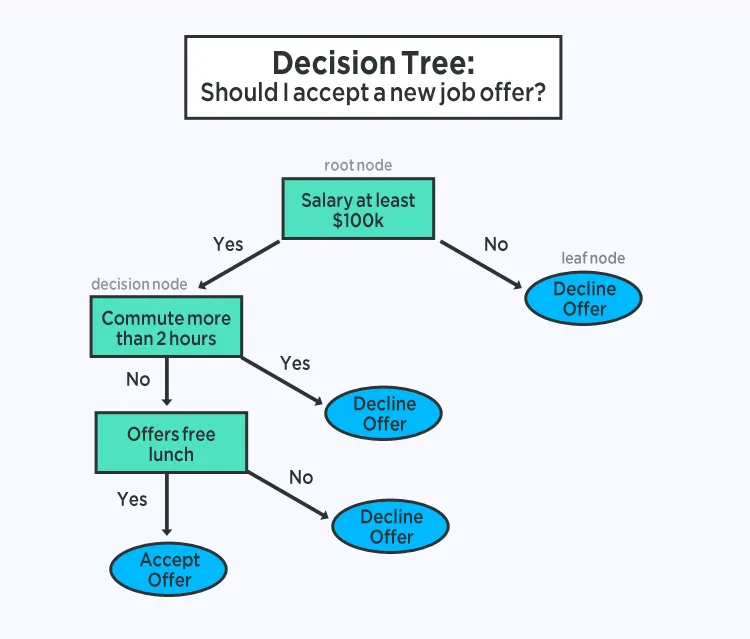
4. Classification and Regression Trees
Decision trees are a common type of model for supervised prediction tasks. A decision tree is represented as a binary tree where each internal node specifies a split on an input variable and each leaf node contains an output prediction. Prediction is made by traversing the tree according to input feature values until reaching a leaf node that outputs the class or regression value.
Trees are fast to learn and quick to evaluate, often achieving strong performance without extensive data preprocessing.
5. Naive Bayes
Naive Bayes is a simple probabilistic classifier based on Bayes' theorem. The model estimates two types of probabilities directly from the training data: 1) the prior probability of each class, and 2) the conditional probability of each feature value given each class. For continuous features, a Gaussian assumption is often used to estimate these probabilities.
It is called "naive" because it assumes that input features are conditionally independent given the class label. Although this assumption is often violated in practice, Naive Bayes remains effective for many complex problems.
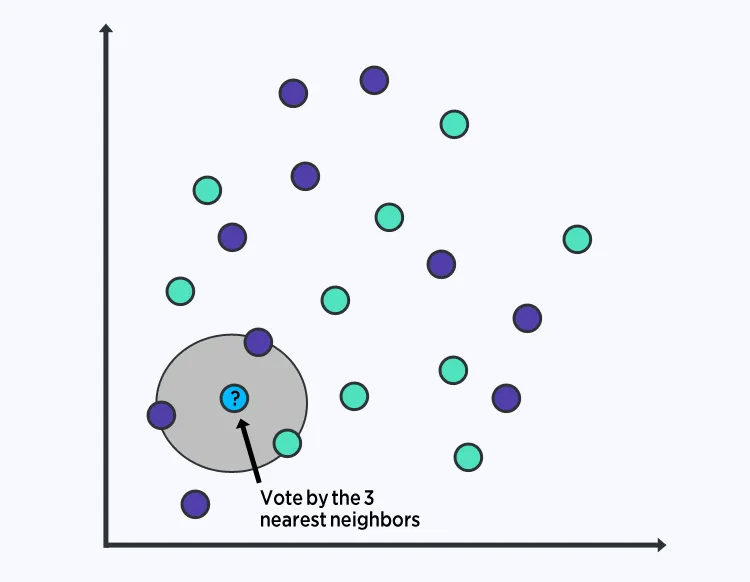
6. K-Nearest Neighbors
The K-nearest neighbors (KNN) algorithm is simple and effective. The model representation is the entire training dataset. To predict for a new data point, KNN finds the K most similar instances in the training set and aggregates their outputs. For regression, this might be the average; for classification, the most frequent class among the neighbors.
Similarity is commonly measured using Euclidean distance if features share the same scale. KNN can require large memory to store training data and its performance may degrade in high-dimensional spaces, making feature selection or scaling important.
7. Learning Vector Quantization
Learning vector quantization (LVQ) is a prototype-based supervised classification algorithm that mitigates the storage drawback of KNN by learning a set of representative prototype vectors. Prototypes are initialized (often randomly) and iteratively adjusted to summarize the training set. Prediction is performed by finding the prototype nearest to a new instance and returning its class label. Normalizing features typically improves results.
8. Support Vector Machines
Support vector machines (SVM) are a widely used class of classifiers. The algorithm finds a hyperplane that best separates points in the input space by class. In two dimensions this is a line; in higher dimensions it is a hyperplane. The distance between the hyperplane and the nearest data points from each class is called the margin. The optimal hyperplane maximizes this margin. Only the points closest to the margin, called support vectors, influence the final classifier. Optimization algorithms are used to find the coefficients that maximize the margin.
SVMs are powerful, off-the-shelf classifiers for many problems.
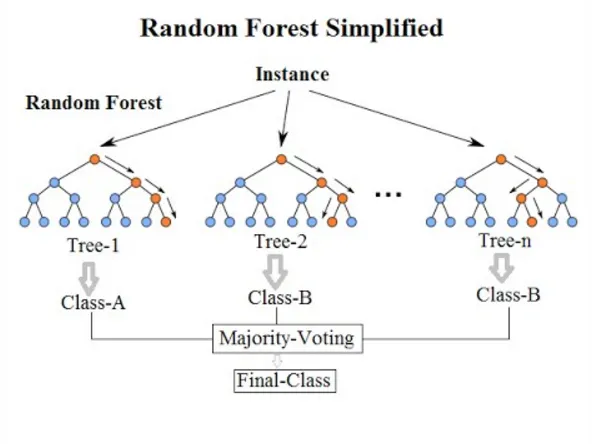
9. Bagging and Random Forests
Bagging, or bootstrap aggregating, is an ensemble method that builds multiple models from bootstrap samples of the training data and combines their predictions, for example by averaging. This reduces variance and provides a better estimate of the target.
Random forest is an adaptation of bagging applied to decision trees, where further randomness is introduced by selecting a random subset of features for candidate splits. This increases diversity among the trees and typically improves the aggregated prediction.
10. Boosting
Boosting is an ensemble technique that builds a strong classifier by sequentially adding weak classifiers, each focused on correcting errors made by the previous ones. AdaBoost was one of the first successful boosting algorithms for binary classification and provides an accessible introduction to boosting. Modern boosting methods are often based on AdaBoost; a well-known example is gradient boosting.
In boosting with decision trees, each successive tree is trained with attention weighted toward instances that previous trees misclassified. After training, predictions from all trees are combined, typically with weights related to each tree's performance on the training data. Because boosting emphasizes correcting errors, data cleaning and outlier removal are important.
Further Reading
For deeper explanations and visual examples of these algorithms, consult textbooks or tutorial videos covering supervised learning methods and ensemble techniques.







