Overview
At Hot Chips 2023, Samsung presented its memory processing technology, PIM, and shared recent research and development results. The company framed the presentation in the context of artificial intelligence workloads.
CPU Computation and Data Movement Costs
Samsung highlighted that the dominant cost in memory systems is moving data from various storage and memory locations to the compute engine. Increasing the number of channels to different memory types has practical limits, and approaches that simply add channels face diminishing returns.
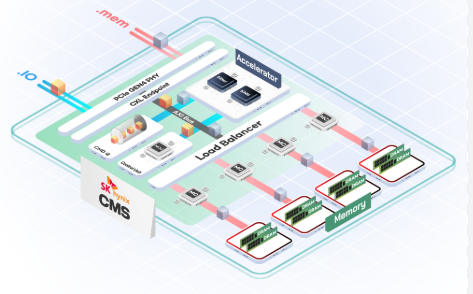
Work on CXL is useful because it allows reconfiguration of PCIe lanes for larger memory bandwidth.
GPT Workload Bottlenecks
Samsung analyzed bottlenecks in GPT-like models, focusing on compute overflow and memory-constrained workloads. The primary targets are the linear layers used in Transformer models, including the linear layers in multihead attention (MHA) and the feedforward network (FFN).
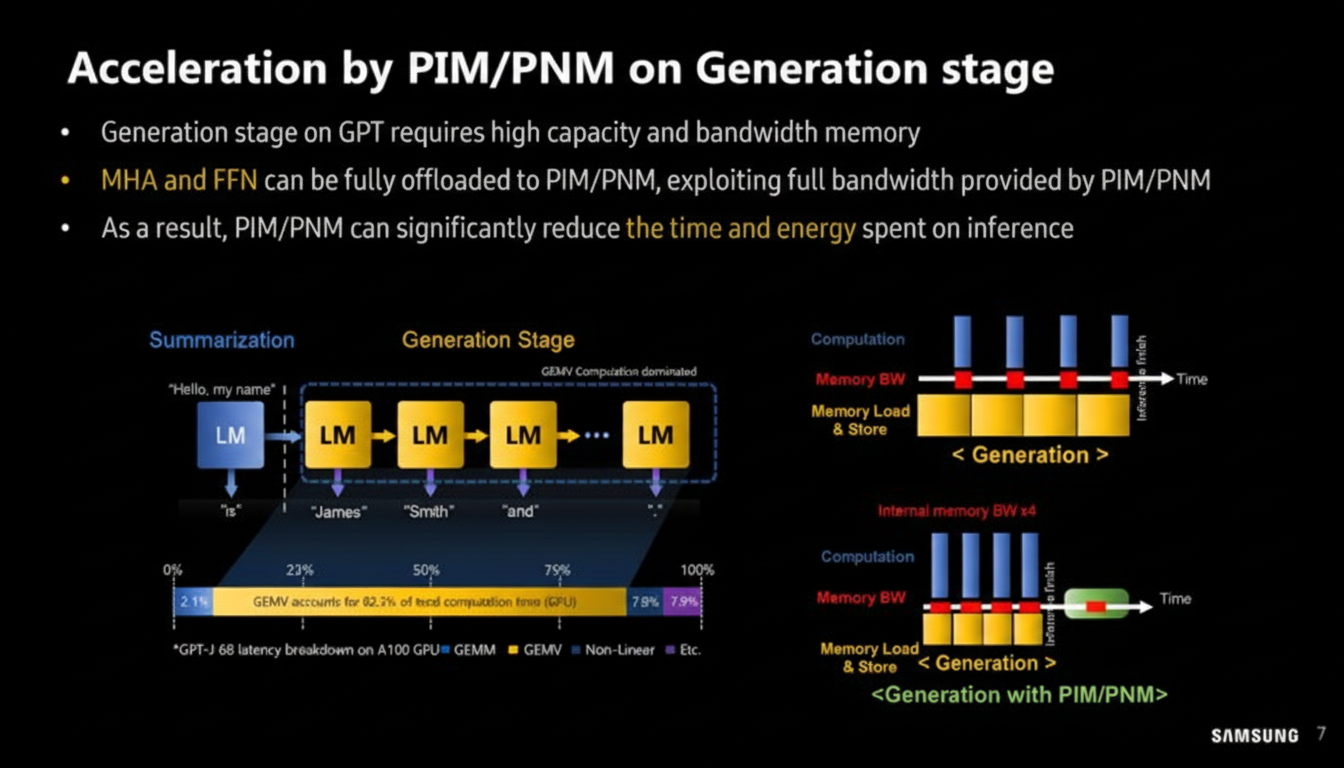
Generation (inference) is particularly memory-bound and sequential, which often yields poor performance on GPUs. GPT inference workloads include both compute-intensive tasks such as summarization and memory-intensive tasks such as text generation. The GEMV (generalized matrix-vector multiplication) component can account for 60–80% of total generation latency, making it a key optimization target for PIM/PNM.
Analysis of utilization and execution time shows most execution time is spent copying memory from host CPU memory to GPU memory. GEMV operations have very low utilization compared with other stages, and as the number of output tokens increases, GEMV dominates inference time.
Offloading to PIM/PNM
Samsung demonstrated offloading parts of the compute pipeline to PIM modules. This approach saves the cost of transferring data to the CPU or xPU and reduces power consumption. The generation stage of GPT requires both high capacity and high bandwidth memory. MHA and FFN can be fully offloaded to PIM/PNM to exploit the full bandwidth available in these modules, significantly reducing time and energy during inference.
HBM-PIM and Cluster Experiments
Samsung described HBM-PIM and compared it with standard PIM approaches. Both Samsung and AMD have explored HBM-PIM configurations that allow cluster-scale experiments. For example, a test cluster could be built from multiple nodes and accelerators to evaluate new memory technologies.
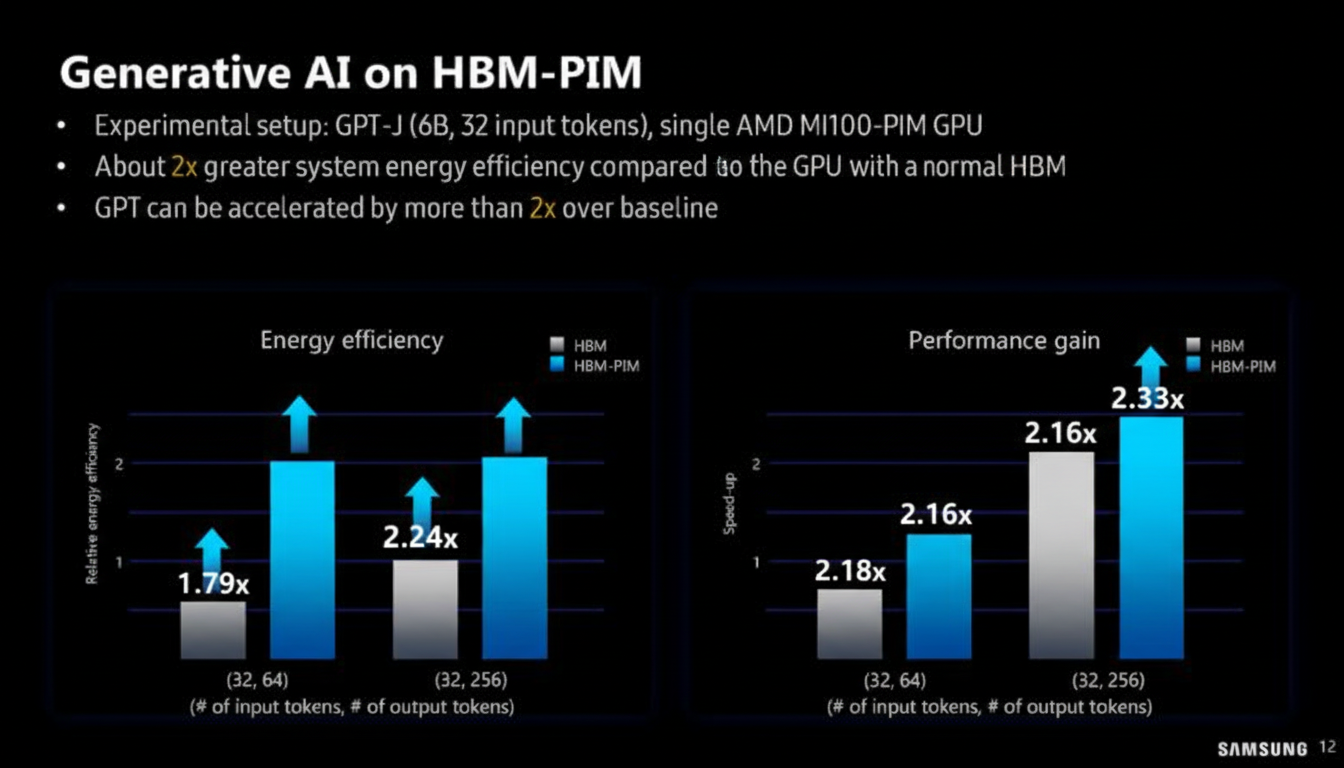
Samsung showed how a T5-MoE model uses HBM-PIM in a cluster and presented measured improvements in performance and energy efficiency.
Software and Programmability
Making PIM modules practical requires software support and programmability. Samsung aims to integrate these capabilities into standard programming frameworks so that developers can utilize PIM functionality without extensive low-level changes.
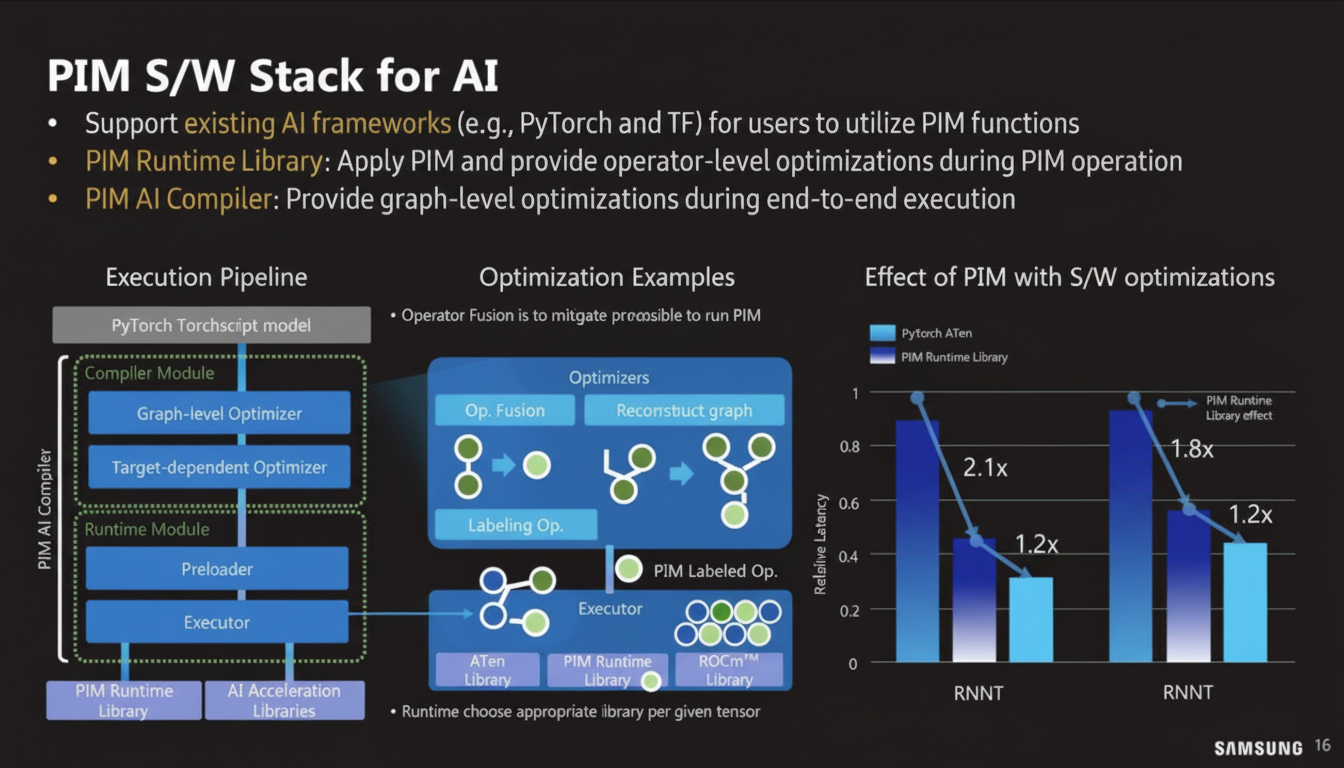
LPDDR-PIM and LP5-PIM
Samsung presented LPDDR-PIM concepts where internal bandwidth is around 102.4 GB/s. The design philosophy is to keep computation on the memory module to avoid transferring data back to the CPU or xPU, reducing power consumption. The presentation included performance and power analysis for LP5-PIM modules.

CXL-PNM: Compute on CXL Modules
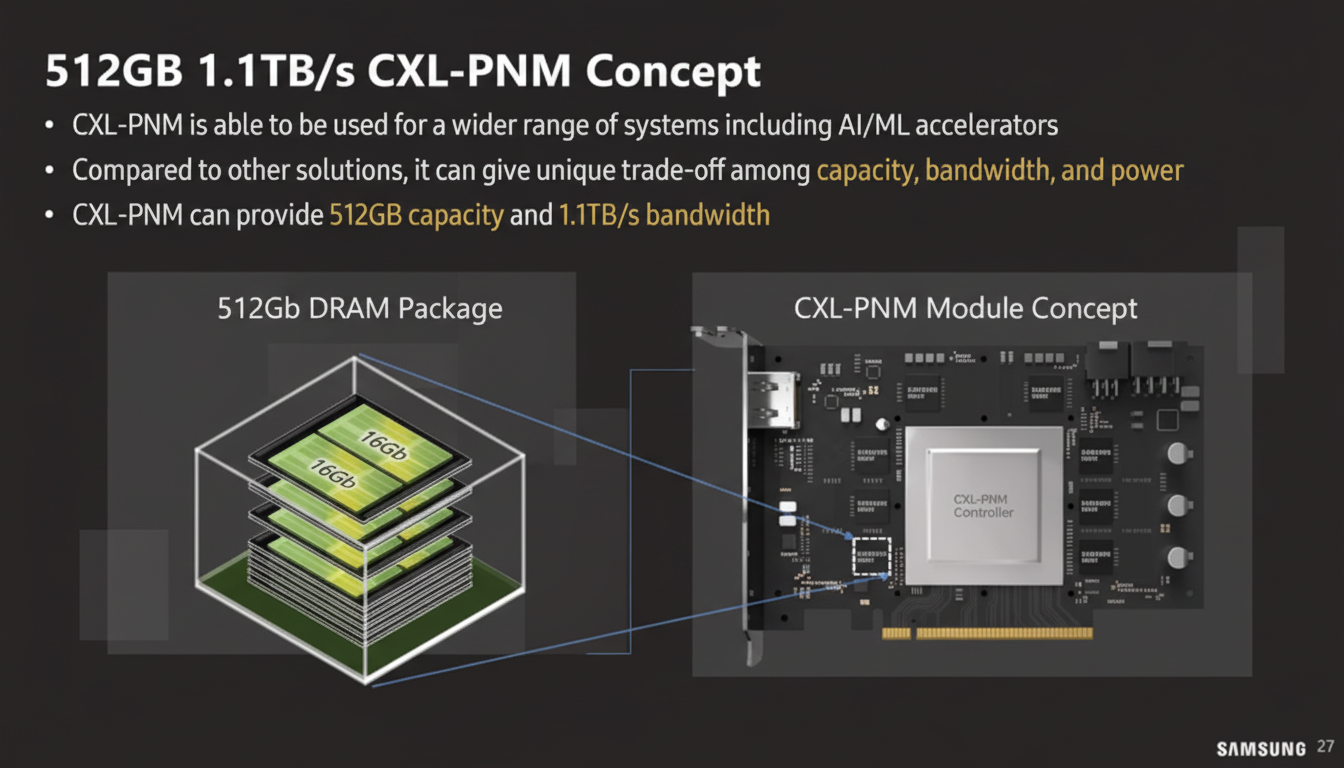
Beyond HBM-PIM and LPDDR-PIM, Samsung is exploring placing compute into CXL modules, called PNM-CXL. This approach goes beyond simply placing memory on a CXL Type-3 module by integrating compute elements on the CXL module itself. It can be implemented by adding compute components to the CXL module and using either standard memory or PIM on the module together with a standard CXL controller.

Samsung presented a conceptual 512 GB CXL-PNM card with up to 1.1 TB/s bandwidth.
Samsung also outlined a CXL-PNM software stack for managing these modules.
Energy, Carbon, and Potential
CXL typically transmits data over PCIe wires, which makes data transfer energy intensive. Avoiding data movement therefore provides significant energy advantages. Samsung emphasized the potential energy and throughput improvements for large-scale LLM workloads and highlighted the importance of reducing carbon emissions.
Outlook
Samsung has been working on PIM for many years and is now moving beyond research toward commercialization. Continued development could make CXL-PNM and related memory-processing approaches a practical option for certain compute-intensive, memory-bound workloads.