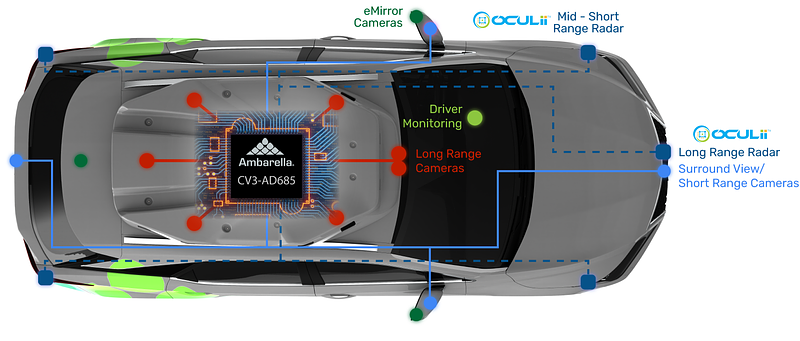
Tesla emphasizes a vision-only approach to automated driving. Human perception and cognition rely heavily on vision, and Tesla's strategy of continuously improving vision-based systems aims to replicate that aspect of intelligence.
What is FSD?
FSD refers to Tesla's Full Self-Driving system. The system integrates many AI algorithms and supporting infrastructure, including:
- Path and motion planning algorithms: embedded on the vehicle to perceive the environment, plan trajectories, and ensure safe, smooth motion.
- Environment perception algorithms: occupancy algorithms for detecting drivable space; lane and object algorithms for lane markings, object detection, and motion estimation.
- Training data infrastructure: high-performance compute centers for data processing and model training.
- Automatic labeling algorithms: label data to train perception models for scene and object recognition.
- Virtual environment simulation: synthetic generation of virtual scenes for training.
- Data engine: test software gathers real-world scenario data for a closed-loop data pipeline and label correction.
1. Path and motion planning: handling unprotected left turns
Tesla uses a planning model called Interaction Search. The approach can be summarized in five steps and relies on a tree-search process with two key modules: decision tree generation and decision tree pruning.
By prebuilding libraries of human driving behaviors and virtual driving behaviors for algorithm lookup, the method reduces computation time. The decision tree enables the system to evaluate multiple metrics and select an optimal path.
2. Environment perception: predicting road user behavior
Complex driving scenes, such as intersections with traffic from six directions and many moving and stationary participants, pose prediction challenges. Occlusion by other vehicles further increases difficulty. Tesla published a detailed architecture, Occupancy Network, to predict the behavior of traffic participants including vehicles and pedestrians.
Occupancy Network algorithm
Tesla's perception is primarily vision-based. Occupancy Networks are used to explore movable 3D space. The algorithm balances compute and memory efficiency, can model the scene in roughly 10 ms, and runs on all FSD-equipped Tesla vehicles. The general workflow produces a volumetric occupancy estimate of the scene.
Queryable outputs: after deconvolution, reconstructed objects may not perfectly match real-world sizes. Tesla uses a query step against a database of real-world examples to correct position and size before placing objects in 3D space.
Lane recognition algorithm
Traditional lane recognition uses 2D segmentation networks such as RegNet, which work well on highways and highly structured scenes. In complex urban scenarios, occlusion and insufficient training data reduce performance. Without relying on high-definition maps, Tesla uses neural models to predict and generate full lane instances and their connectivity.
The lane recognition approach borrows concepts from language models to address visual prediction problems, generating coherent lane instances and connectivity.
3. Semantic segmentation, automatic labeling, and scene simulation: predicting surrounding vehicles
Adverse conditions such as snow, fog, or sensor blind spots create significant challenges for autonomous decision making and safety. Tesla combines semantic segmentation, automated labeling, and scene simulation to improve prediction of surrounding vehicles.
Semantic segmentation
Automatic labeling
A. Lane line automatic labeling steps
B. Scene simulation
Even with large data volumes and efficient labeling tools, real-world scenarios can be too rare or complex to collect directly. Rare occurrences or highly dense crowds may be impractical to capture in sufficient quantity. Tesla synthesizes new, self-labeled scenes from collected data for additional training.
Visual simulation requires a base of labeled real-world road information and a rich asset library. The synthetic scene pipeline then composes scenes and generates annotations for model training.
In-cabin systems and multi-camera fusion
One of FSD's core technical challenges is how a vehicle understands complex dynamic scenes to ensure safe autonomous driving. A similar challenge exists for in-cabin monitoring systems such as BIVMS (Built-in Vehicle Intelligent Monitor System), where the system must accurately interpret diverse driver behaviors and provide appropriate alerts.
To improve recognition accuracy in the vehicle cabin, multi-camera vision systems are commonly used. Driver Monitoring System (DMS), Occupancy Monitoring System (OMS), and time-of-flight (TOF) sensors can be combined. Multi-sensor fusion improves algorithm robustness and data richness, supporting multi-modal applications such as 3D TOF processing, AR-HUD (Augmented Reality Head-Up Display), and in-vehicle health monitoring. This multi-camera, multi-sensor approach represents a likely evolution path for in-cabin vision systems.