Papers, authorship, and overall scores
Xiaomi Auto has not released detailed information about its autonomous driving algorithms, but its published academic papers provide insight. Two primary papers have been released. The first is "SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection," authored by researchers including collaborators from the National University of Singapore and two authors from Xiaomi Auto. The second is "SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field," with eight authors, six from Xiaomi Auto and two from Xi'an Jiaotong University, one of whom later joined Xiaomi Auto. Both papers center on occupancy networks, a point that was also mentioned at Xiaomi Auto's launch event.
The first paper focuses on 3D perception while the second addresses 3D scene reconstruction. 3D perception methods are typically benchmarked on the nuScenes dataset. Since many readers do not want to read dense academic text, the following summarizes the reported scores.
Image source: "SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection" paper
The NDS score is 58.1, which is relatively low. For comparison, Huawei's TransFusion (October 2021) scored 71.7, and Leapmotor's EA-LSS scored 77.6. However, those two are primarily bounding-box-based methods rather than occupancy-network-based methods, so the comparison is not entirely direct.
Image source: "SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection" paper
Compared with another leading occupancy-network architecture, TPVFormer (proposed by Beihang University), the results are similar.
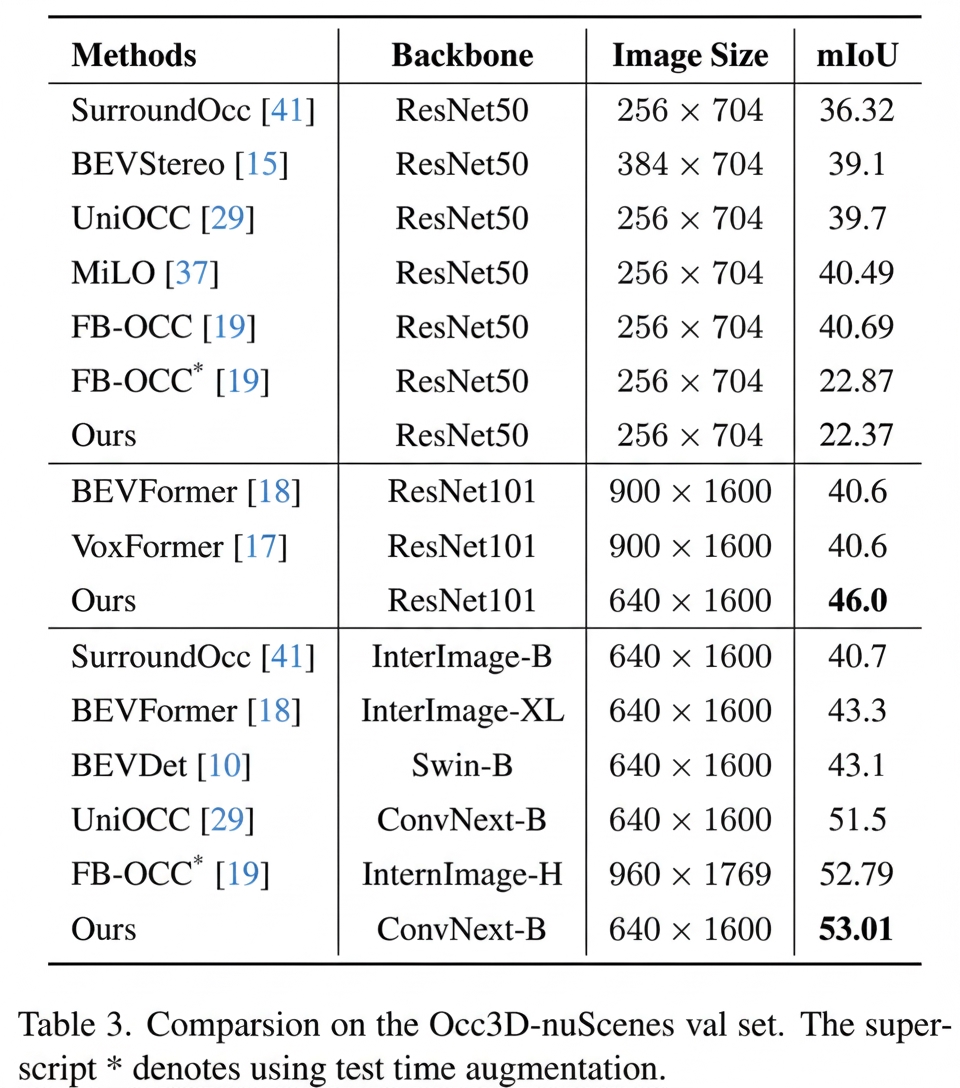
Image source: "SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field" paper
The SurroundSDF paper achieves the top mIoU among occupancy-network approaches. mIoU (Mean Intersection over Union) is a standard metric for semantic segmentation, computed as the intersection over union between ground truth and predicted segmentation. The paper provides the usual formula and benchmark tables.
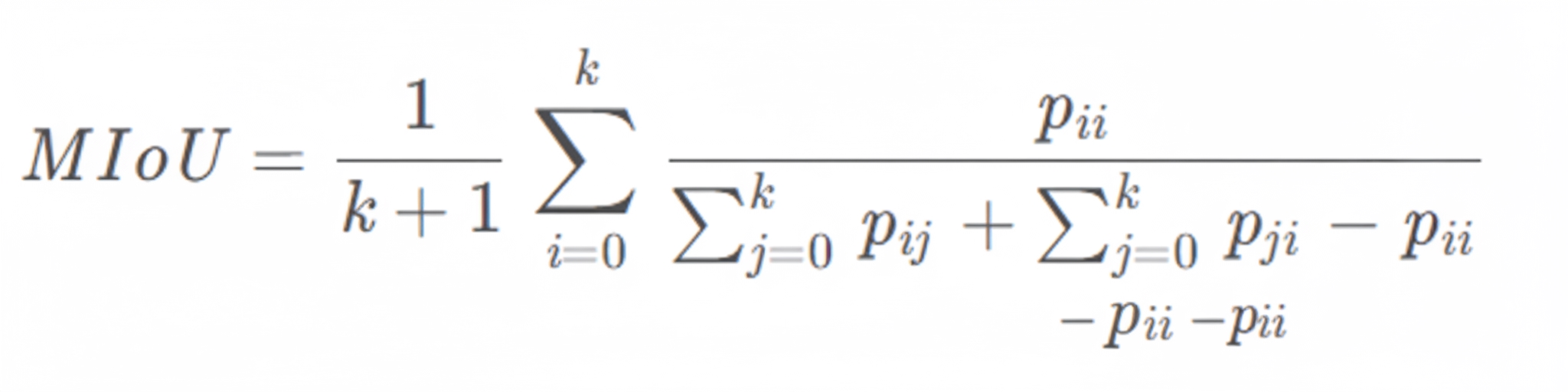
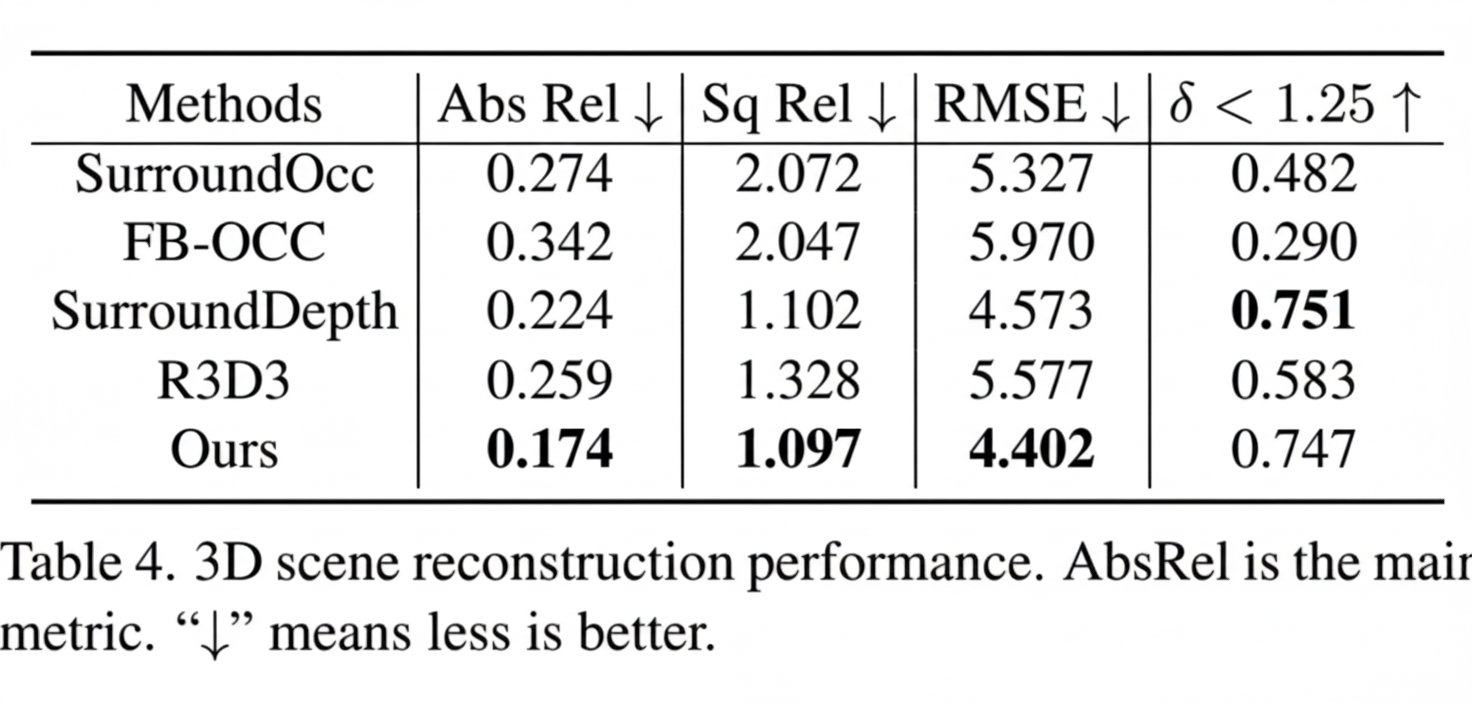
Image source: "SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field" paper
The 3D scene reconstruction scores are also among the best in occupancy-network methods.
SOGDet: Semantic-Occupancy Guided Detection
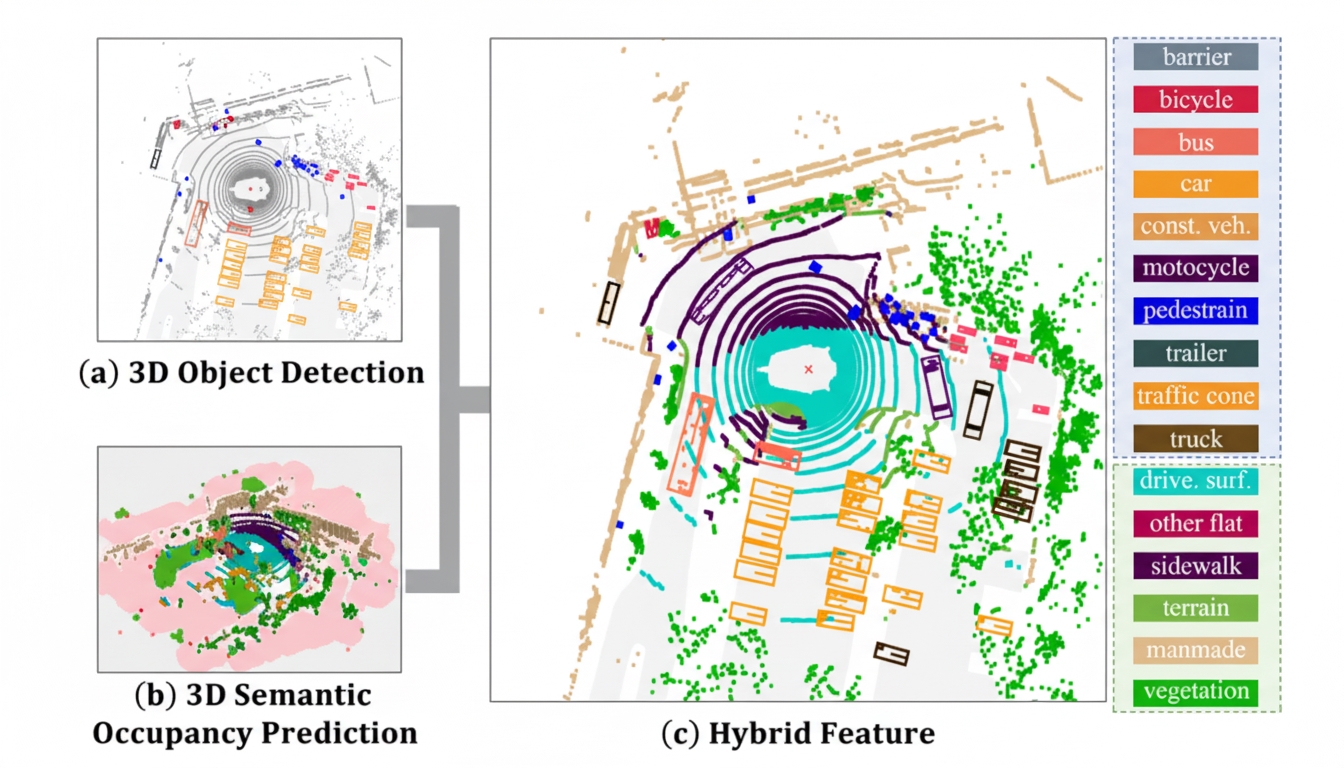
Image source: "SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection" paper
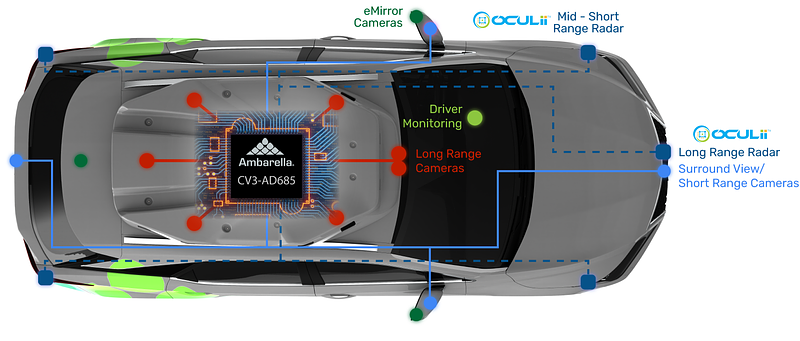
SOGDet combines 3D perception with semantic-occupancy prediction to improve perception of non-drivable areas and to construct a complete 3D scene representation so the planning system better understands the surrounding environment. Non-drivable areas include vegetation (medians, grass), sidewalks, terrain, and man-made structures.
Image source: "SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection" paper
The SOGDet architecture follows mainstream designs. Modern perception stacks typically have three parts: a 2D backbone, a view transformer for BEV conversion, and task-specific heads. The backbone is still commonly a CNN such as ResNet-50/100 because Transformers remain computationally expensive for onboard deployment. Some systems use ViT variants, but these are difficult to deploy in practice. The multi-view-to-BEV step uses view transformers and builds on the LSS approach, which includes:
- Lift: estimate a depth distribution for downsampled image-plane locations to obtain frustums containing image features;
- Splat: project all frustums into the BEV grid using camera intrinsics and extrinsics, then aggregate frustum points per BEV cell (sum-pooling) to form BEV feature maps;
- Shoot: process BEV features with task heads to output perception results.
LSS was proposed in 2020 and has seen extensions such as depth correction and camera-aware depth prediction. SOGDet also introduces efficient voxel pooling to accelerate BEVDepth methods and multi-frame fusion to improve detection and motion estimation. Task heads use deconvolutions and MLPs to output semantic occupancy or bounding boxes.
SurroundSDF: Implicit 3D Scene Understanding
SurroundSDF is primarily a semantic-occupancy network, so its main metric is mIoU.
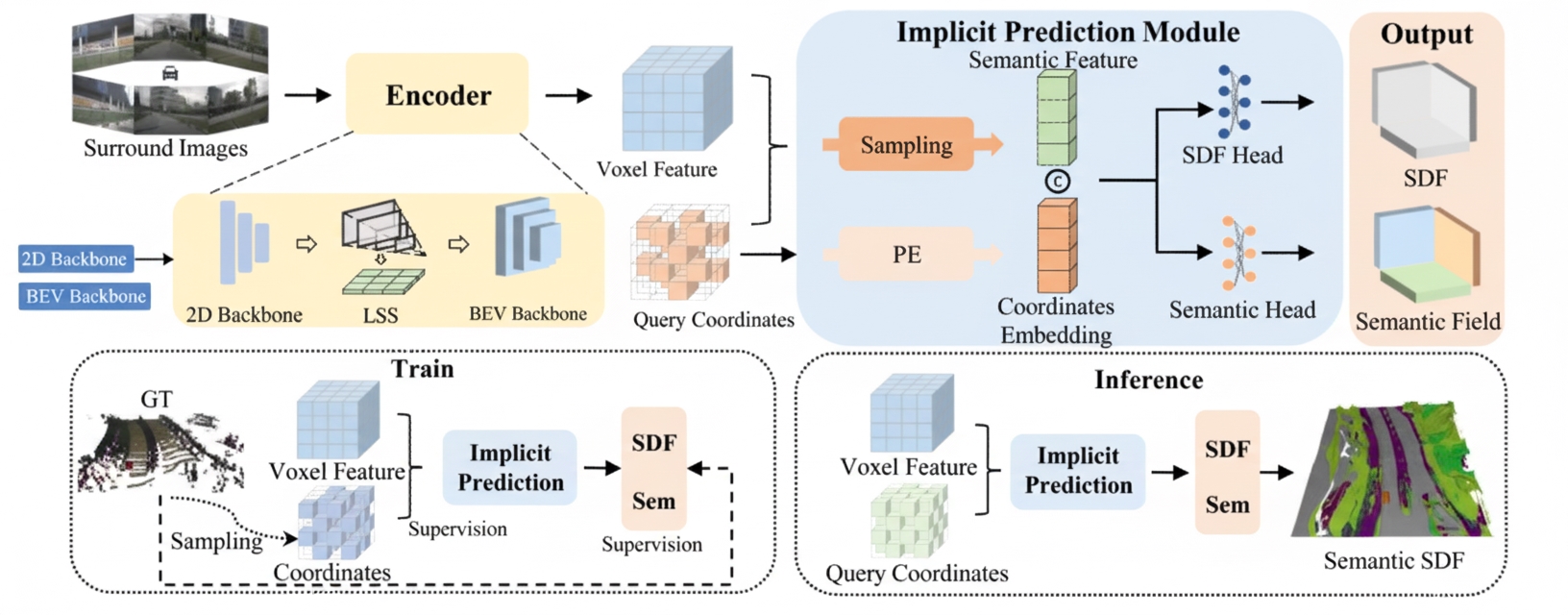
Image source: "SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field" paper
Signed Distance Field (SDF) is a variant of distance fields that maps positions in 3D (or 2D) space to their distance to the nearest surface, with a sign indicating whether a position is inside or outside a surface. Distance fields are used in image processing, physics, and computer graphics. In graphics, signed distance fields allow implicit representations of geometry as an alternative to explicit mesh representations. 3D assets can be represented as meshes, SDFs, point clouds, or neural implicit representations. For image assets, SDF techniques were introduced for high-resolution, anti-aliased representations in mobile games; for example, Genshin Impact uses SDF techniques for facial shading.
SurroundSDF shares the same backbone, LSS, and voxel modules as SOGDet, differing mainly in the output heads. The method aims to overcome challenges in vision-based 3D scene understanding for autonomous driving:
- Continuity and accuracy: object-free methods that predict discrete voxel grids often fail to reconstruct continuous, accurate obstacle surfaces. SurroundSDF implicitly predicts a signed distance field and a semantic field to perceive continuous 3D scenes from surround images.
- Lack of precise SDF ground truth: obtaining accurate SDF ground truth is difficult. The paper proposes a weakly supervised "Sandwich Eikonal" formulation that applies dense constraints on both sides of surfaces to improve surface accuracy. The Eikonal equation is a class of nonlinear PDEs used in wave propagation problems; in imaging, it is applied to compute distance fields, denoise images, and extract shortest paths on discretized surfaces.
- Joint semantic and geometric reconstruction: SurroundSDF jointly addresses 3D semantic segmentation and continuous 3D geometric reconstruction within a single framework by leveraging SDF's representational power.
- Long-tail distribution and coarse scene descriptions: despite progress in 3D object detection, long-tail categories and coarse scene descriptions remain challenging, requiring deeper geometric and semantic reasoning.
SurroundSDF uses SDF to implicitly represent 3D scenes, enabling continuous descriptions and smooth surface reconstruction. The SDF constraints are enforced through the Eikonal formulation to accurately capture obstacle surfaces. To reduce inconsistencies between geometric and semantic optimization, the paper proposes a joint supervision strategy: it converts each voxel's minimum SDF value into a free-space probability via SoftMax, combines this with semantic logits, and jointly optimizes using a Dice loss.
Observations on mainstream architecture and research practice
The core architecture of modern autonomous driving perception has largely stabilized around a 2D CNN backbone with FPN, an intermediate transformer-based view converter, and task-level MLPs or implicit decoders. Even Tesla has adopted implicit neural representations in its presentations, but no mainstream approach has escaped this general framework. In practice, performance differences are often driven less by algorithmic novelty and more by data scale and human effort: extensive experimentation and tuning require substantial manpower. Major disruptive advances are still most likely to come from large research organizations.