Autonomous driving, smart manufacturing, and surveillance applications require object detection for machine vision, which depends on AI modeling. The current goal is to improve detection models and simplify their development.
Background: models for object detection
Over the years, many AI models have been introduced for detection tasks, including YOLO, Faster R-CNN, Mask R-CNN, and RetinaNet. These models detect image or video signals, interpret objects, and make predictions. Recently, transformer-based models have emerged as promising solutions for object detection. It is useful to understand how they work and what advantages they offer compared with traditional models.
Object detection in machine vision
The human visual system sees objects and rapidly determines size, color, and depth. The brain filters background information and focuses on foreground objects to identify what they are, for example distinguishing a moving person from a stationary animal or a fire hydrant. Ideally, an AI model behaves similarly: it must capture important target objects, filter background clutter, classify objects, and predict what each detected object is based on its training.
Alexander Zyazin, senior product manager for automotive at Arm, noted that machines today can "see" through image sensors and lenses. Those sensors and lenses feed an image signal processing ISP module on the SoC, which cleans the image to meet machine vision requirements. The ISP output is then passed to accelerators or general-purpose CPUs for additional preprocessing and postprocessing.
Design requirements differ by use case. In surveillance and factory environments, machine vision can support use cases such as people counting to improve planning or detect defects on production lines. In automotive applications, machine vision is used for advanced driver assistance systems ADAS, where inputs from multiple sensors enable single functions such as automatic emergency braking or lane-keeping assist.
Advances in technology are enabling autonomous vehicles where all inputs come from sensors without human intervention. That approach requires many sensors around a vehicle, producing large volumes of data that must be managed and processed with very low latency. From both hardware and software perspectives, this creates a highly complex system design.
Transformer architecture
New transformer-based detection models have been introduced in recent years, including Oriented Object Detection with Transformer O2DETR and DEtection TRansformer DETR. Compared with traditional models such as Faster R-CNN, transformer approaches offer several advantages, including a simpler design. This article uses Meta's DETR 2020 to illustrate how transformer models operate. Developers can also use DETR training code for experimentation.

Figure 1: The DETR transformer compares its predictions with ground truth. When there is no match it produces "no object". Matches validate objects. Source: "End-to-End Object Detection with Transformers", Facebook AI.
Most object detection models make initial predictions and then refine them to produce final outputs. DETR uses a single-stage, end-to-end detection pipeline with transformer encoding and decoding. Two key DETR components are: (1) a set-based prediction loss that enforces matching between predictions and ground truth, and (2) an architecture that predicts a set of objects and models relations among them. Ground truth denotes the actual objects on the ground, as shown in the left image of Figure 1. If the ground truth is not checked, a poorly designed algorithm could predict two different birds or a single two-headed bird.
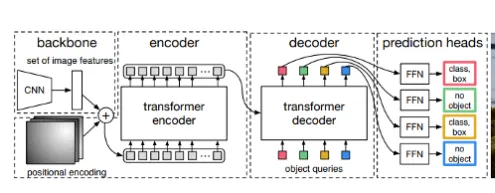
Figure 2: DETR transformer model. Source: "End-to-End Object Detection with Transformers", Facebook AI.
The human brain recognizes objects by processing image information against prior knowledge. Machine vision must learn from data and convert images into numerical representations. Convolutional neural networks CNNs are commonly used to extract features. DETR employs a conventional CNN backbone to obtain features, which are then processed by the transformer encoder and decoder. The output is passed to a shared feedforward network FFN that predicts either an object detection or "no object".
DETR does not process anchor boxes in sequence; instead, it uses an end-to-end approach and processes data in parallel. DETR considers global context and starts making predictions, comparing small regions against ground truth. If DETR "sees" a bird head and finds the same head in the ground truth, then it identifies a match, as shown by the yellow box in Figure 1. Otherwise it outputs "no object", as shown by the green box.
DETR also handles overlapping objects without relying on anchor boxes or non-maximum suppression.
Traditional object detection models use anchor boxes to localize candidate objects and non-maximum suppression to select the most confident predictions when multiple overlapping detections occur. By avoiding these additional steps, DETR simplifies the detection pipeline.
AI deployment and optimization for different applications
Object detection for machine vision requires AI models and algorithms to run on AI hardware such as AI chips, FPGAs, or modules. These devices are commonly called AI engines. After initial training, models are deployed on appropriate hardware to perform inference and make predictions or decisions. It is important that hardware development keeps pace with innovations in AI models.
Cheng Wang, chief technology officer and senior vice president of software and architecture at Flex Logix, explained that if the only requirement is object detection, non-transformer models like YOLO may be sufficient. However, transformer models that began as classification and detection tools are now essential for generative AI and generative visual tasks. These new operations were not considered in legacy AI hardware. Wang argued that adaptive hardware such as eFPGA is needed because it has software-level adaptability to keep up with evolving transformer models, providing flexibility.
He added that strong performance today is not sufficient; architectures need to be future oriented.
The use of different AI types is increasing across many domains. Sailesh Chittipeddi, executive vice president and head of embedded processing, digital power, and signal chain solutions at Renesas, noted in a recent panel that by 2025 about 75 percent of data will come from the network edge and endpoints rather than the cloud. Therefore, most AI activity occurs at the edge. Another statistic he cited is that about 90 percent of data from devices entering enterprises is discarded. The key question is where to intercept and make device-generated data useful, and that point is the edge. The ability to predict what occurs at network endpoints and to act on that insight can make a significant difference.
When thinking about compute, common categories include microcontrollers, microprocessors, CPUs, and GPUs. Recent attention has focused on GPUs and large language models such as GPT-3 and GPT-4. However, these are large models and most datasets do not require such massive compute. Edge workloads usually involve much less data but demand extremely low latency, security, local processing, and the ability to make data actionable.
This shift is expanding compute distribution beyond traditional markets. The growing volume of AI-generated data and the demand for faster results are driving the change.
Alex Wei, vice president of marketing at Winbond, observed that while traditional markets like networking, PCs, and ERP will continue to grow, new applications are emerging that will drive the next era. These applications require more components and higher density, and they place higher demands on memory. Neural processing consumes significant memory resources, and this is only the beginning of the requirements designers must address.
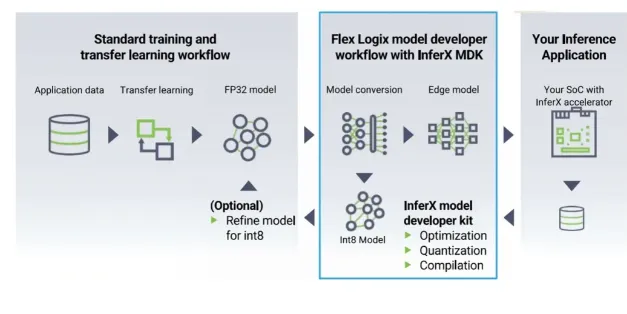
Figure 3: DETR deployment using the InferX compiler. DETR is divided into 100 layers. The InferX compiler can maximize fast SRAM access, minimize slow DRAM access, and generate configuration bits for running each layer. Source: Flex Logix.
Machine vision and AI interact in multiple ways. Zyazin said machine vision output is fed to AI engines to perform counting, object recognition, and decision making. AI also improves image quality through AI-based denoising, which supports subsequent decisions. For example, in automotive applications the combination of AI and machine vision can identify speed limit signs earlier and adjust speed accordingly.
In safety-critical cases, such as autonomous driving, what happens when an AI model receives contradictory signals from faulty sensors? The conservative approach is to favor safety. Thomas Andersen, vice president of AI and machine learning at Synopsys, said the appropriate response depends on the application and the severity of potential system failures. For that reason, multiple systems are often used to double- or triple-check information. If sensors conflict it can be difficult to decide. For example, if radar detects an object but a camera does not, a vehicle may choose to brake automatically. That behavior can prevent accidents but may also cause false braking, which can itself be hazardous. There is no perfect solution, and humans also make errors.
While AI models are improving overall, accuracy in object detection and prediction remains critical. Amol Borkar, director of product management and marketing for Tensilica Vision and AI DSP at Cadence, noted that acceptable false positive rates depend on the application. In consumer applications, misclassifying a person as a sofa may be tolerable. In automotive or medical contexts, incorrect classification of a pedestrian or misdiagnosis could be serious or fatal. Advances in AI are improving the ability to identify complex patterns in imaging data and to provide quantitative assessments rather than qualitative judgments.
Borkar also observed that AI improvements increase computational requirements, such as processing many convolutions and neural network layers. Running AI models effectively requires large amounts of synthetic data for training and validation. Additionally, modifying perception stacks to use event camera data can provide very high sensitivity to minimal motion, improving system accuracy in some scenarios. As with other AI approaches, this method requires substantial training and validation data before deployment.
Security considerations
High-quality data is essential for good outcomes, and protecting data along with the systems that process and store it is equally important.
Ron Lowman, strategic marketing manager at Synopsys, said machine vision systems must be protected at all times. With AI, security is imperative. Traditional hardware threat analysis focused on bad actors and their threat vectors, but AI can multiply attack vectors and the number of devices under threat, making security even more necessary. For many years, security was implemented primarily in software because it was less costly, but software-only measures are insufficient. As a result, hardware root-of-trust IP and security standards are being adopted. PCIe and Bluetooth provide relevant examples. For Bluetooth, voluntary standards exist to encrypt data but adoption has been limited due to cost. The industry is gradually improving. For PCIe, a new standard introduced security to the communication interface, prompting rapid changes in interface IP requirements.
Andy Nightingale, vice president of product marketing at Arteris, agreed that security is essential for machine vision. These systems often handle sensitive data and processes, such as surveillance footage, medical imaging, or autonomous vehicle control, making security particularly important.
Nightingale outlined four critical security areas for machine vision applications:
- Data privacy. Machine vision systems often handle large volumes of data, including sensitive personal or commercial information. Protecting that data from unauthorized access or disclosure is essential. Measures include encryption, access control, and data anonymization.
- System integrity. Machine vision systems can be vulnerable to attacks that manipulate or disrupt operation. Protecting system components and data from tampering or intrusion is important. Measures include secure boot, system hardening, and intrusion detection.
- Authentication. Systems depend on sensors, cameras, and other devices that can be spoofed or impersonated. Ensuring device authentication enables the system to detect and prevent unauthorized access. Measures include biometric authentication, device certificates, and network segmentation.
- Compliance. Machine vision systems may be subject to regulations or industry-specific requirements related to security and privacy. Ensuring that system design and operation comply with relevant rules is critical. Measures include risk assessment, audit trails, and data retention policies.
Nightingale added that industry standards such as platform security architecture PSA should be used during SoC design, and that security must be addressed throughout deployment and operation. With appropriate security measures, machine vision systems can be used effectively while protecting data, methods, and individuals.
Looking ahead
As AI models evolve, they will become more efficient, as seen with transformer-based approaches. Developers will need to balance software and hardware choices in future designs. Design considerations include flexible hardware, conflict management, accuracy, and security.
Lowman said future architectures will require a system-level view of machine vision. Tradeoffs such as system cost, memory availability in disaggregated architectures, on-chip versus off-chip memory bandwidth, processor counts and types, bit widths for each AI stage, and many other parameters must be considered. These tradeoffs can only be optimized with sophisticated tools and configurable, optimized IP, whether memory, interface, security, or processor IP.
As new AI and generative models emerge, machine vision will expand into new applications. Andersen of Synopsys noted several major directions: cloud computing to scale deep learning solutions, automated machine learning AutoML architectures to improve ML pipelines, transformer architectures to optimize computer vision, and integration of computer vision techniques into mobile and edge devices.
Additional reporting by Ann Mutschler and Ed Sperling.







