AI large models for autonomous driving have gained attention. Their design focuses mainly on data generation and scenario analysis, with the ultimate goal of producing vehicle-side control commands directly from raw perception. To reach this goal, industry efforts have explored feasibility and then focused on addressing long-tail distributions and scenario recognition challenges.
Perception-based and end-to-end controller paradigms
Controller design for autonomous driving typically follows two paradigms: local perception methods and end-to-end learning methods. Perception methods rely on detecting human-defined elements such as vehicles and lane markings and require careful parameter tuning to reach acceptable performance. By contrast, end-to-end methods take raw sensor data as input and directly generate planned trajectories or control signals.
One key challenge for deploying such control systems in real vehicles is that decision and control strategies can become complex and difficult for typical passengers to understand. For passenger acceptance, safety and controllability are paramount.
This article analyzes two representative GPT-style algorithms applied to autonomous driving and compares their practical strengths and weaknesses.
ADAPT: End-to-end Transformer predictor with annotated interpretable actions
An ideal autonomous driving solution would include natural language descriptions that guide the full planning, decision, and execution pipeline, and that are easy for a passenger to understand. Providing natural language explanations and reasoning for each control/action decision can help users understand the vehicle state and the evidence supporting the vehicle's actions. In other words, generate interpretable reasoning about the vehicle behavior and use that reasoning to support driving control decisions. Language-based explanations can make the system more transparent and easier to understand.
Although attention maps and cost metrics are effective, language-based explanations are more user friendly for general passengers. ADAPT proposes a Transformer prediction architecture that provides passenger-friendly natural language descriptions and reasoning alongside vehicle control predictions. To bridge the gap between captioning and control-signal prediction, the algorithm jointly trains a driving-captioning task and a control-signal prediction task on shared video representations. By adding a text-generation head, this multi-task framework can be applied to various end-to-end driving systems.
Video captioning for driving
Related methods use natural-language video captions to describe vehicle decision and control. Early work generated sentences by filling fixed templates with detected elements, which lacks flexibility and richness. Later sequence-learning approaches used a video encoder to extract frame features and a language decoder to learn visual-text alignment. Object-level representations have been used to capture fine-grained object interactions, and two-branch convolutional encoders were developed to jointly learn content and semantics. Single-modality transformers and sparse boundary-aware pooling have been applied to reduce redundant frames. SWINBERT introduced a video transformer using sparse attention masks to reduce redundancy across consecutive frames.
Although these architectures show promising results for general video captioning, directly transferring them to driving actions can miss critical signals such as vehicle speed, which is essential in driving. The ADAPT algorithm leverages multimodal information to generate driving decision actions effectively.
Explainability in driving decisions
Learning-based driving is an active research area. Methods such as affordance learning, reinforcement learning, imitation learning, and trajectory regression have been applied. Many explainability techniques for autonomous vehicles are vision- or LiDAR-based and mainly visualize attention maps to highlight relevant image regions and support the vehicle action.
However, attention maps can include less important regions and lead to passenger misunderstanding. Bird's-eye view (BEV) constructed from onboard cameras can visualize motion information and environment state. LiDAR and high-definition maps have been used to predict agent bounding boxes and to interpret planning decisions via cost functions. Online maps built from segmentation and agent states can reduce dependency on high-definition maps.
ADAPT methodology
Directly assigning captions from upstream sensor detections does not provide obvious interpretability for vehicle-side drivers, because control decisions must be based on perception data. ADAPT explores textual explanations of vehicle control decisions by extracting video features offline from the control-signal prediction task and then constructing driving captions.
The ADAPT architecture addresses two tasks: driving caption generation (DCG) and control signal prediction (CSP). DCG takes a sequence of raw video frames and outputs two natural-language sentences: one that describes the vehicle action (for example, "The car is accelerating") and another that explains the reason (for example, "because the traffic light turned green"). CSP takes the same video frames and outputs a sequence of control signals such as speed, heading, or acceleration.
DCG and CSP share the same video encoder but use different prediction heads. For DCG, a vision-language transformer encoder generates the two sentences via sequence-to-sequence decoding. For CSP, a motion information encoder predicts the control signal sequence via a transformer-based predictor.
Video encoder
Following SWINBERT, ADAPT uses a Video Swin Transformer as the visual encoder to convert video frames into feature tokens. Given T uniformly sampled frames of size H×W×3, the video swin outputs a sequence of features FV, where C denotes the channel dimension defined by the video swin. These video features are then fed into the different transformer heads.
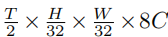
Prediction heads
The text-generation head produces two sentences describing vehicle action and the underlying reason. Video features are tokenized along the channel dimension and text inputs are tokenized and padded to fixed lengths. The two sentences are concatenated and embedded, and segment embeddings distinguish action description from reasoning. A learnable MLP projects video token dimensions to match text token dimensions. The combined video and text tokens are input to the vision-language transformer encoder, which outputs a sequence containing the action description and reasoning.
The CSP head predicts control signals such as acceleration from the video feature sequence and a corresponding recorded control signal sequence S = {s1, s2, …, sT}. CSP outputs a predicted control sequence S? = {?2, …, ?T}. Each control signal is an n-tuple corresponding to available sensor types. Video features are tokenized and a motion transformer generates S?. The CSP loss LCSP is defined as the mean squared error between S and S?.
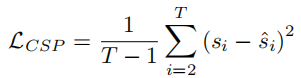
The algorithm does not predict the control signal for the first frame because dynamic information is limited in the first frame and later signals can be inferred from previous frames.
Joint training
ADAPT assumes CSP and DCG are semantically consistent at the video-representation level. Action descriptions and control signals are different expressions of vehicle action, while reasoning focuses on environmental factors that affect action. Joint training can exploit inductive biases across tasks to improve performance. The total loss is the sum of LCSP and LDCG.
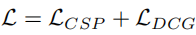
Although trained jointly, inference for each task is independent. For DCG, ADAPT generates driving captions autoregressively: starting from a [CLS] token and generating one word token at a time until a [SEP] token or maximum length is reached. After generating the first sentence, padding is applied and a second [CLS] token is connected to generate the reasoning sentence.
Language-based interpretability is important for social acceptance of autonomous vehicles. ADAPT is an end-to-end Transformer framework that uses multi-task joint training to reduce the gap between driving-caption generation and control-signal prediction, producing action descriptions and reasoning for autonomous vehicles.
BEVGPT: Generative pre-trained model for prediction, decision, and planning using BEV
Traditional autonomous driving pipelines separate perception, prediction, planning, and decision into distinct modules, with task-specific models for each. Bird's-eye view (BEV) representations are powerful for vision-centered perception because BEV accurately represents nearby traffic conditions. However, existing BEV generation methods require complex input representations and lack long-term modeling capacity, making future prediction unreliable over longer horizons.
BEVGPT is a generative self-supervised pre-trained model that integrates driving-scene prediction, decision, and motion planning into a single model. The model uses BEV images as the sole input source and produces driving decisions based on surrounding traffic. A motion planner enforces feasibility and smoothness of the planned trajectory.
The pipeline first predicts future trajectories of surrounding agents from environmental information. Predicted agent motion and map segmentation are then used to make driving decisions and plan the vehicle's future trajectory. Modular approaches can suffer from error accumulation across modules. Multi-task shared-backbone approaches reduce model size and inference cost but can suffer from negative transfer between unrelated tasks. Therefore, integrating prediction, decision, and planning into a single framework is desirable.
BEVGPT follows a two-stage training process. First, a large dataset trains the generative model. Second, online fine-tuning in a simulator adapts the model for motion-dynamics planning and accurate BEV prediction. The pretraining objective is to learn BEV generation and self-prediction for driving scenes. The model capacity enables computing future trajectory decisions within 4 seconds and predicting future scenes up to 6 seconds ahead.
Online fine-tuning and motion planner
During online fine-tuning, the pretrained generative predictor is adapted to motion dynamics and BEV accuracy. The motion planner generates smooth, dynamically feasible trajectories. An experience rasterizer provides static scene information, such as lanes and intersections, to the model. Given the static global map, the vehicle's initial world coordinates, and the conversion between world and raster coordinates, lanes and intersections can be rasterized into BEV images. After simulating one time step Δt, the next BEV ground truth is available. The model is fine-tuned for 10k steps with simulator-derived data.
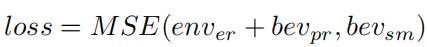
Framework details
BEVGPT focuses on predicting the ego vehicle's future positions, because drivers primarily care about whether their future trajectory will be occupied by other vehicles. Human drivers also rely on prior knowledge of the environment map, such as road structure and intersection locations. Based on this, BEVGPT keeps a minimal set of modules: decision, motion planning, and driving-scene prediction, while removing object tracking and agent-motion prediction modules from the classical pipeline.
Decision outputs are future positions of the ego vehicle over T = 4 s; the motion planner converts these into dynamically feasible, smooth trajectories. Static environment information can be obtained from a high-definition map, so the focus is on accurate prediction of dynamic objects like vehicles and pedestrians. Driving-scene prediction combines the static map and dynamic predictions.
Trajectory representation and motion planning
The model represents differential-flat outputs px and py with piecewise polynomial trajectories, commonly using fifth-order polynomials to minimize parameter jitter in subsequent motion planning. Assume the trajectory is composed of M segments with equal time interval Δt. For each dimension, the n-th segment polynomial is represented by coefficients fn = [fn,0, fn,1, fn,2, fn,3, fn,4, fn,5]T, evaluated over time Tn = nΔt for n = 0, 1, …, M-1.
Motion planning requirements include dynamic feasibility and trajectory smoothness, with a preference for minimizing control effort. Jerk (derivative of acceleration) is often used as a measure of comfort and safety. The planner minimizes jerk subject to initial state p0 and final state pM constraints, continuity between segments, and bounds on acceleration and jerk. The optimization is solved iteratively, using predicted path points from the pretrained causal transformer as initial positions for each segment.
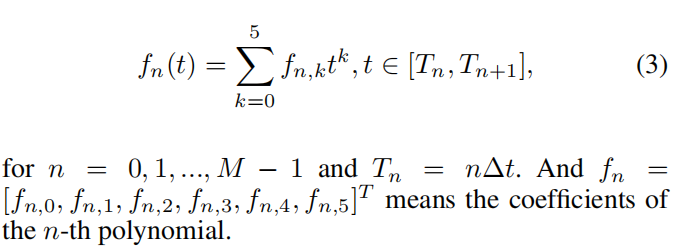
Model training and loss
Training extracts vehicle pose, semantic BEV images, and static environment map images from datasets. Scenarios shorter than 24 seconds are removed. The ego vehicle's future target positions are used as labels for decision training. Each training sample contains the vehicle position, current BEV image, next BEV image, and next environment map image.
BEVGPT is pretrained for 20 epochs using mean squared error to improve decision and prediction accuracy. The loss balances decision MSE and BEV prediction MSE:
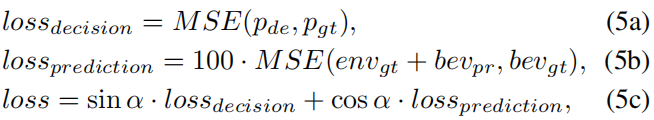
Here p_de and p_gt denote the decision output and ground-truth ego positions over the future 4 s. bev_pr and bev_gt denote BEV prediction and ground truth. env_gt denotes the static environment map. Weight parameter alpha balances decision and prediction losses.
Online fine-tuning
BEV inputs are embedded and fed to the model to produce future trajectory points over MΔt. The motion planner generates dynamically feasible trajectories from decision outputs. The executable trajectory is fed back to the model to generate future BEV predictions. An experience rasterizer provides static map information for simulated driving. After simulating Δt, the next BEV ground truth is available for fine-tuning.
Summary
Prediction, decision, and motion planning are essential for autonomous driving. Traditional pipelines treat them as separate modules or as multi-task models with shared backbones and task heads. Integrating these modules into a compact framework avoids complex input decoupling and redundant designs and requires attention to long-horizon scene prediction.
This article presented two end-to-end algorithmic architectures. ADAPT is an end-to-end Transformer predictor that annotates interpretable actions and reasoning. BEVGPT integrates prediction, decision, and motion planning using BEV images as input to produce end-to-end outputs. Practically, BEVGPT operates on BEV images derived from perception preprocessing rather than raw sensor inputs, and it requires high-definition maps during training to construct BEV ground truth because BEV focuses on dynamic targets while HD maps provide static scene references. Converting BEV images into BEV features via an LSS transform before input can improve computational efficiency for the downstream model.