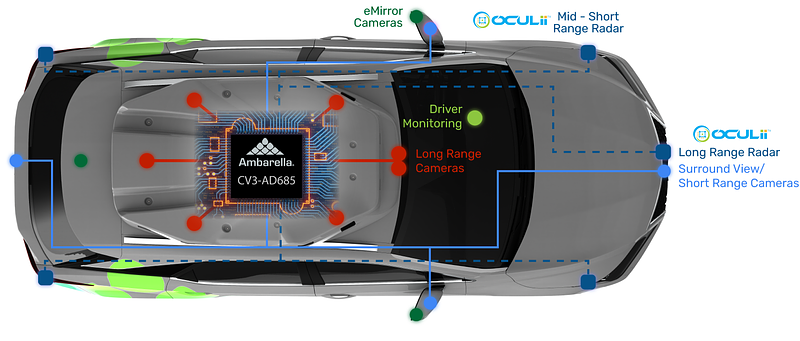
Introduction
Autonomous driving began as vehicle automation and remote control research in the early 20th century. In the 1980s and 1990s, advances in computer science and artificial intelligence enabled significant progress, with universities and research institutes developing prototypes capable of limited autonomous operation. Entering the 21st century, the field accelerated as sensors, algorithms, compute power, and big data matured, leading technology companies and automakers to invest heavily in autonomous vehicles. Although technical, legal, ethical, and safety challenges remain, autonomous driving continues to advance and is expected to impact road safety, efficiency, and environmental outcomes. This article reviews the evolution of autonomous driving perception, from SLAM+deep learning to BEV+Transformer approaches.
Classic autonomous driving framework
The classic autonomous driving framework places scene understanding as the central task, commonly referred to as perception. With the rise of AI techniques, perception performance has steadily improved. To support vehicle control and environmental understanding, autonomous systems use various perception techniques. Two widely known approaches are SLAM and BEV. These allow the vehicle to estimate its position, detect obstacles, and infer their orientation and distance, providing inputs for downstream driving decisions.

Figure 1: Classic autonomous driving framework
SLAM + Deep Learning: First-generation perception
Overview
The first generation of autonomous driving perception combined SLAM algorithms with deep learning. Tasks such as object detection and semantic segmentation needed to operate in a common coordinate frame. Camera-based perception was the exception, operating in 2D image perspective space. To obtain 3D information from 2D detections required many hand-crafted sensor-fusion rules, often relying on active sensors such as radar or lidar for 3D measurement. As a result, traditional perception systems typically processed data in the camera image space and used subsequent fusion steps to lift 2D observations into 3D for prediction and planning.
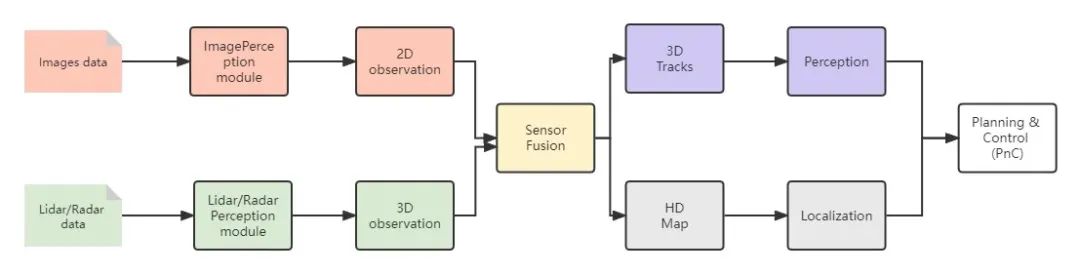
Figure 2: SLAM+DL perception framework
Problems and challenges
SLAM+DL systems revealed increasing limitations:
- The perception module sits at the upstream end of the stack. As sensor types and counts grow, fusing continuous multimodal and multi-view data and producing real-time task outputs becomes a core challenge.
- Perception consumes most of the vehicle compute. Fusing multi-view camera images with radar and lidar data strains model design and engineering. Traditional post-fusion approaches assign a separate neural network to each sensor, underutilizing cross-sensor synergy while increasing computation and latency. Sharing a single backbone across tasks often prevents each task from achieving optimal performance.
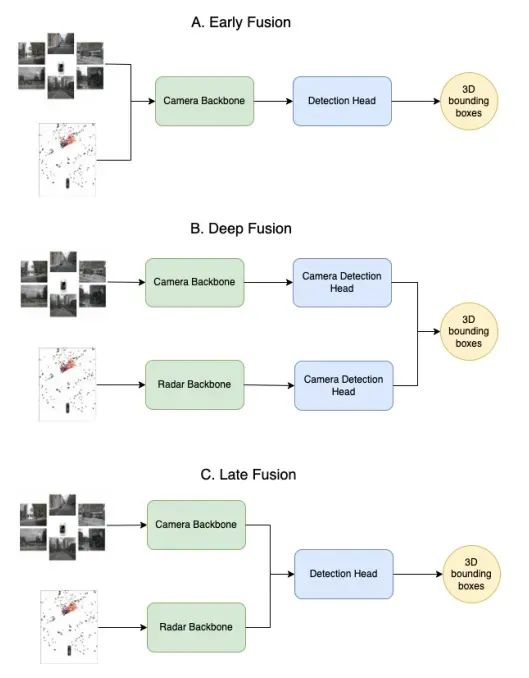
Figure 3: Example multi-modal fusion diagram
BEV + Transformer: Second-generation perception
BEV pipeline overview
BEV (bird's-eye view) approaches, often combined with Transformer architectures, have emerged as a potential solution to the limitations of SLAM+DL. BEV presents scene information from a top-down perspective, enabling unified multi-camera and multi-modal fusion. The core idea is to convert traditional 2D image perception into 3D-aware perception. For BEV perception the key is to transform 2D images into BEV features and output 3D perception frames. Efficiently obtaining robust feature representations from multiple camera views remains a challenge.
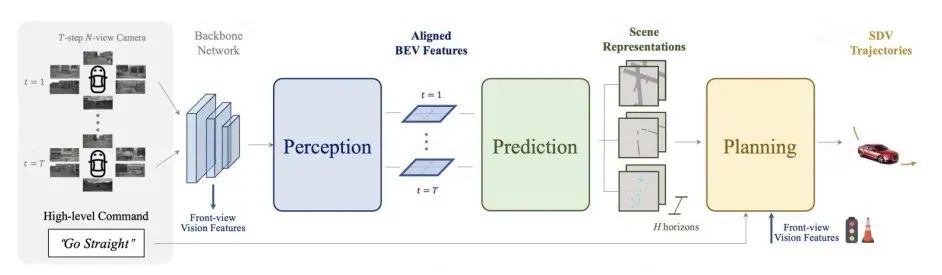
Figure 5: Pure-vision end-to-end planning framework
In BEV space, objects do not suffer perspective-caused occlusion and scale issues that complicate 2D detection, which benefits detection performance. BEV also aids perception fusion and enables a consistent data-driven transition from vision-only to multi-sensor fusion solutions, reducing development overhead.
BEV technical approaches
BEV research is primarily driven by deep learning. Based on how BEV features are organized, mainstream methods follow distinct architectures.
Bottom-up vs. Top-down
Bottom-up methods follow a 2D-to-3D pipeline:
- Estimate per-pixel depth in the 2D view, then use camera intrinsics and extrinsics to project image features into BEV space.
- Fuse features from multiple views to form BEV features.
Classic examples include LSS (Lift, Splat, Shoot), which builds a simple pipeline:
- Project 2D camera images into 3D scene space.
- Collapse the 3D scene from a top-down perspective to form BEV imagery.
The bottom-up core steps are:
- Lift — estimate depth distributions for sampled image features to obtain view frustums containing image features.
- Splat — use camera parameters to distribute frustum points into a BEV grid and aggregate contributions per grid cell to form BEV feature maps.
- Shoot — apply task heads to BEV features to produce perception outputs.
Algorithms such as LSS and BEVDepth optimize on this framework and are foundational BEV methods.
Top-down methods adopt a 3D-to-2D pattern:
- Initialize features in BEV space.
- Use a multilayer Transformer to interact BEV queries with each image feature, producing corresponding BEV features.
Transformer models, introduced in 2017, use attention mechanisms to capture relationships across elements, enabling global context modeling not limited by convolutional receptive fields. After success in NLP, Transformers were applied to computer vision tasks. The top-down approach leverages Transformer global attention to query and aggregate information from multiple perspective images into BEV feature maps. Tesla adopted a top-down approach in its FSD Beta vision module and discussed BEVFormer concepts during AI Day.
Vision-only vs. Multi-sensor fusion
BEV is a broad algorithm family. One branch emphasizes vision-only perception, built on multiple cameras; another branch fuses lidar, radar, and cameras. Many autonomous driving developers prefer fusion methods; Waymo is a notable example. From the input signal perspective, BEV solutions split into vision-centered and lidar-centered approaches.
BEV with cameras
Camera-based BEV transforms multi-view image sequences into BEV features for tasks like 3D detection or BEV semantic segmentation. Compared to lidar, vision provides richer semantic cues but lacks precise depth. Training camera-based DNNs requires annotated data identifying object types in images. Unknown object types or poor model generalization can cause failures.
To mitigate this, occupancy networks shift the perception target: rather than focusing on classification, they model whether space is occupied. Obstacles are represented as 3D voxels. This representation is robust regardless of object class, helping avoid collisions. Tesla has been exploring a transition from BEV to occupancy networks, moving from 2D grids to 3D voxel representations. Both aim to represent space occupancy but use different primitives: 2D grid cells in BEV versus 3D voxels in occupancy networks.
In BEV perception, models typically estimate occupancy probabilities per grid cell and use softmax to normalize class probabilities, selecting the highest-probability class per cell to produce the final occupancy map. Classes often include static elements (driveable area, road, lane, building, vegetation, parking, traffic lights, static objects) and dynamic objects (pedestrians, cars, trucks, traffic cones).
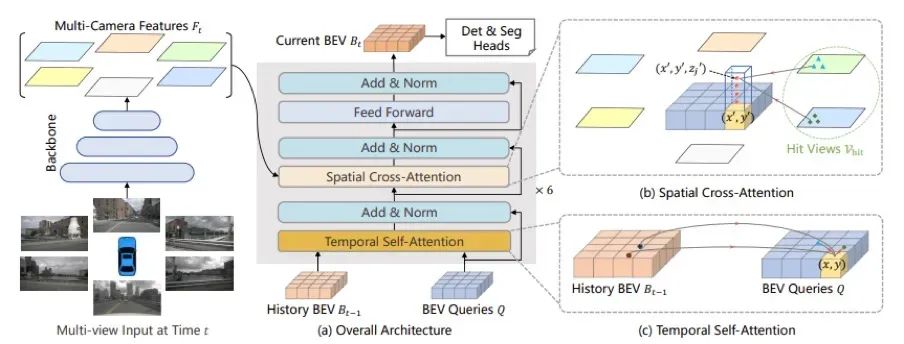
Figure 7: BEVFormer pipeline
BEVFormer workflow:
- Extract multi-scale features from surround-view images using a backbone and neck module (e.g., ResNet-101-DCN + FPN).
- An encoder module, including temporal self-attention and spatial cross-attention, transforms surround-view image features into BEV features.
- A deformable-DETR-like decoder completes 3D object detection classification and localization.
- Define positive and negative samples with Hungarian matching and optimize using Focal Loss + L1 Loss as the total loss.
- Compute classification and regression losses, backpropagate, and update network parameters.
BEVFormer aggregates spatiotemporal information using Transformer attention and time structure. It uses predefined grid-like BEV queries to interact with spatial and temporal features, effectively capturing object spatiotemporal relationships and producing stronger representations for detection and scene understanding.
BEV with multi-sensor fusion
Fusion approaches aim to integrate data from cameras, lidar, GNSS, odometry, HD maps, CAN bus, and other sources. This leverages each sensor's strengths to improve environmental perception and understanding. In many fusion pipelines lidar remains critical because it directly measures distances and produces high-quality depth or point-cloud data that mature algorithms can consume, reducing development effort. Lidar also performs better than cameras in low-light or adverse weather, whereas cameras can be heavily affected. Radar retains value in specific roles and may regain importance as algorithms evolve. The fusion objective is to combine multi-sensor data to achieve robust perception across diverse and challenging conditions, improving safety and reliability.
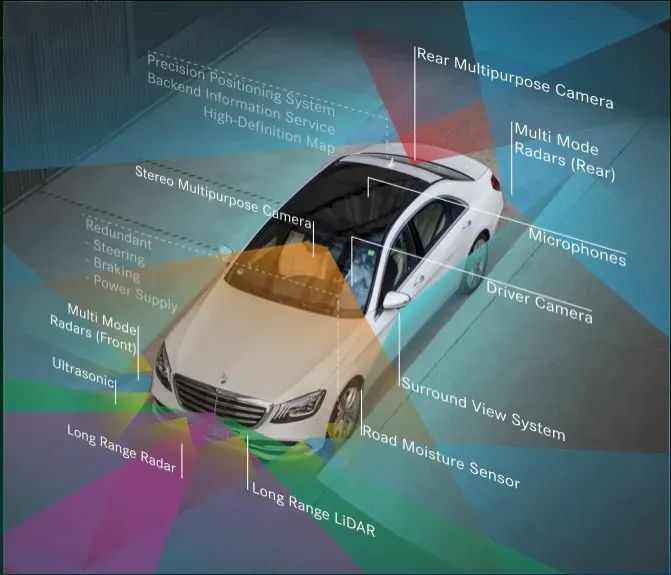
Figure 8: Example sensor suite used in intelligent driving
Why BEV + Transformer for the next generation?
Why BEV perception?
Autonomous driving is fundamentally a 3D or BEV perception problem. BEV provides comprehensive scene information that helps vehicles perceive the environment and make accurate decisions. In 2D perspective views, occlusion and scale distortions occur; BEV effectively addresses these issues. Compared with models operating on frontal or perspective views, BEV better recognizes occluded vehicles and directly produces representations useful for prediction, planning, and control. BEV also facilitates multimodal fusion because different sensors can be expressed on the same plane, simplifying fusion and downstream use.
Further reasons to adopt BEV for camera perception:
- Operating directly in BEV allows camera-based perception results to integrate naturally with radar or lidar outputs already represented in BEV. BEV outputs are also straightforward for downstream prediction and planning modules to use.
- Manually elevating 2D observations to 3D with hand-crafted rules is not scalable. BEV enables earlier, fully data-driven fusion pipelines.
- In vision-only systems with no radar or lidar cues, BEV perception is effectively required because no other 3D cues exist for view transformation. BEV improves accuracy and stability and enables multimodal fusion and end-to-end optimization.
Why combine BEV with Transformer?
BEV+Transformer became popular because it aligns with a "first principles" view: driving should emulate human-like scene understanding. BEV is a natural representation for the driving domain, while Transformers' global attention makes view transformation more tractable. Each target location can access any source location with equal attention strength, overcoming convolutional locality limitations. Compared with CNNs, visual Transformers offer advantages in interpretability and flexibility. As research and engineering progress, BEV+Transformer methods have moved from academic interest toward production deployment.
Research trends for BEV+Transformer
- Data collection and preprocessing: BEV projection requires extensive data collection and preprocessing, including multi-camera fusion, data alignment, and distortion correction. Transformers need large-scale data, so obtaining high-quality datasets at scale is an important research topic.
- Model and hardware optimization: Transformers are computationally heavy, demanding large storage, compute, and bandwidth. Chip-level adaptations, backend software optimization, and cache/bandwidth improvements are necessary, alongside model compression and acceleration techniques.
- Broader sensor fusion: Current BEV systems mainly use lidar and cameras, but integrating additional sensors such as millimeter-wave radar and GPS can improve accuracy and coverage.
- Robust optimization: BEV must handle weather, lighting, occlusion, and adversarial scenarios. Strengthening algorithmic robustness is vital to improving system stability and reliability.
- Expanded application scenarios: BEV has broad applications beyond autonomous driving, including intelligent transportation, logistics, and robotics. BEV-equipped systems can improve traffic monitoring, routing, and spatial understanding in urban planning, logistics, agriculture, and mining.
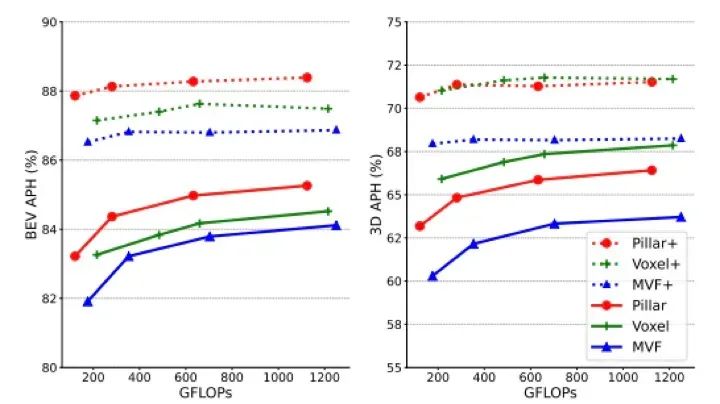
Figure 9: Model optimization performance comparison
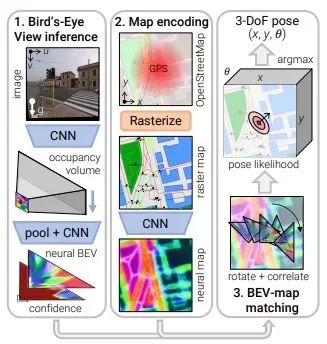
Figure 10: Expanded sensor fusion
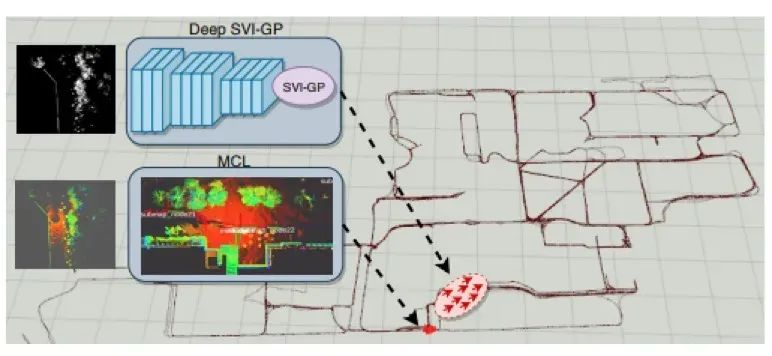
Figure 12: BEV applications in robotics
Conclusion
Industry trends indicate BEV and BEV+Transformer architectures are likely to dominate future perception systems. This shift implies that sensor and compute hardware, camera modules, and software algorithms must adapt rapidly to support BEV-based solutions. BEV extends traditional multi-channel sensor inputs to produce outputs suitable for 3D planning and control, complementing SLAM and expanding possibilities for autonomous driving. As perception methods continue evolving, more efficient and accurate techniques will drive broader adoption of autonomous driving technologies and related applications.