Today's article summarizes a detailed implementation of the Transformer deep learning model. It covers the model architecture and the key components used in practice, including self-attention, multi-head attention, positional feed-forward networks, residual connections, positional encoding, masking, and regularization.
Contents
- Transformer overall architecture
- Overview
- Tensors and embeddings
- Self-attention
- Multi-head attention
- Position-wise feed-forward networks
- Residual connections and layer normalization
- Positional encoding
- Decoder
- Masks: padding mask and sequence mask
- Final linear and softmax layers
- Embedding sharing
- Regularization
1. Transformer model architecture
In 2017, the paper "Attention Is All You Need" proposed the Transformer model, which replaces RNNs commonly used in NLP tasks with self-attention structures. Compared with RNNs, a primary advantage is the ability to perform parallel computation. The overall Transformer architecture is shown in the figure below.
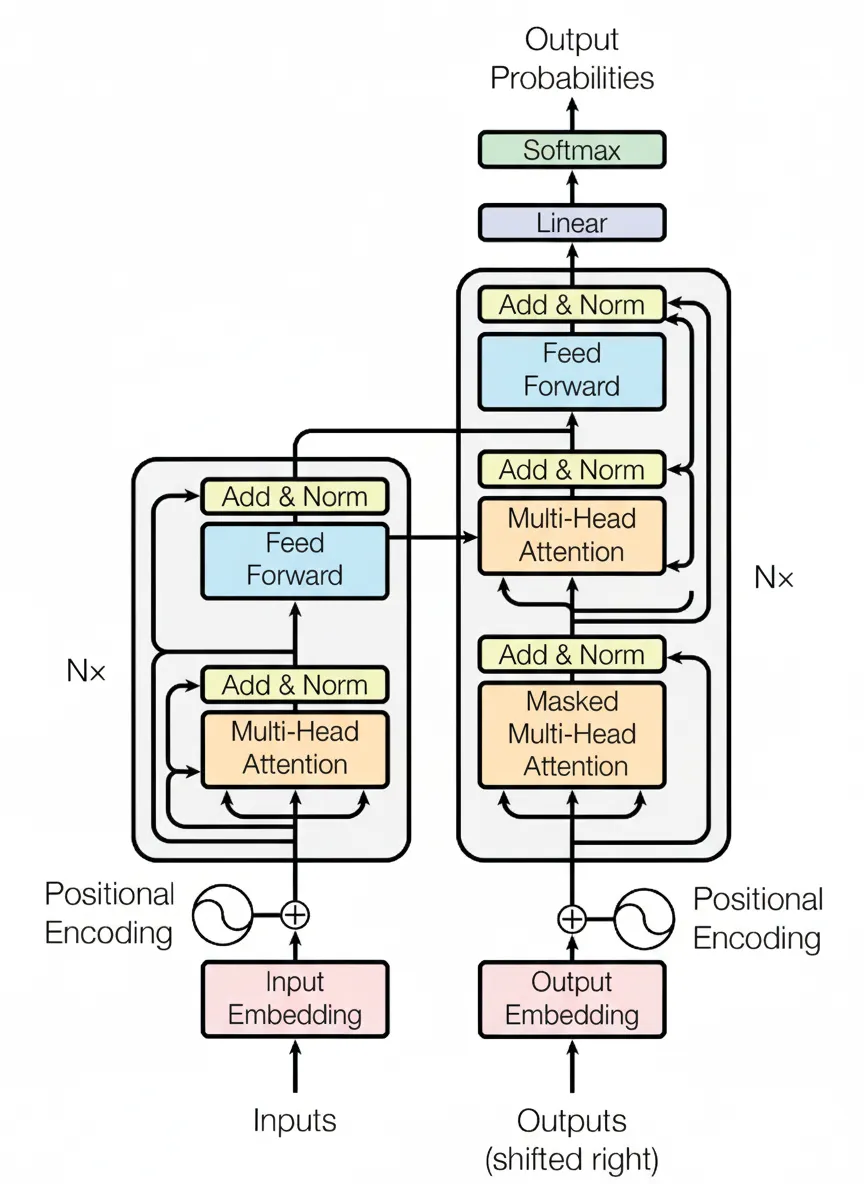
2. Overview
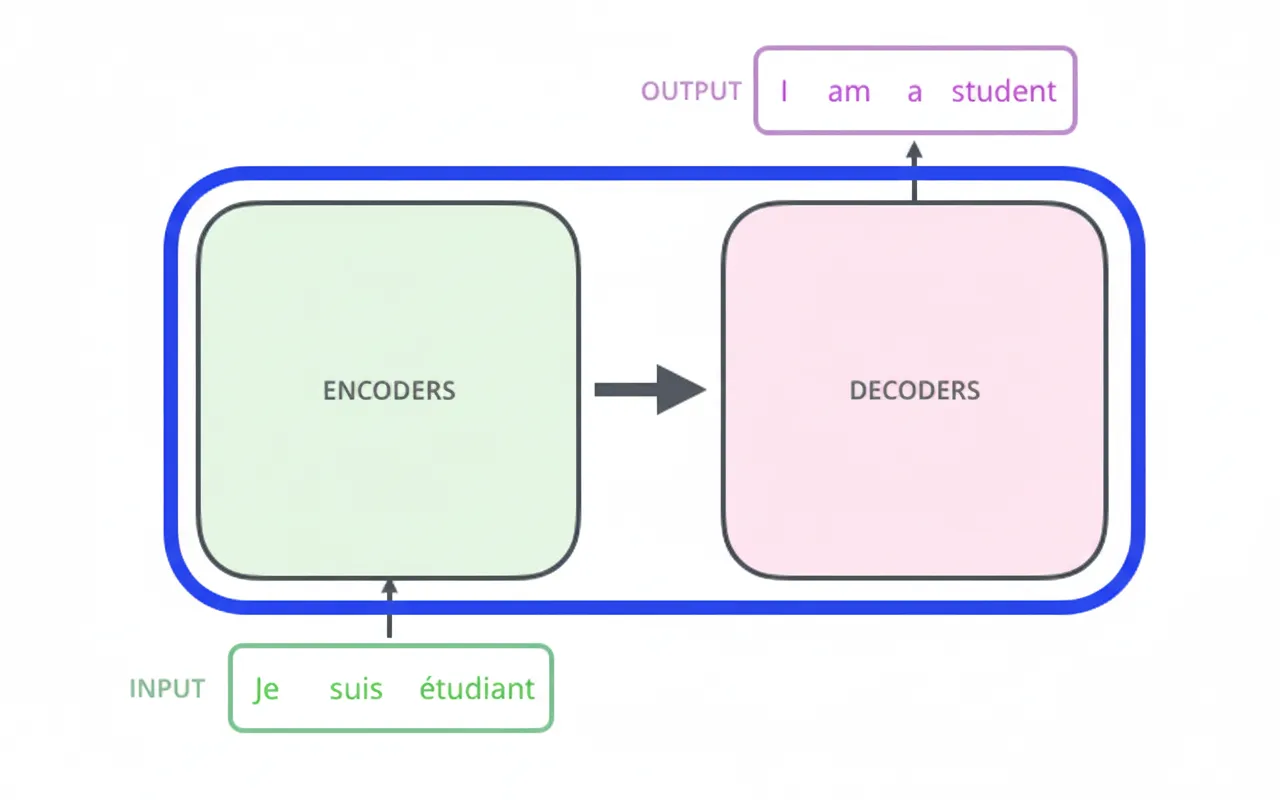
Treat the Transformer as a black box: for machine translation, it maps an input sentence in one language to an output sentence in another language.

2.1 Encoder-Decoder
The Transformer is an encoder-decoder architecture. The middle portion can be divided into two components: the encoder stack and the decoder stack.
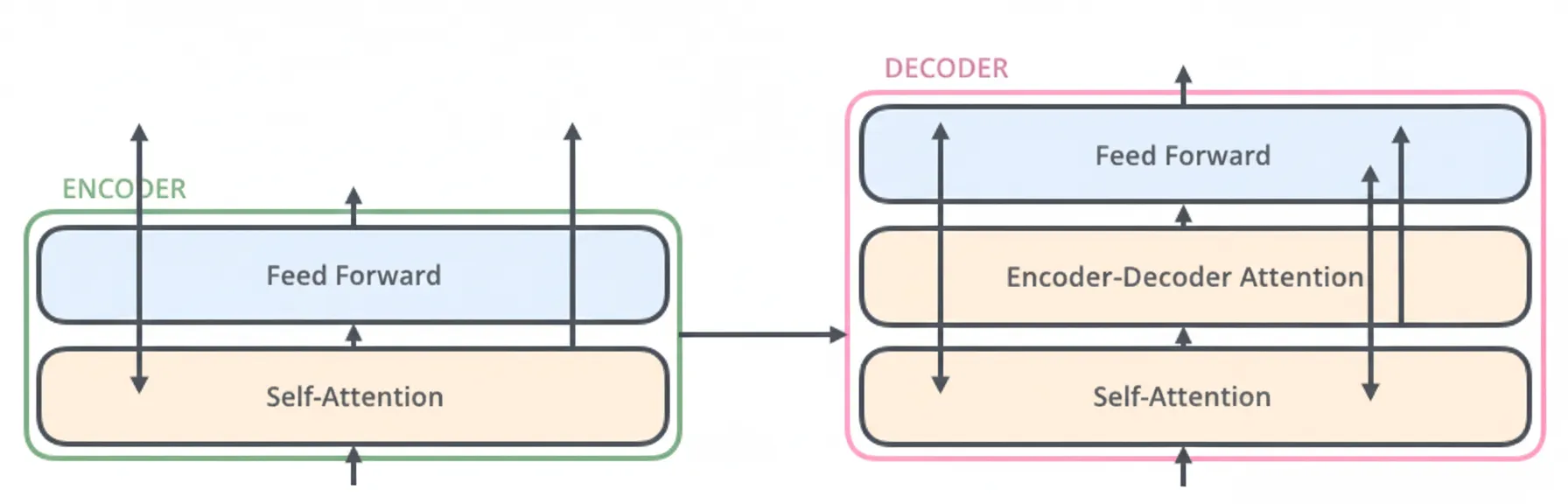
The encoder component consists of multiple encoder layers (the original paper used 6 layers), and the decoder component consists of the same number of decoder layers (also 6 in the original paper). Each encoder layer contains two sublayers:
- Self-attention layer
- Position-wise feed-forward network (FFN)
The encoder first passes inputs through the self-attention layer, then through the feed-forward network. The decoder contains the same two sublayers plus an additional encoder-decoder attention layer that lets the decoder attend to relevant parts of the encoder output.
3. Tensors and embeddings
Next we examine the vectors and tensors and how they flow through the model from input to output.
3.1 Word embeddings
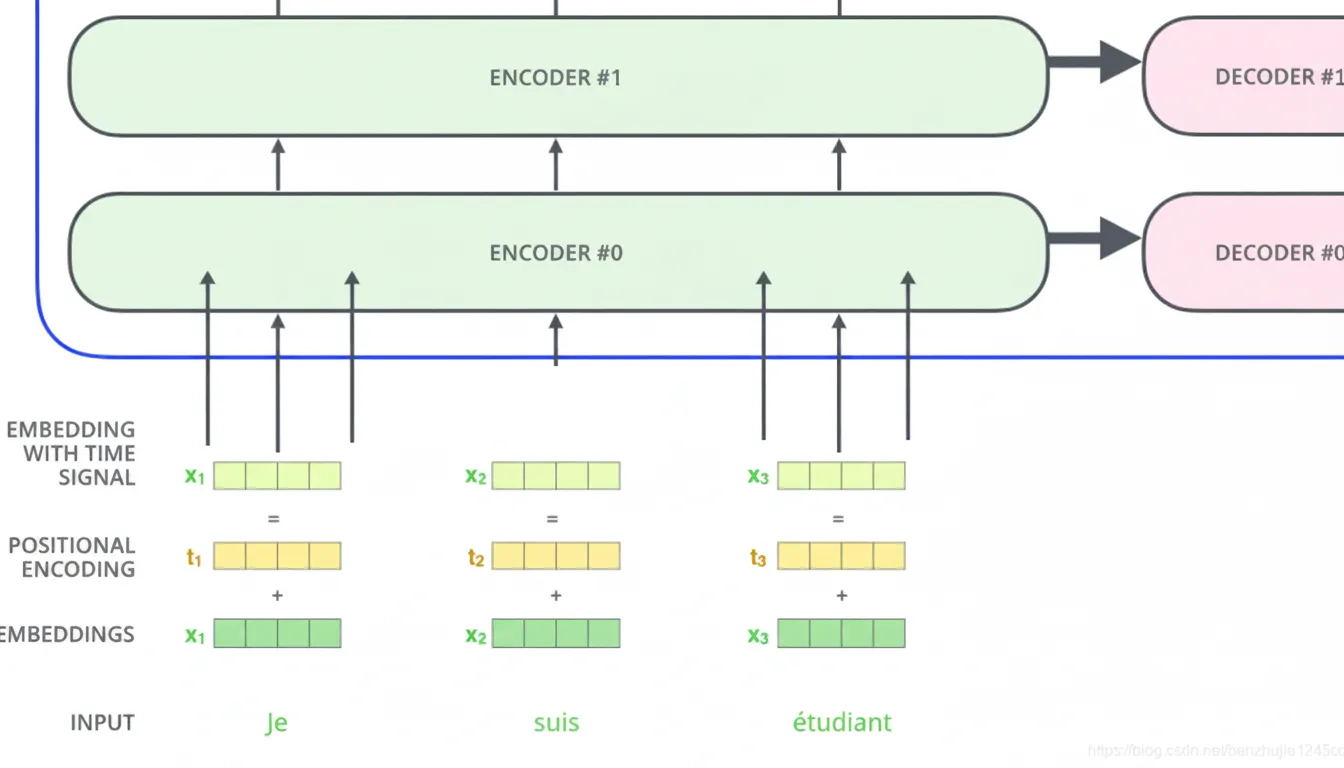
As in typical NLP tasks, words are first converted to word vectors using embeddings. In the original Transformer, embedding dimension is 512.
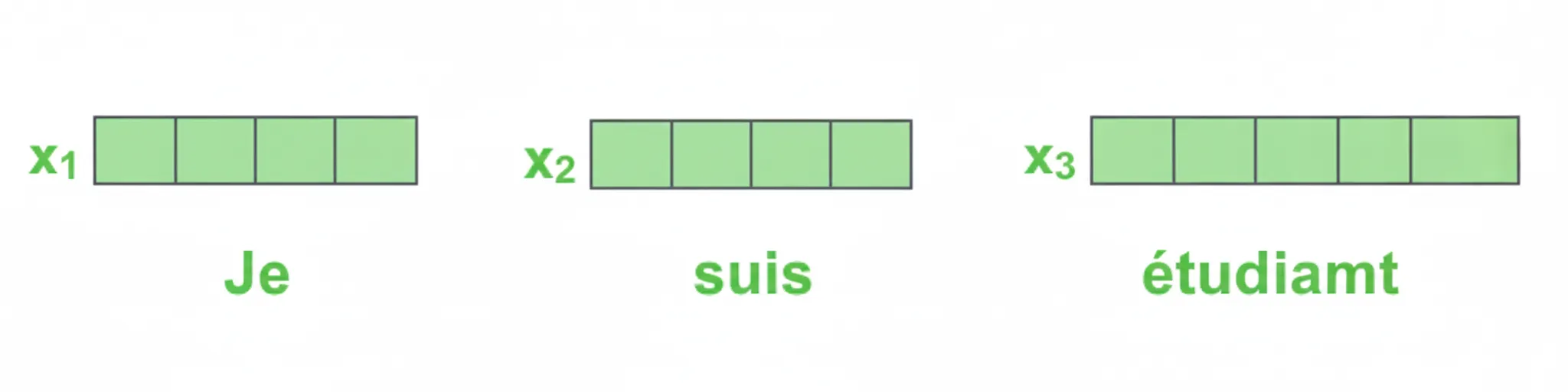
Word embeddings occur only at the bottom layer of the encoder stack. Each encoder receives a sequence of 512-dimensional vectors. The sequence length is a hyperparameter, typically set to the maximum sentence length in the training data.
3.2 Encoding after embedding
After embedding, each token vector passes through the encoder sublayers as shown below.
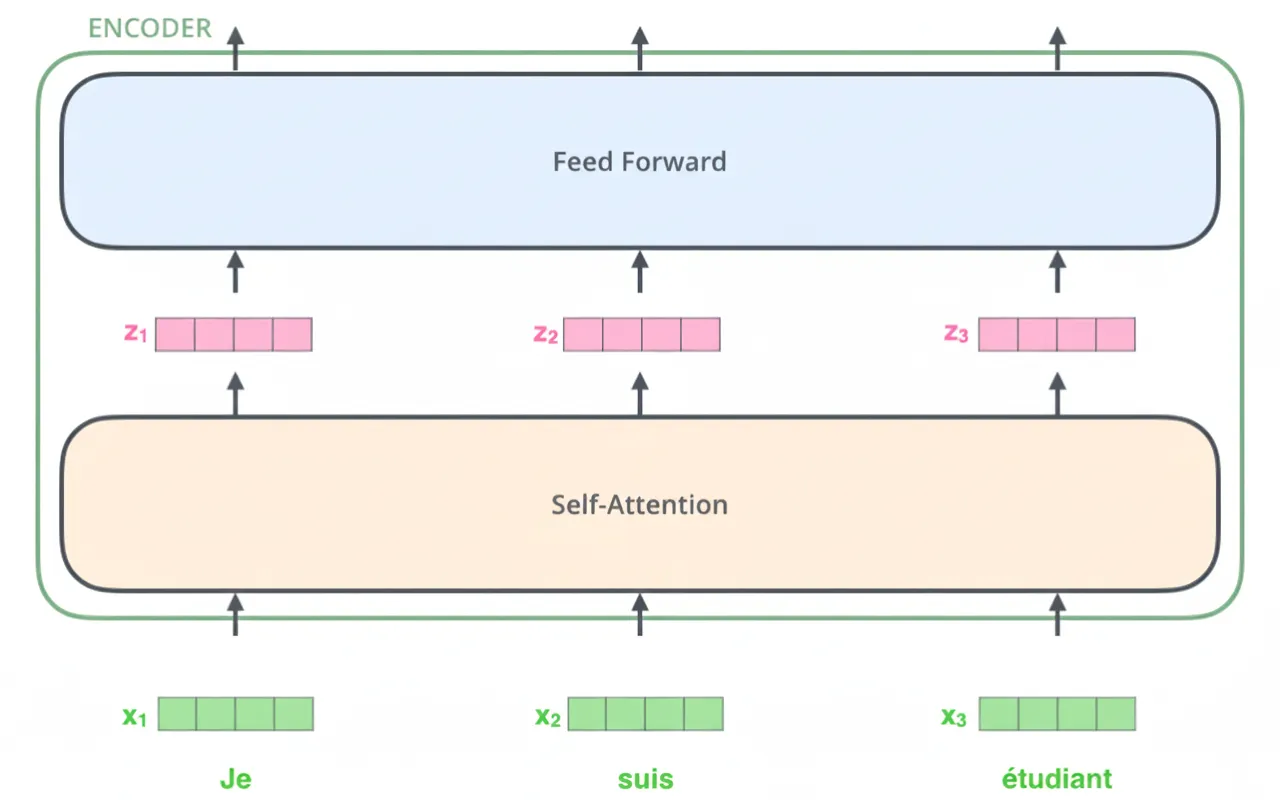
4. Self-Attention
4.1 Self-attention overview
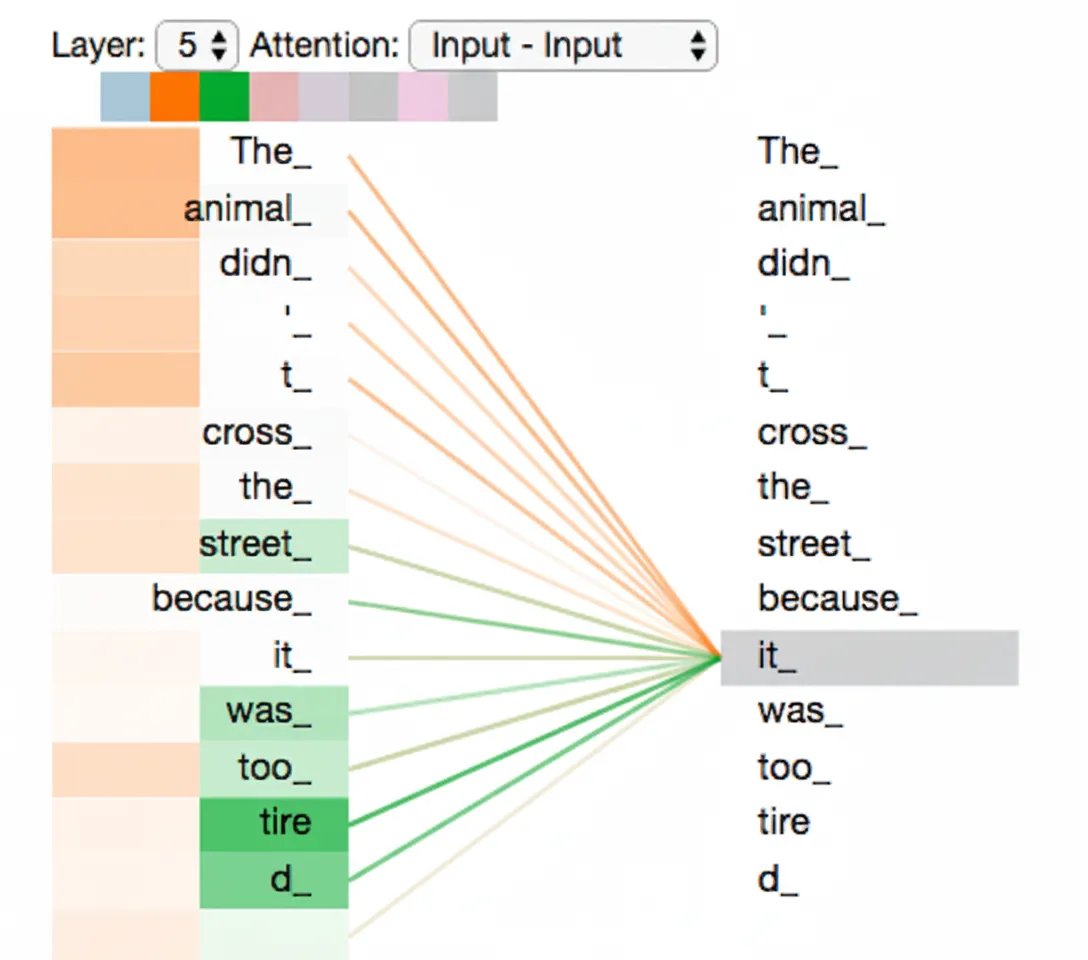
Consider this example sentence: "The animal didn’t cross the street because it was too tired." What does "it" refer to: animal or street? For humans this is trivial, but for an algorithm it is harder. Self-attention lets the model associate "it" with "animal" or other relevant tokens. When processing each position, self-attention allows the model to attend to other positions in the sequence to better encode the current token.
4.2 Self-attention mechanism
Self-attention uses Query (Q), Key (K), and Value (V) matrices derived from the same input. The scaled dot-product attention computes the dot product of Q and K, scales by sqrt(d_k), applies softmax to obtain weights, and then multiplies by V to produce the weighted sum. The basic computation is:
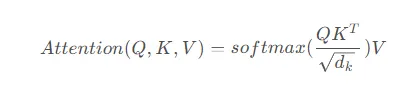
4.3 Self-attention step-by-step
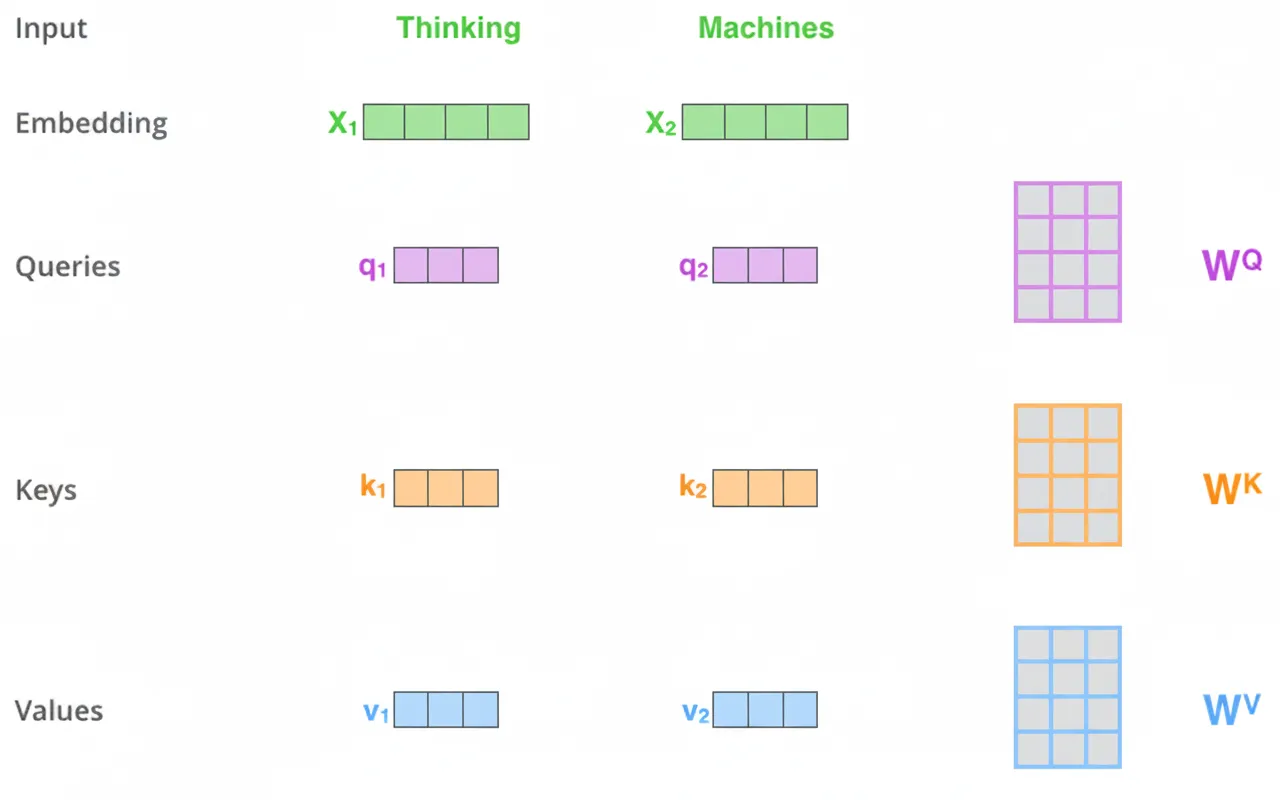
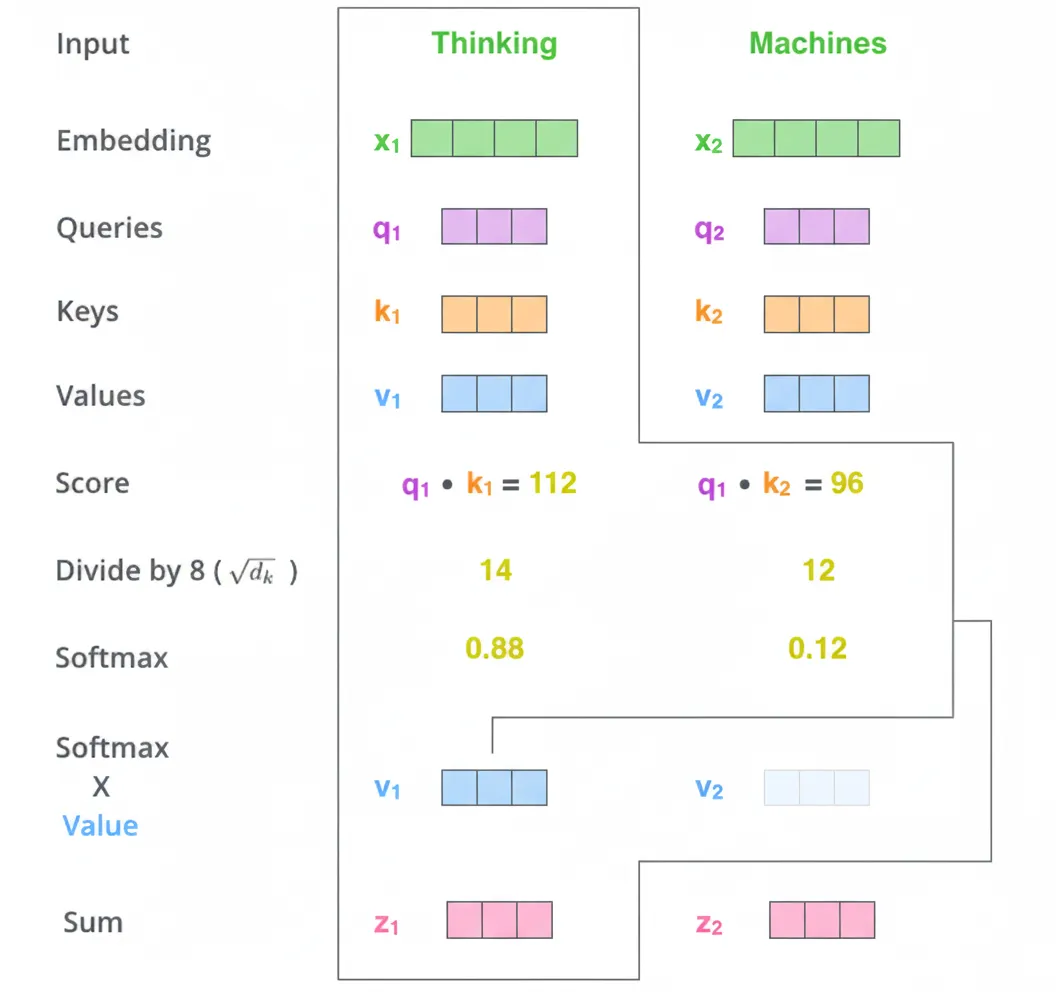
Step 1: For each input vector (token embedding), create three vectors: Query, Key, and Value. These are obtained by multiplying the token embedding by three learned weight matrices. In the original model the new vectors have dimension 64 while the embeddings are 512. The smaller dimension is chosen to make multi-head attention tractable.
Step 2: Compute attention scores. For a token like "Thinking", compute a score for every token in the sentence by taking the dot product between the Query for "Thinking" and the Key of each token.
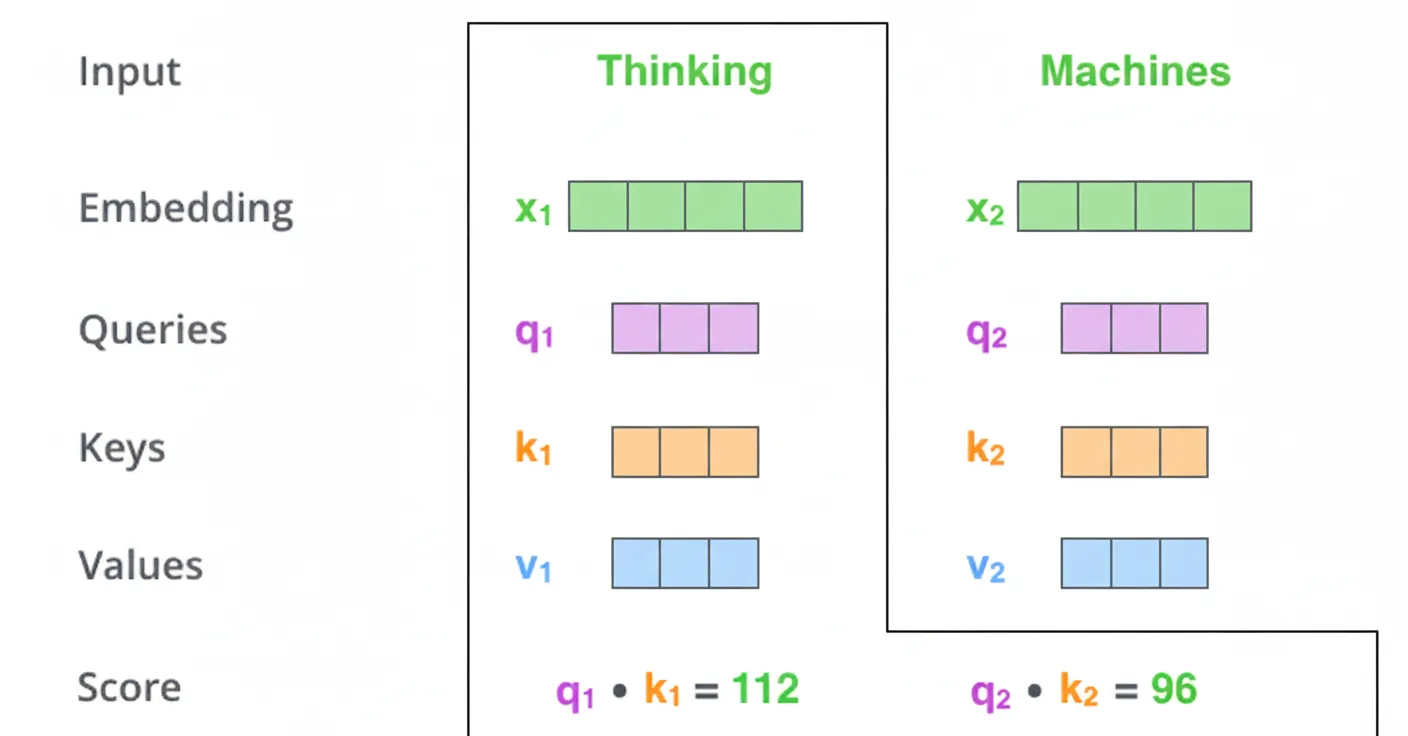
Step 3: Divide each score by sqrt(d_k) where d_k is the Key vector dimension. This stabilizes gradients during training.
Step 4: Apply softmax to obtain normalized attention weights.
Step 5: Multiply each softmax weight by the corresponding Value vector. High weights emphasize relevant positions; low weights downweight irrelevant positions.
Step 6: Sum the weighted Value vectors to produce the output for the current position. The resulting vectors are fed to the feed-forward network. In practice these operations are implemented efficiently using matrix multiplications.
4.4 Matrix implementation
Step 1: Stack all token embeddings into a matrix X. Compute Q, K, V matrices by multiplying X with three learned weight matrices.
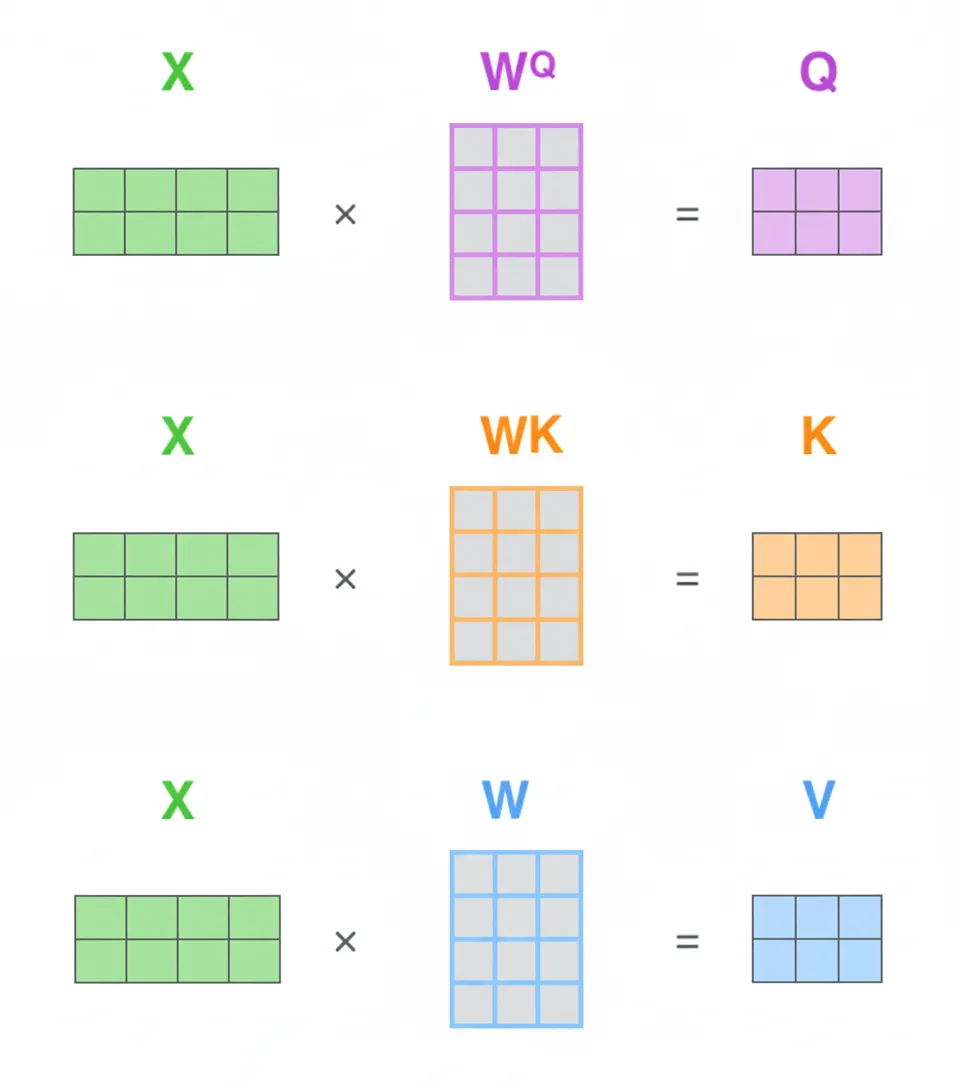
Each row of X is a token embedding. Rows of Q, K, V correspond to the Query, Key, Value vectors for each token. Step 2 compresses steps 2 through 6 into a single matrix expression using scaled dot-product and softmax.
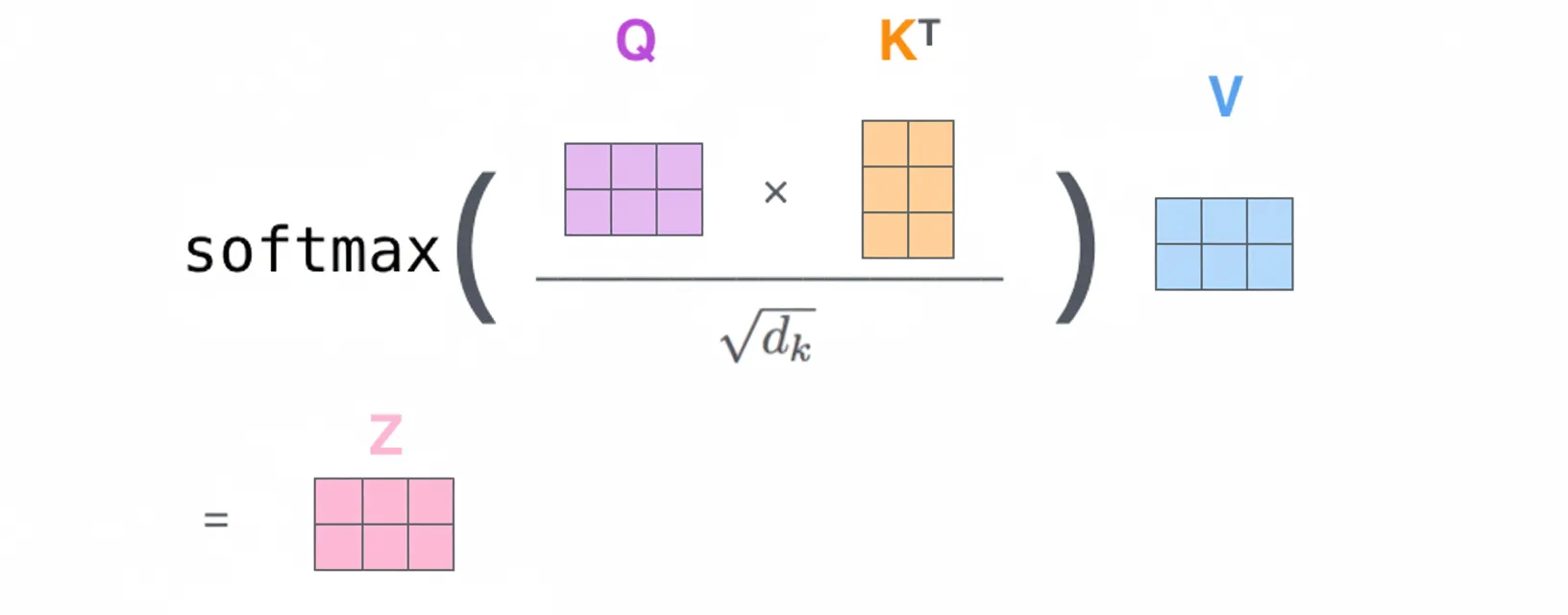
5. Multi-head attention
5.1 Architecture
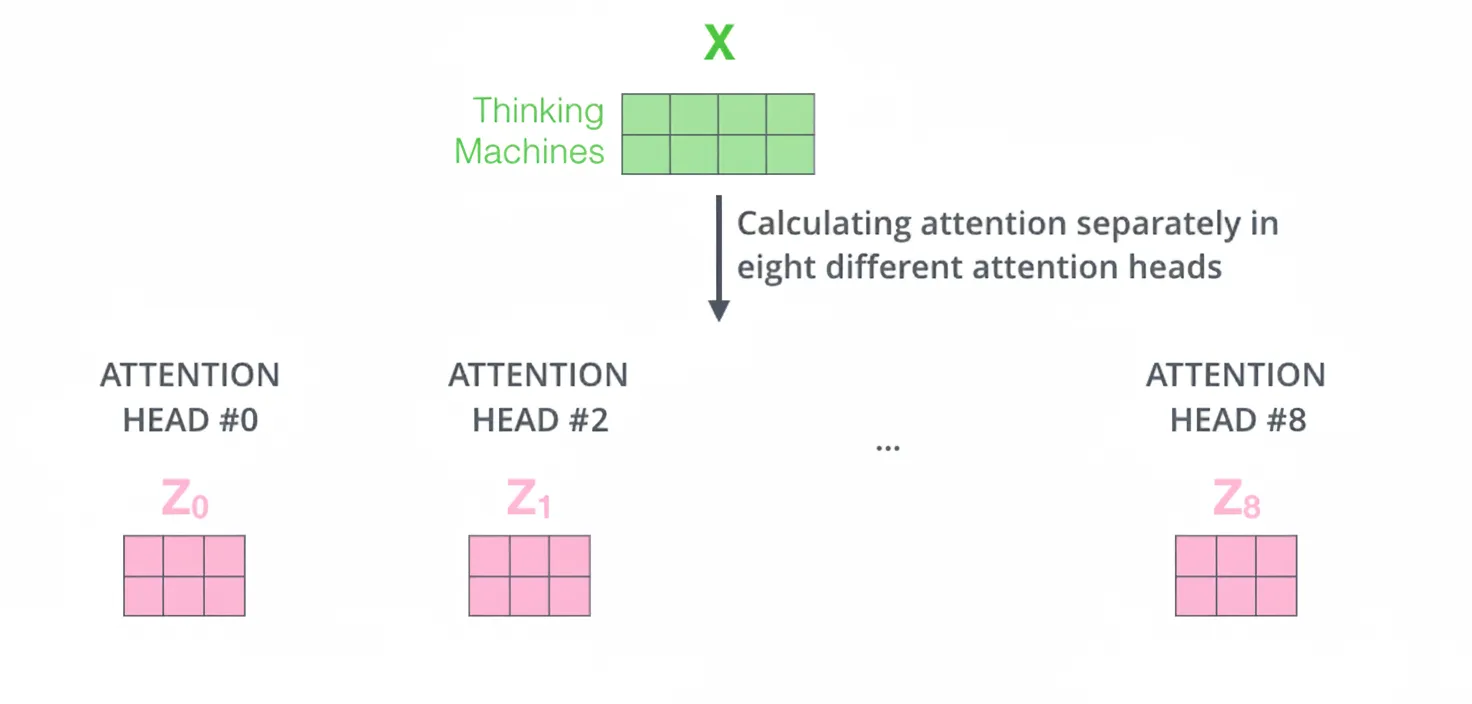
Multi-head attention enhances self-attention by performing multiple attention operations in parallel with different learned linear projections. For each head, Q, K, V are projected via distinct weight matrices, attention is computed, and the results are concatenated and projected again by a final linear transformation.
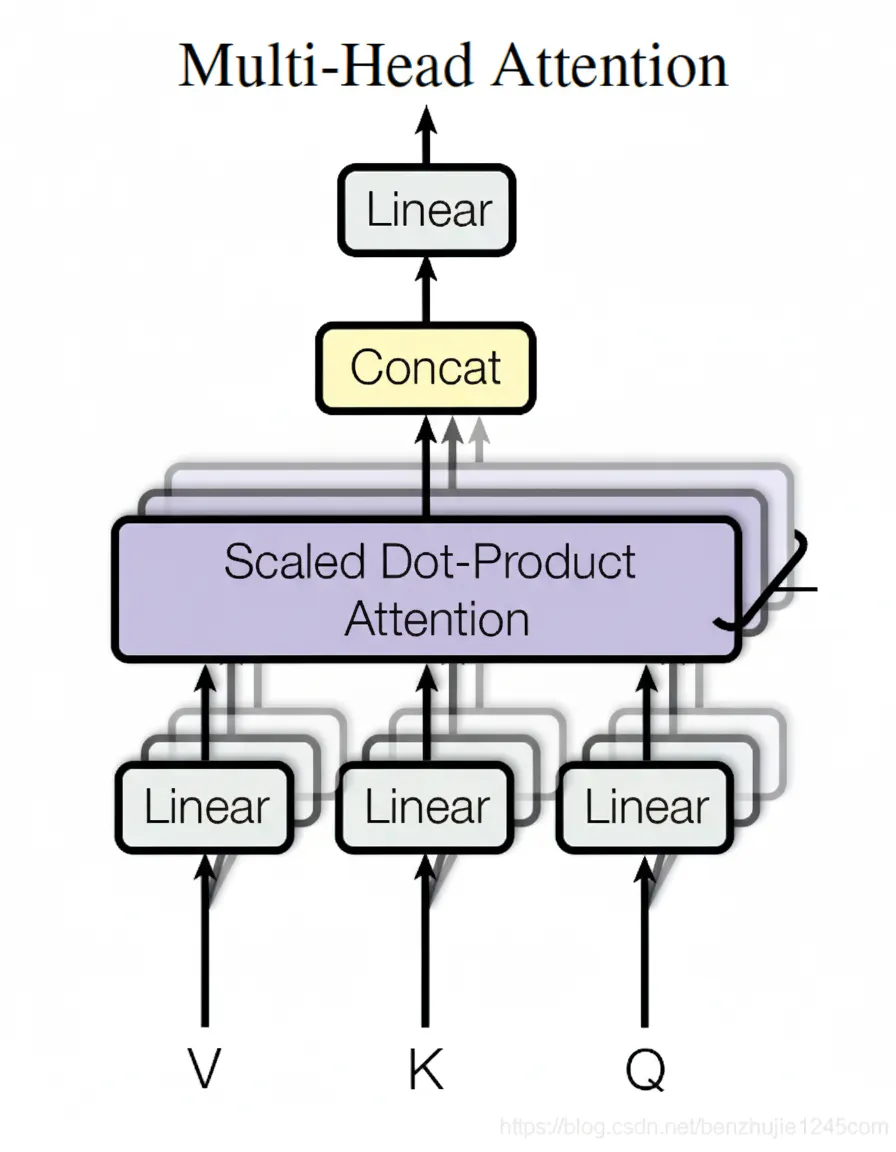
In the original paper h=8 heads are used. Each head computes attention in a lower-dimensional subspace (e.g., d_k = 64), then the head outputs are concatenated and transformed to the model dimension.
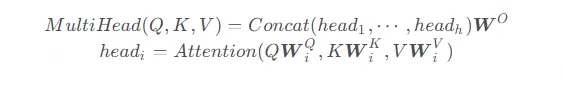
Compute attention separately with different weight matrices to obtain multiple attention outputs, then concatenate and linearly project to produce a single output matrix suitable for the feed-forward network.
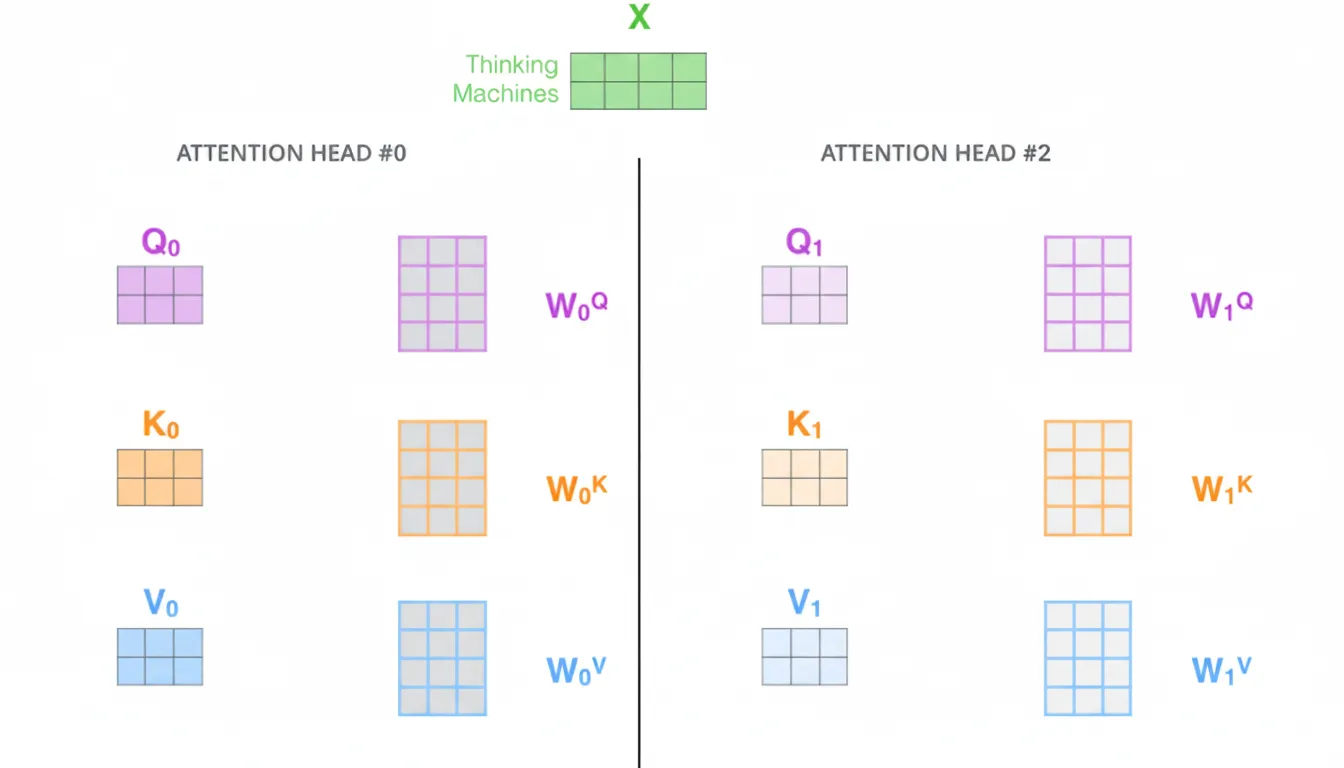
5.2 Summary
Multi-head attention maps the same Q, K, V into different subspaces and performs attention in each. This enables the model to capture various types of relationships across positions while keeping parameter counts tractable and helping generalization.
Different heads can focus on different relevant tokens; for example, when encoding "it", one head may focus on "animal" and another on "tired".
6. Position-wise feed-forward networks
The position-wise feed-forward network is a fully connected feed-forward network applied independently and identically to each position. It consists of two linear transformations with a ReLU activation in between:
The input and output dimensions are the model dimension (e.g., 512). The inner-layer dimensionality is typically larger (e.g., 2048 in the original paper).
7. Residual connections and layer normalization
Each sublayer in both encoder and decoder (self-attention, encoder-decoder attention, and FFN) has a residual connection followed by layer normalization. Each sublayer output is: LayerNorm(x + Sublayer(x)).
This pattern applies across encoder and decoder layers. To facilitate residual connections, the output dimensionality of embeddings and all sublayers must match the model dimension.
8. Positional encoding
The model needs a way to represent token order. Transformer adds a positional encoding vector to each input embedding. These positional vectors follow a deterministic pattern that allows the model to infer relative positions.
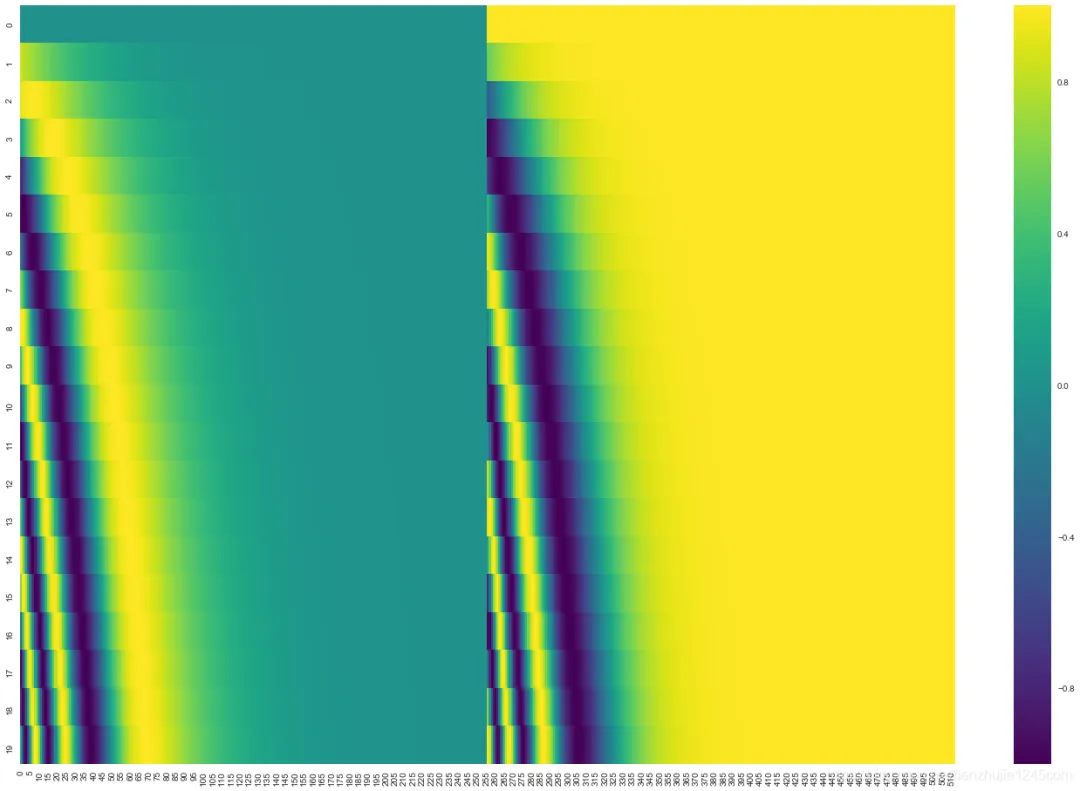
If the embedding dimension is 4, the positional encodings look like this:
The positional encoding uses sine and cosine functions of different frequencies:
PE(pos,2i) = sin(pos / 10000^(2i/d_model)) PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
These functions let the model easily learn to attend to relative positions. Note that some reference implementations interleave sine and cosine differently, but the key property is that the encodings generalize to longer sequences than seen during training.
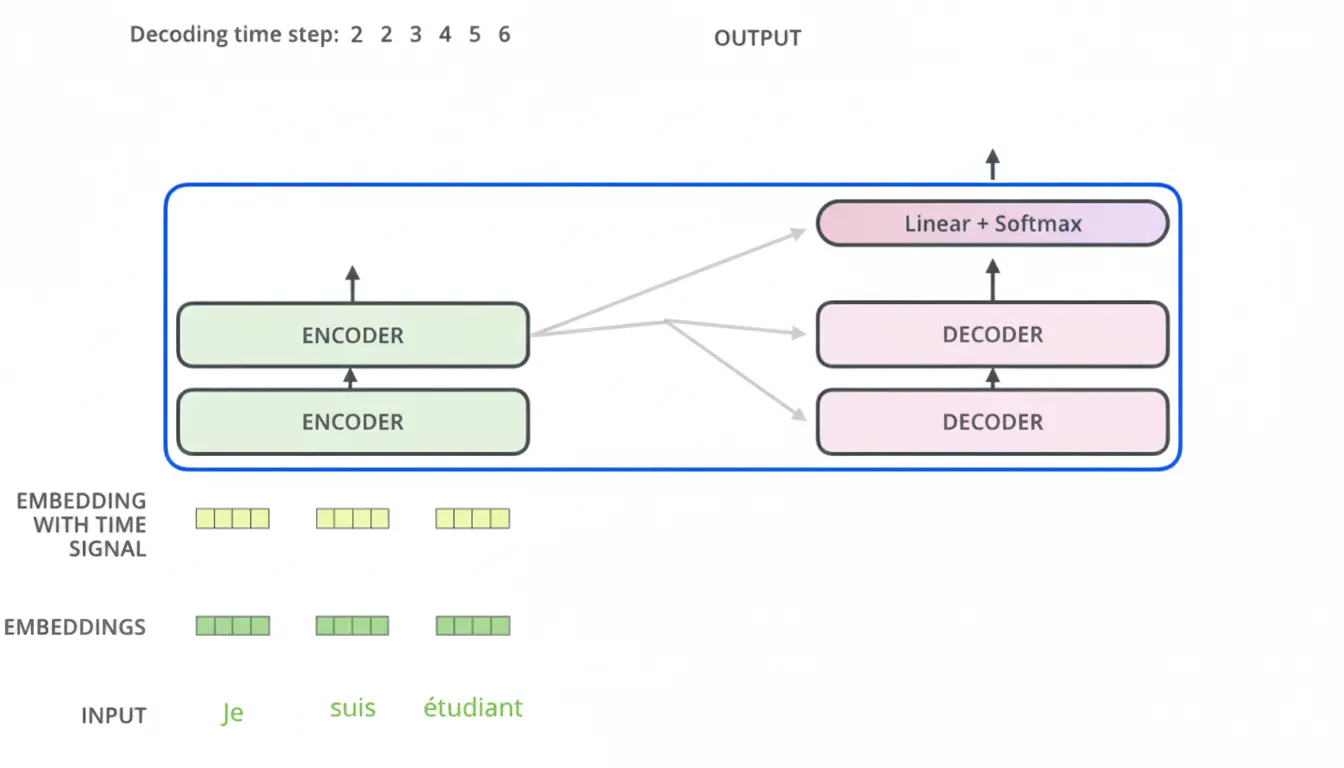
9. Decoder
The encoder outputs Key and Value vectors that are used by each decoder layer's encoder-decoder attention to help the decoder attend to appropriate input positions. Decoding proceeds one time step at a time, producing one output token per step. Each output token is fed as input to the next decoding step (with positional encoding applied to decoder inputs). The encoder-decoder attention builds Query from the decoder and Key/Value from the encoder outputs.
10. Masks
Masks hide certain positions so they do not affect attention scores. Two masks are used: padding mask and sequence mask.
10.1 Padding mask
Input sequences in a batch may have different lengths, so shorter sequences are padded with zeros. These padding positions are meaningless and should not receive attention. In practice, padding positions are assigned a large negative value (negative infinity) before the softmax so their attention weights become approximately zero.
10.2 Sequence mask
Sequence mask prevents the decoder from attending to future positions. At decoding step t, the model should only depend on outputs up to t-1. Implement this by applying an upper-triangular mask (with zeros in the allowed lower triangle and negative infinity elsewhere) to block attention to future positions.
For decoder self-attention, both padding mask and sequence mask are applied (addition of the two masks). For other attention layers, only padding mask is typically needed.
11. Final linear and softmax layers
The decoder output at each position is a float vector. To convert it to a token, pass it through a linear layer to produce logits, then apply softmax to obtain a probability distribution over the vocabulary.
11.1 Linear layer
A simple fully connected layer maps the decoder output vector to the vocabulary-size logits vector.
11.2 Softmax
Softmax converts logits into probabilities. The token with the highest probability is selected as the output for that time step.
12. Embedding sharing
The original paper mentions sharing the weight matrix between the input embedding, output embedding in the decoder, and the final linear layer. If the weight matrix is shared, the embedding matrix is multiplied by sqrt(d_model) when used as input embeddings.
13. Regularization
Common regularization techniques used when training Transformers include:
- Dropout: applied to the outputs of each sublayer before residual connection and layer norm, and applied after summing embeddings and positional encodings.
- Label smoothing: used for classification/sequence prediction targets during training.
References
- Original paper: "Attention Is All You Need" (Vaswani et al., 2017)
- Illustrated reference: Jalammar's visual guide to the Transformer (English)







