1. What is BEV perception?
BEV stands for Bird's-Eye-View, a top-down perspective. BEV perception algorithms offer several advantages.
First, BEV reduces occlusion. Due to perspective effects, objects in the real world are easily occluded in 2D images, so traditional 2D-based perception can only detect visible targets; occluded parts are difficult for those algorithms to handle.
In BEV space, temporal information can be fused more easily. Algorithms can use priors to predict occluded regions, effectively "inferring" whether an occluded area contains an object. Although inferred objects involve some uncertainty, they can still benefit downstream control modules.
In addition, BEV perception benefits from smaller scale variation. Feeding data with more consistent scale into a network often yields better perception results.
2. BEV perception datasets
2.1 KITTI-360
KITTI-360 is a large dataset with rich sensor information and comprehensive annotations. Data were recorded in suburban areas around Karlsruhe, Germany, covering 73.7 km of driving with over 320,000 images and 100,000 laser scans. Static and dynamic 3D scene elements were annotated using coarse bounding primitives and these annotations were projected to image space to provide dense semantic and instance labels for both 3D point clouds and 2D images.
For data collection, the station wagon was equipped with a 180° fisheye camera on each side and a 90° perspective stereo camera in front (60 cm baseline). A Velodyne HDL-64E and a SICK LMS 200 scanner were mounted on the roof in a push-broom configuration. Compared with KITTI, the additional fisheye cameras and the push-broom lidar provide a full 360° field of view; KITTI provides only perspective images and a Velodyne lidar with a vertical field of view of 26.8°. The system also includes an IMU/GPS localization system. The sensor layout of the collection vehicle is shown below.
2.2 nuScenes
nuScenes is a large dataset that provides a full autonomous vehicle sensor suite: six cameras, one lidar, five millimeter-wave radars, and GPS/IMU. Compared with KITTI, nuScenes contains more than seven times the number of annotated objects. The sensor layout of the collection vehicle is shown below.
3. Categories of BEV perception algorithms
Based on input data, BEV perception research can be grouped into three main categories: BEV Camera, BEV LiDAR, and BEV Fusion. The diagram below summarizes the BEV perception family. Specifically, BEV Camera refers to vision-only or vision-centric algorithms that perform 3D detection or segmentation from multiple surround cameras; BEV LiDAR refers to detection or segmentation tasks using point cloud input; BEV Fusion covers fusion mechanisms that combine multiple sensor inputs such as cameras, lidar, GNSS/IMU, odometry, HD maps, and CAN bus data.
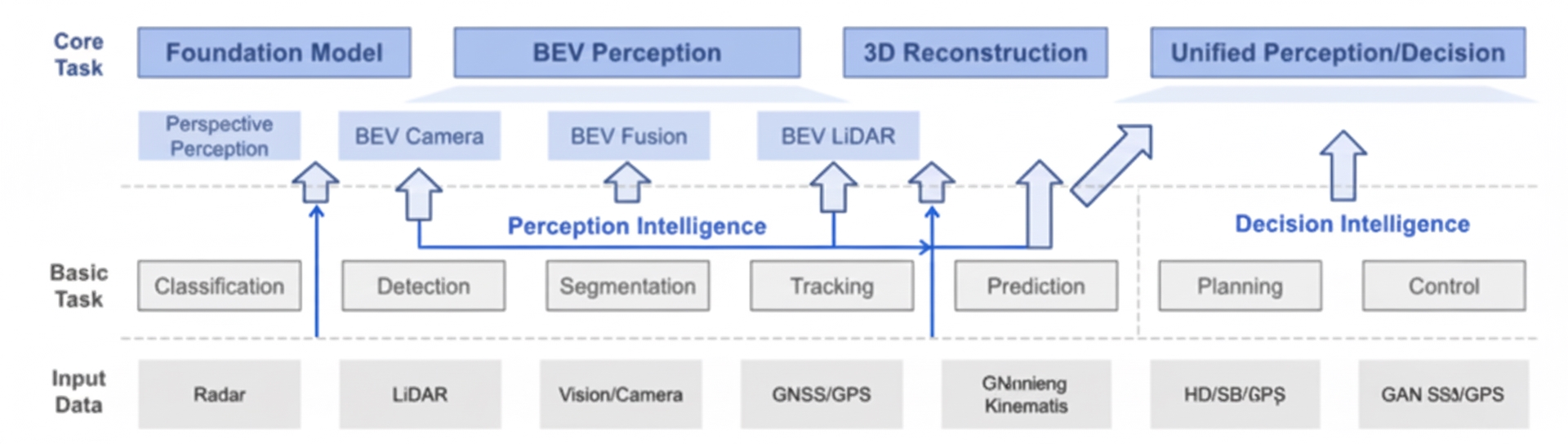
Figure 1: Basic perception algorithms for autonomous driving
As shown, core perception tasks for autonomous driving (classification, detection, segmentation, tracking, etc.) can be organized into three levels, with the BEV perception concept in the middle. Depending on the combination of sensor inputs, core tasks, and product scenarios, a BEV method can take different forms. For example, M2BEV and BEVFormer belong to the visual BEV direction and perform multiple tasks including 3D object detection and BEV map segmentation. BEVFusion designs a fusion strategy in BEV space and performs 3D detection and tracking using both camera and lidar inputs.
A representative in the BEV Camera category is BEVFormer. BEVFormer extracts features from surround camera images and learns to transform these image features into BEV features (the model learns how to map features from the image coordinate system to the BEV coordinate system), enabling 3D object detection and map segmentation with state-of-the-art results.
3.1 BEVFormer pipeline
- Backbone + neck (ResNet-101 + DCN + FPN) extract multi-scale features from surround images.
- An encoder module proposed by the paper, including Temporal Self-Attention and Spatial Cross-Attention, models the mapping from surround image features to BEV features.
- A decoder module similar to Deformable DETR performs classification and localization for 3D object detection.
- Positive and negative samples are defined using common Transformer matching (Hungarian matching). The total loss uses Focal Loss + L1 Loss with a minimum matching cost.
- Loss computation uses Focal Loss for classification and L1 Loss for regression.
- Backpropagation updates the network parameters.
BEVFusion depends on both BEV LiDAR and BEV Camera methods, typically using a fusion module to combine point cloud and image features. BEVFusion is a representative method in this area.
3.2 BEVFusion pipeline
- Given different perception inputs, apply modality-specific encoders to extract features.
- Convert multimodal features to a unified BEV representation that preserves both geometry and semantics.
- Address view transformation efficiency bottlenecks; precomputation and intermittent updates can accelerate BEV pooling.
- Apply a convolutional BEV encoder to the unified BEV features to mitigate local misalignment between different features.
- Finally, add task-specific heads to support various 3D scene understanding jobs.
4. Strengths and limitations of BEV perception
Current industry research on vision-based perception and prediction often addresses individual subproblems in image-view space, such as 3D object detection, semantic map recognition, or object motion prediction. Results from different networks are then fused via early or late fusion. This leads to linear pipelines that stack multiple submodules. Although this decomposition facilitates independent academic research, the serial architecture has several important drawbacks:
- Errors from upstream modules propagate to downstream modules. In independent subproblem research, ground truth is often used as input, so accumulated error can significantly degrade downstream performance in an integrated system.
- Different submodules may repeat feature extraction and dimensional transformations, but the serial architecture cannot share these redundant computations, reducing overall system efficiency.
- Temporal information is underutilized. Temporal data can complement spatial information to better detect occluded objects and provide more cues for object positioning. Temporal cues also help determine object motion state; without temporal information, vision-only methods struggle to estimate object velocities effectively.
Unlike image-view solutions, BEV transforms visual information from multiple cameras or radar into a bird's-eye view for perception tasks. This approach offers a wider field of view and enables parallel execution of multiple perception tasks. BEV perception integrates information in BEV space, which facilitates exploration of 2D-to-3D transformation processes.
At the same time, for 3D detection tasks BEV perception based on vision still lags behind point-cloud-based approaches. Research into visual BEV perception can reduce hardware costs: a lidar setup often costs an order of magnitude more than a camera setup. However, visual BEV approaches produce large amounts of data that require substantial compute resources.