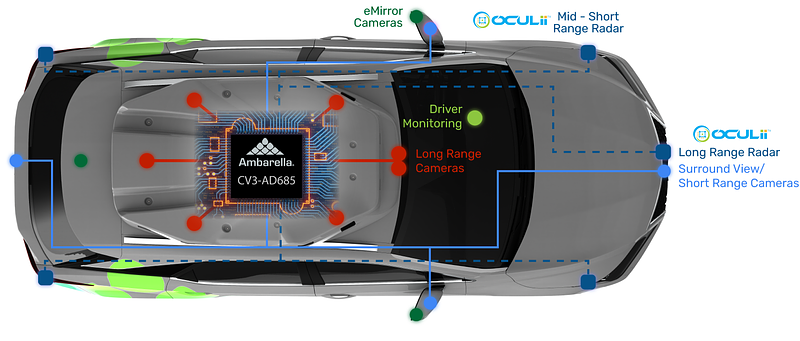
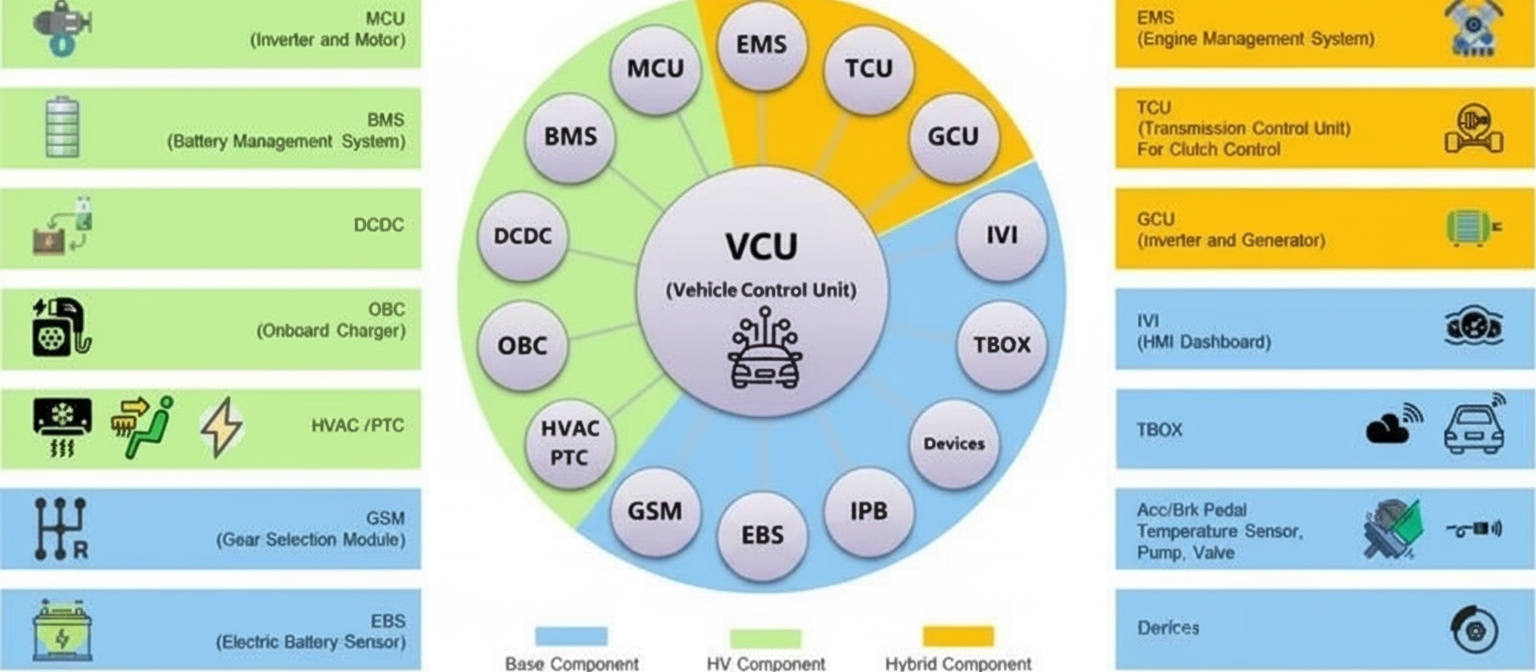
Overview
Autonomous driving systems require accurate perception and understanding of obstacles in the surrounding road environment. 3D obstacle detection provides object coordinates, sizes, orientations, and velocities in a 3D coordinate frame, which supports planning and decision making to avoid collisions and select appropriate trajectories and driving strategies.
In recent years, low-cost pure-vision 3D obstacle detection has attracted increasing attention compared with higher-cost radar-based solutions. Although production vehicles with driver assistance often use multiple surround-view cameras, early pure-vision approaches typically fused monocular 3D detections from multiple cameras in postprocessing. That led to extensive logic operations and challenges handling objects truncated across camera views.
Since Tesla's AI-Day introduced the bird's-eye-view perception concept, end-to-end fused surround-view 3D perception has become a focus for deployment. At the same time, researchers from Houmo Intelligent together with the University of Sydney, ETH Zurich, and the University of Adelaide proposed 3D point position embedding (3DPPE). This method addresses inconsistencies between image and anchor position encodings in Transformer-based surround-view 3D object detection and reduces false positives along camera rays that complicate postprocessing. 3DPPE improves performance over PETR-v1/v2 and StreamPETR and was accepted to the ICCV2023 computer vision conference.
Method and Architecture
Figure 1 shows the 3DPPE architecture. The model is based on a Transformer backbone. The input is surround-view images. After backbone processing, image features are passed to a depth head to produce depth predictions. Combined with camera intrinsics and extrinsics, the depth predictions yield a 3D point cloud. This 3D point cloud is fed into a 3D point encoder to construct positional encodings for the image features. Meanwhile, randomly initialized 3D anchors are processed by the same shared 3D point encoder to construct initial target index features. The image features, image positional encodings, and initial index features are then passed to the decoder to produce 3D detection boxes for the surround-view system.
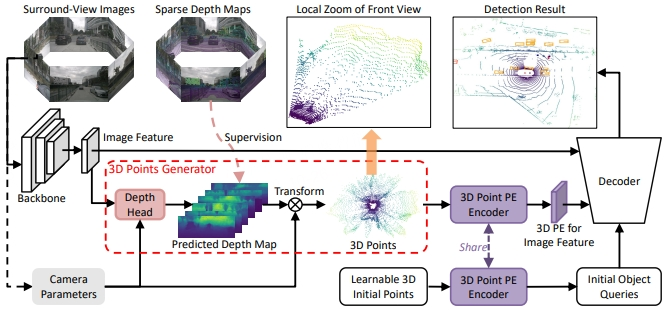
Figure 1. 3DPPE framework diagram
By incorporating explicit depth information when constructing image positional encodings, 3DPPE aligns positional priors more closely with the physical distribution of the real world, which effectively reduces false positives along camera rays. The following figure illustrates the difference: prior 3D camera-ray encodings could not model the true physical depth of objects (Figure 2.a), whereas 3DPPE uses depth points that follow the physical distribution, where depth points are the intersections between camera rays and vehicle surfaces (Figure 2.b). In addition, the improved image positional encodings share the same source distribution as the anchor points, yielding better performance.
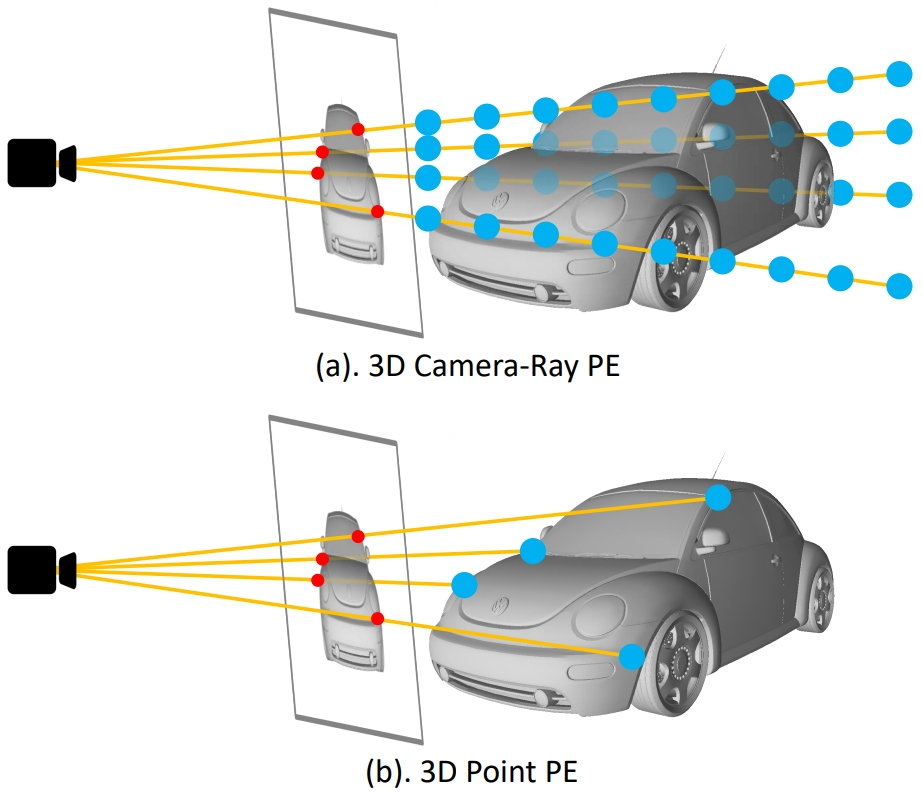
Figure 2. Illustration of 3D camera ray encoding and 3D point encoding
Experimental Results
Experiments show that the method achieves the best performance under comparable conditions on both validation and test sets.
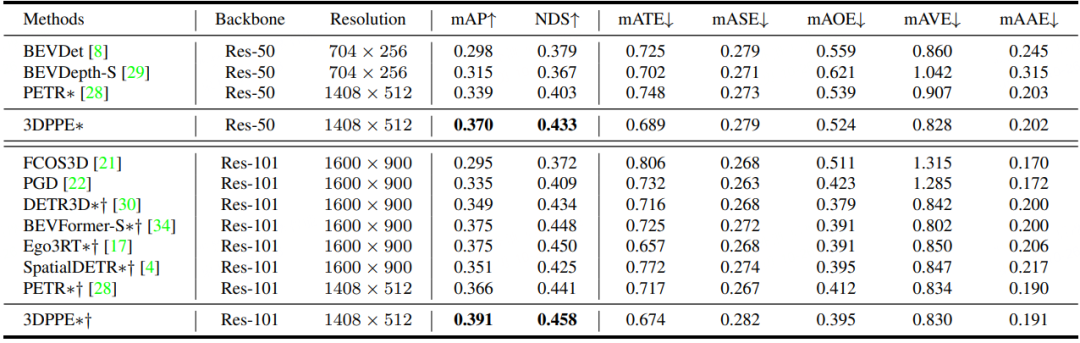
Table 1. NuScenes validation set performance
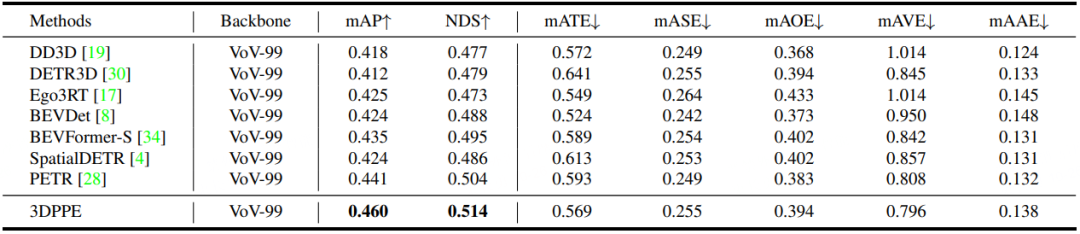
Table 2. NuScenes test set performance
The following visualization shows positional encoding similarity. 3D point encoding demonstrates stronger similarity focus.

Figure 3. Visualization of positional encoding similarity
Summary and Outlook
3DPPE explores the impact of positional encoding on surround-view 3D obstacle detection. The approach provides theoretical and technical support for deploying models on edge SoCs with limited GPU and CPU compute resources. Research into models with extreme optimization potential will be an important direction going forward.