1. Introduction
Recently autonomous driving dataset generative models have gained attention, mainly divided into NeRF and diffusion model approaches. A central challenge for diffusion-based methods is maintaining consistency across the global world and consistency among different sensors. This article summarizes a recent open-source solution from Fudan University, WoVoGen, which can generate street-level video from vehicle control inputs and supports scene editing.
2. Abstract
Generating multi-camera street-view video is important for expanding autonomous driving datasets and addressing the need for diverse data. Traditional rendering-based methods face limitations in diversity and handling varying lighting, and are increasingly being replaced by diffusion-based approaches. A major challenge for diffusion methods is ensuring that generated sensor data remains consistent both globally and across sensors. To address these challenges, the authors introduce an explicit world voxel and propose the World Voxel-Aware Multi-Camera Driving Scene Generator (WoVoGen). The system is designed to use 4D world voxels as the fundamental element for video generation. The model operates in two stages: (i) imagine future 4D world voxels conditioned on a vehicle control sequence; (ii) generate multi-camera video from the imagined 4D world voxels together with sensor connectivity knowledge. Incorporating 4D world voxels enables WoVoGen to generate high-quality street-level video conditioned on vehicle control inputs and to facilitate scene editing tasks.
3. Results Overview
WoVoGen predicts the surrounding environment and produces consistent visual feedback in response to the vehicle's driving actions. To leverage recent advances in generative models, WoVoGen encodes structured communication information into a regular grid representation, the world voxel, and designs a new latent-diffusion-based world model to regressively predict world voxels.
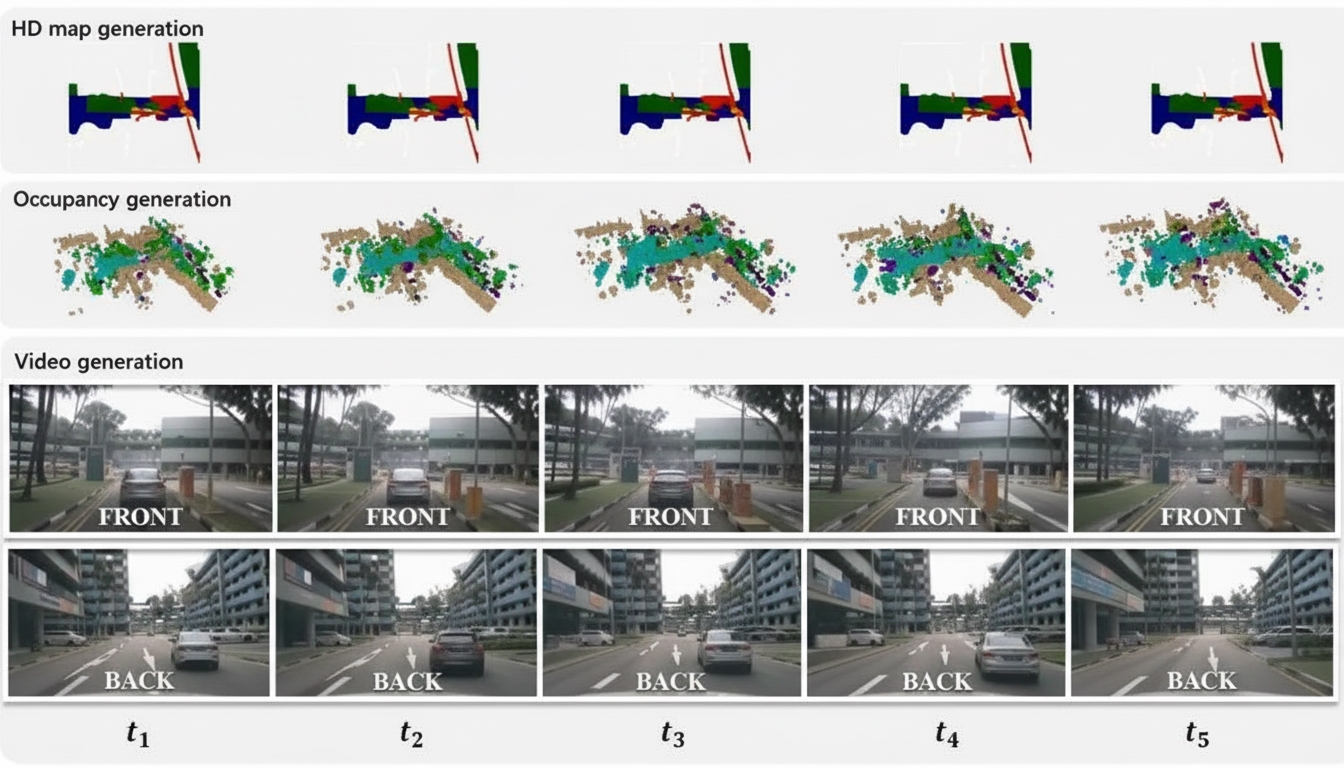
WoVoGen can generate future world voxels with temporal consistency (first two rows). Then, using world-voxel-aware 2D image features derived from the world model outputs, it synthesizes driving video that is consistent across multiple cameras and over time (bottom two rows).
4. Method
Overall WoVoGen architecture. Top: the world model branch. The authors fine-tune an AutoencoderKL and train a 4D diffusion model from scratch to generate future world voxels conditioned on past voxels and ego-vehicle actions. Bottom: the world-voxel-aware synthesis branch. The generated future voxels are input to a world encoder that produces Fw. Subsequent sampling yields Fimg, which is then aggregated. The process completes by applying panoramic diffusion to produce future video frames.
5. Comparison with Other Methods
Quantitative comparison of image/video generation quality on the nuScenes validation set. WoVoGen jointly achieves multi-view and multi-frame generation with the lowest FID and FVD scores among the evaluated methods.

6. Conclusion
This work proposes WoVoGen, which leverages 4D world voxels to combine temporal and spatial information and addresses the complexity of creating content from multi-sensor data while preserving consistency. The two-stage system can generate high-quality videos from vehicle control inputs and supports complex scene editing.