Abstract
Memory disaggregation separates compute and memory resources into independent pools connected by high-speed networks, improving memory utilization, lowering cost, and enabling elastic scaling. Existing RDMA-based memory disaggregation solutions face high latency and extra overheads such as page faults and intrusive code changes. Emerging cache-coherent interconnects like CXL offer opportunities to redesign low-latency disaggregation, but pure CXL approaches are limited by physical distance and rack-level deployment constraints.
This article presents Rcmp, a hybrid RDMA+CXL memory disaggregation system that reduces latency and improves scalability by using CXL for low-latency intra-rack access and RDMA to overcome CXL distance limits across racks. To address mismatches between RDMA and CXL in access granularity, communication, and performance, Rcmp: (1) provides global page-based memory management while enabling cache-line-granularity access; (2) designs an efficient communication mechanism to avoid message blocking; (3) implements hot-page identification and swapping to reduce RDMA traffic; and (4) provides an RDMA-optimized RPC framework to accelerate transfers. A user-level Rcmp prototype (6483 lines of C++) is evaluated with microbenchmarks and a YCSB-driven key-value store. Rcmp reduces latency by up to 5.2x and increases throughput by up to 3.8x compared to RDMA-only systems, and scales with node count without losing performance.
01. Introduction
Memory disaggregation is gaining traction in data centers, cloud servers, in-memory databases, and HPC because it enables higher memory utilization, flexible resource scaling, and cost savings. The architecture decouples compute nodes (CNs), which provide CPU resources with limited local DRAM, from memory nodes (MNs), which provide large memory capacity with minimal compute. A global shared memory pool is exposed over a high-speed interconnect.
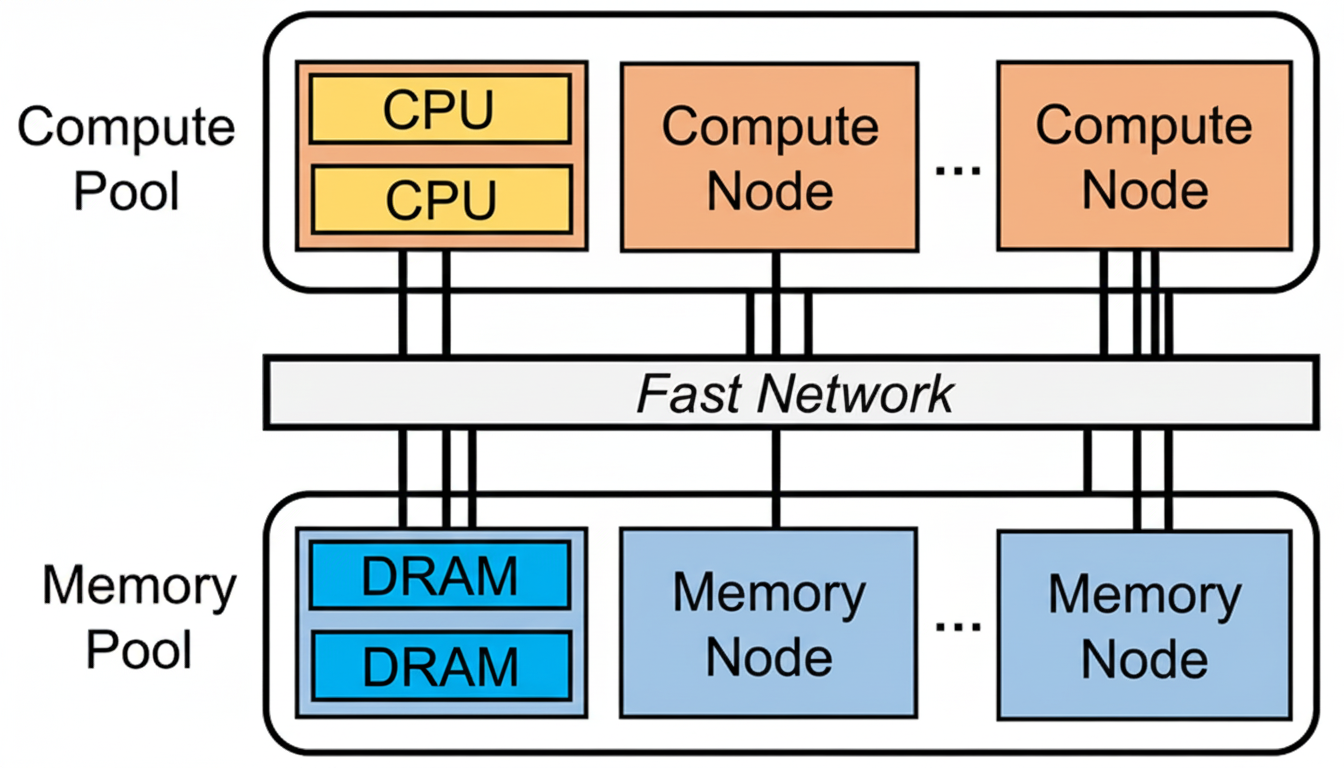
Figure 1. Memory disaggregation
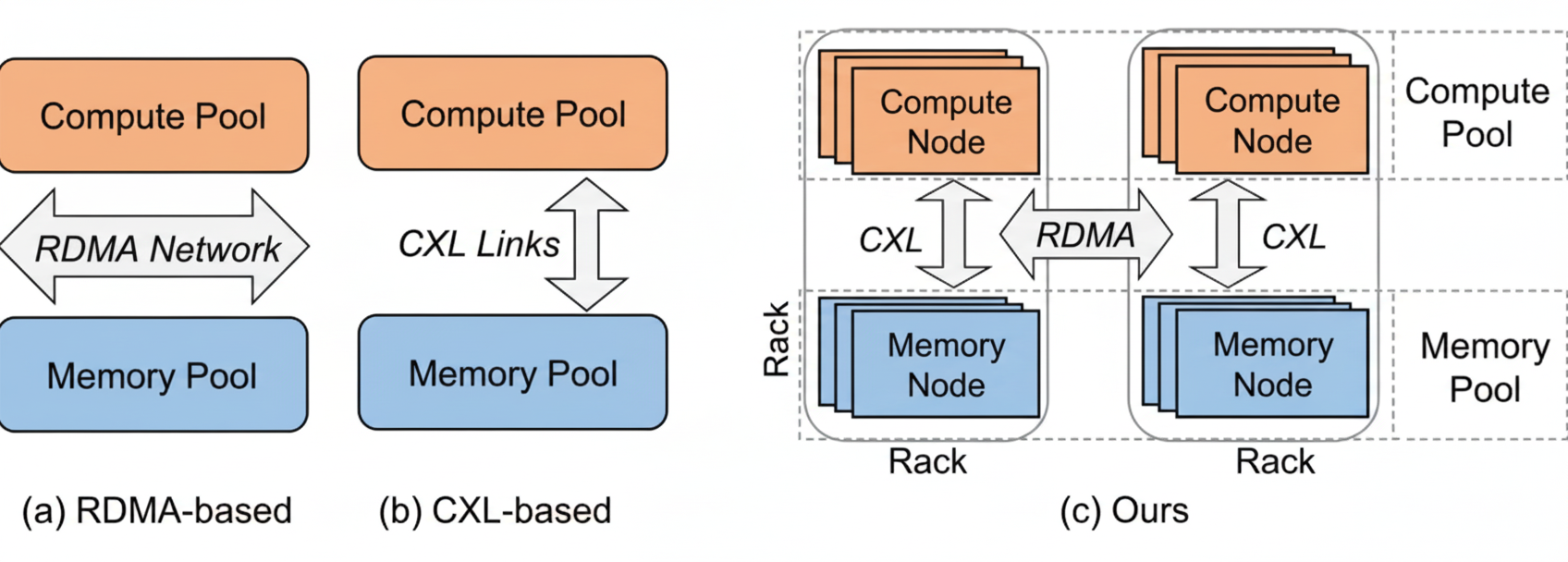
Figure 2. Different memory disaggregation architectures
RDMA networks are commonly used to connect compute and memory pools (Figure 2(a)). However, RDMA-based disaggregation has significant drawbacks. First, latency: RDMA typically achieves single-digit microsecond latency (about 1.5–3 μs), which is orders of magnitude slower than DRAM access (approximately 80–140 ns). RDMA thus becomes the performance bottleneck for memory pool accesses. Second, software and runtime overhead: because native memory semantics are not supported end-to-end, RDMA-based approaches often require intrusive code modifications and suffer page-fault handling overhead. Page-based schemes incur page-fault processing and read/write amplification, while object-based schemes require custom interfaces and source-level changes that reduce transparency.
CXL (Compute Express Link) is a PCIe-based cache-coherent interconnect that allows direct, coherent load/store access to remote memory without CPU intervention. CXL natively supports memory semantics and can provide near-NUMA latency (roughly 90–150 ns). CXL therefore holds promise for low-cost, low-latency memory disaggregation. However, pure CXL deployments face practical limitations: physical distance constraints (typically rack-level only), immature ecosystem and limited production hardware, and high cost for large-scale replacement of RDMA infrastructure. Research prototypes often rely on FPGA implementations or NUMA-based simulation.
We investigate a hybrid architecture that combines CXL and RDMA: build small CXL memory pools within each rack and use RDMA to link racks into a larger pool (Figure 2(c)). This approach uses CXL to improve per-rack performance while relying on RDMA for cross-rack scalability. The hybrid design faces three main challenges: granularity mismatch, communication mismatch, and performance mismatch. In particular, the latency gap between CXL and RDMA makes cross-rack RDMA the dominant performance bottleneck.
To address these challenges, we propose Rcmp, a hybrid low-latency, scalable memory pool system that combines RDMA and CXL. Rcmp decouples page allocation size and access granularity, provides efficient intra- and inter-rack communication with non-blocking designs, identifies and migrates hot pages to reduce remote access, caches fine-grained remote accesses in CXL memory, and offers an RDMA-aware RPC framework to accelerate transfers.
We implemented Rcmp in user space (6483 lines of C++) and integrated it with FUSE to provide a high-capacity memory-backed file system API. Microbenchmarks and YCSB-driven key-value experiments show that Rcmp reduces latency by 3–8x in microbenchmarks and improves throughput by 2–4x under YCSB compared to RDMA-only disaggregated systems. Rcmp also demonstrates good scalability with increasing nodes or racks. The Rcmp source code and datasets are available in the Rcmp GitHub repository.
Contributions:
- Analysis of limitations in current disaggregated memory systems, identifying RDMA-based systems' high latency, software overhead, and suboptimal communication, and CXL-based systems' physical distance constraints and limited available products.
- Design and implementation of Rcmp, the first system to combine RDMA and CXL to construct a disaggregated memory architecture that delivers both low latency and scalability.
- Multiple optimizations to address RDMA/CXL mismatches, including global memory management, efficient communication mechanisms, hot-page swapping, and an RDMA-optimized RPC framework.
- Comprehensive evaluation demonstrating Rcmp's performance and scalability advantages over state-of-the-art disaggregation approaches.
Organization: Sections 2 and 3 present background and motivation. Sections 4 and 5 describe Rcmp design and system details. Section 6 evaluates Rcmp. Section 7 discusses related work. Section 8 concludes and outlines future directions.
02. Background
2.1 Memory Disaggregation
Emerging workloads such as big data, deep learning, HPC, and large language models drive significant memory demands in modern data centers. Monolithic server architectures, where CPU and memory are tightly coupled, face low memory utilization, inflexible resource elasticity, and high costs. Typical memory utilization across data centers, cloud platforms, and HPC systems is often below 50%, with allocated memory frequently underutilized for extended periods.
Memory disaggregation separates memory resources from compute resources into independent pools connected by a high-speed network. Compute nodes (CNs) host many CPU cores with limited local DRAM, while memory nodes (MNs) host large-capacity memory with minimal compute. Microsecond-latency networks (e.g., RDMA) or cache-coherent interconnects (e.g., CXL) are commonly used between CNs and MNs.
2.2 RDMA
Remote Direct Memory Access (RDMA) allows a host to directly access memory on a remote machine via RDMA-capable NICs (RNICs), achieving high bandwidth (> 10 GB/s) and microsecond-scale latency (~2 μs). RDMA provides one-sided primitives (READ, WRITE, ATOMIC) and two-sided primitives (SEND, RECV) implemented via a queue-pair (QP) and completion queue (CQ) model. Doorbell batching allows aggregation of multiple operations into a single submission to amortize overhead. RNICs perform asynchronous transfers and notify completion via CQ entries.
2.3 CXL
Compute Express Link (CXL) is an open standard based on PCIe that provides cache-coherent load/store semantics among processors, accelerators, and memory devices. CXL.mem allows CPUs to access remote memory directly over PCIe without page faults or DMA, exposing byte-addressable memory in the same physical address space and enabling transparent memory allocation. With PCIe 5.0, CPU-to-CXL bandwidth and access latency are similar to NUMA interconnects. From a software perspective, CXL memory looks like a server-less NUMA node with access latency comparable to NUMA (roughly 90–150 ns), with CXL 3.0 reporting latencies approaching DRAM in some measurements. However, many current CXL prototypes report higher latencies (170–250 ns).
03. Existing Disaggregation Architectures and Limitations
3.1 RDMA-based Approaches
RDMA-based memory disaggregation can be broadly categorized into page-based and object-based approaches. Page-based systems (e.g., Infiniswap, LegoOS, Fastswap) use virtual memory mechanisms to cache remote pages in local DRAM and trigger page faults and swaps for remote page accesses. They are simple and application-transparent but suffer page-fault overhead and read/write amplification. Object-based systems (e.g., FaRM, FaRMV2, AIFM, Gengar) expose custom object semantics (such as key-value APIs) for fine-grained management and often rely on one-sided RDMA to avoid remote CPU involvement. However, using only one-sided RDMA primitives may require multiple read/write operations per query, increasing latency; hence many systems rely on RDMA-optimized RPC frameworks.
RDMA-based solutions face three main problems:
- High latency: RDMA vs. memory access latency gaps exceed 20x, making RDMA the main bottleneck.
- High overhead: Page-based designs suffer page-fault processing and read/write amplification; object-based designs avoid page faults but require intrusive application changes and higher complexity.
- Poor communication utilization: Existing RDMA communication strategies underutilize available bandwidth. Tests show RPC is better for small transfers while hybrid one-sided RDMA+RPC is superior for larger transfers, with 512 B as a practical threshold for strategy selection.
3.2 CXL-based Approaches
CXL-based disaggregation offers lower software overhead, cache-line-granularity access, and reduced latency compared to RDMA-based approaches. CXL supports native load/store access from CPUs, GPUs, and accelerators, allowing cache-line-granularity operations and avoiding read/write amplification. However, disadvantages include:
- Physical distance limits: PCIe cable and signal constraints limit CXL deployment to rack-level distances. Converting PCIe electrical signals to optical is an area of ongoing research but introduces cost, signal loss, and deployment complexity; optical transmission delays over several meters exceed modern memory first-byte access latencies.
- High cost and immature ecosystem: Production-quality CXL hardware remains limited and expensive; many studies use FPGA prototypes or NUMA-based simulation for CXL evaluation.
3.3 Hybrid Approaches and Challenges
Combining CXL and network connectivity is a promising way to overcome CXL distance limits, e.g., CXL-over-Ethernet. Such approaches allow load/store semantics across racks but still require network traversal for each remote access, which prevents full exploitation of CXL's low-latency benefits. Key challenges for hybrid RDMA+CXL architectures are:
- Granularity mismatch: CXL supports cache-line-granularity coherent access, while RDMA typically operates at page or object granularity.
- Communication mismatch: RDMA relies on RNICs and queue-pair mechanisms, while CXL uses high-speed coherent links. A unified, efficient abstraction is needed for intra- and inter-rack communication.
- Performance mismatch: RDMA latency is an order of magnitude higher than CXL, leading to non-uniform access patterns similar to NUMA—local intra-rack accesses are much faster than remote cross-rack accesses.
04. Design Rationale
Rcmp is a hybrid memory pool system that uses CXL within racks and RDMA between racks to achieve both low latency and scalability. The main design trade-offs are summarized below.
4.1 Global Memory Management
Rcmp uses a page-based global memory management to remain transparent to applications and to align with CXL's byte-addressability. Pages are subdivided into slabs for fine-grained allocation, decoupling allocation granularity (page) and access granularity (cache line). A centralized metadata server (MS) initially manages global page allocation and mapping. Rcmp performs cache-line-granularity accesses and moves data at cache-line granularity. For intra-rack accesses, CXL provides natural cache-line-granularity operations. For cross-rack accesses, Rcmp uses a direct I/O model rather than kernel-driven page-fault swapping to avoid performance penalties.
4.2 Efficient Communication Mechanism
Rcmp uses lock-free ring buffers for both intra-rack and inter-rack messaging to achieve high throughput and low latency. A naive single-ring design can cause message blocking: local low-latency requests may be delayed behind long-latency remote requests due to variable message lengths. To avoid this, Rcmp decouples local and remote accesses, using different ring buffer structures; remote accesses use a two-layer ring buffer to avoid head-of-line blocking.
4.3 Remote Rack Access Optimizations
Cross-rack accesses are the primary performance bottleneck due to RDMA latency. Rcmp addresses this by reducing the number of remote accesses and accelerating those that remain.
Reducing remote accesses: Rcmp implements a page-level hotness tracker and a user-level hot-page swapping mechanism that migrates frequently accessed pages to the local rack. Additionally, fine-grained remote accesses are cached in CXL memory and write requests are batched to remote racks.
Accelerating RDMA communication: Rcmp introduces an RDMA-optimized RPC framework (RRPC) that adaptively uses RPC and one-sided RDMA depending on data size and pattern, plus optimizations like doorbell batching to fully utilize RDMA bandwidth.
05. Rcmp System
This section details the Rcmp architecture and optimizations.
5.1 System Overview
Rcmp manages the cluster at the rack level. Within a rack, CNs and MNs are connected via CXL to form a small local memory pool. Racks interconnect via RDMA to form a global pool. A metadata server (MS) handles global address allocation and mappings. Each rack runs a Daemon that handles access requests (CXL proxy), RDMA message management, hot-page swapping, slab allocation, and CXL memory resource management. The system is user-level to avoid kernel-user context-switch overhead.
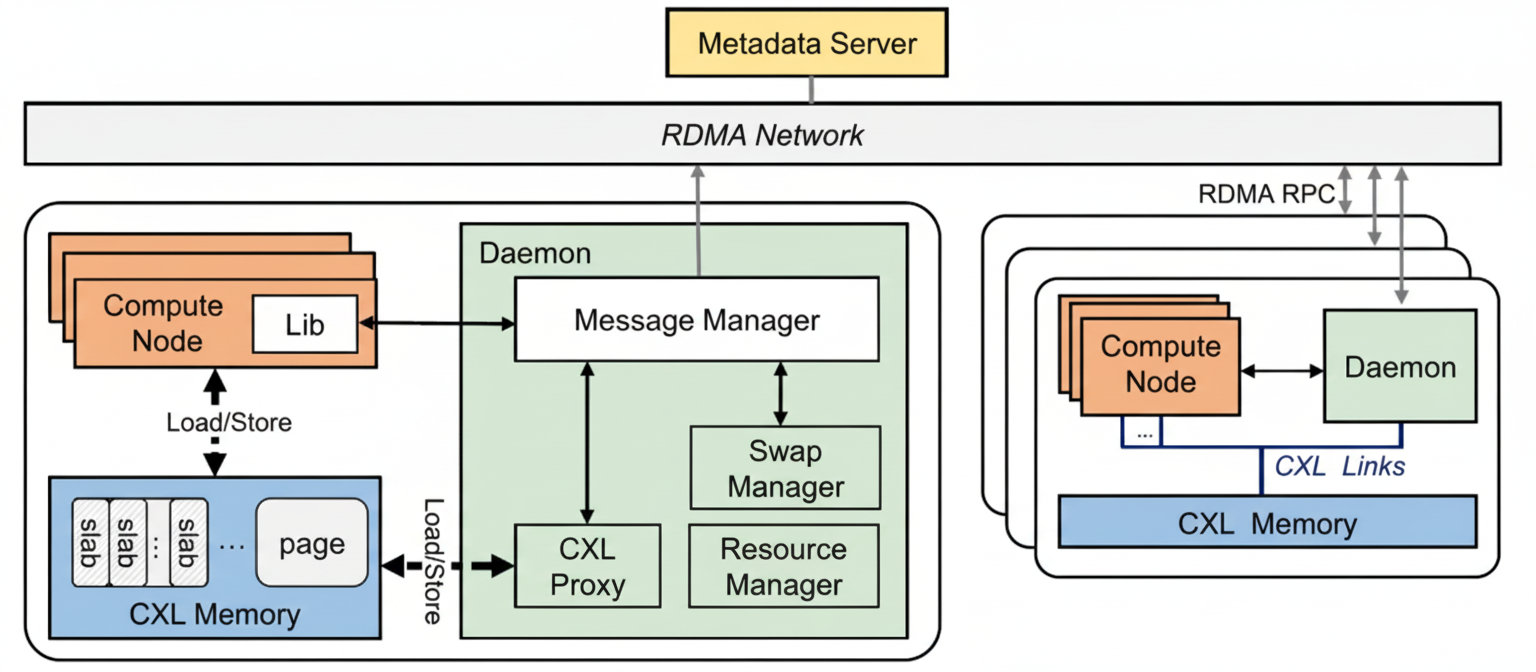
Figure 3. Rcmp system overview
Global memory management: MS allocates memory at page granularity. A global address GAddr(page_id, page_offset) encodes page ID assigned by MS and page offset within CXL memory. Rcmp stores mappings in two hash tables: a page directory in the MS that maps page IDs to racks, and page tables in each Daemon mapping page IDs to CXL offsets. Slab allocation supports fine-grained allocations within pages.
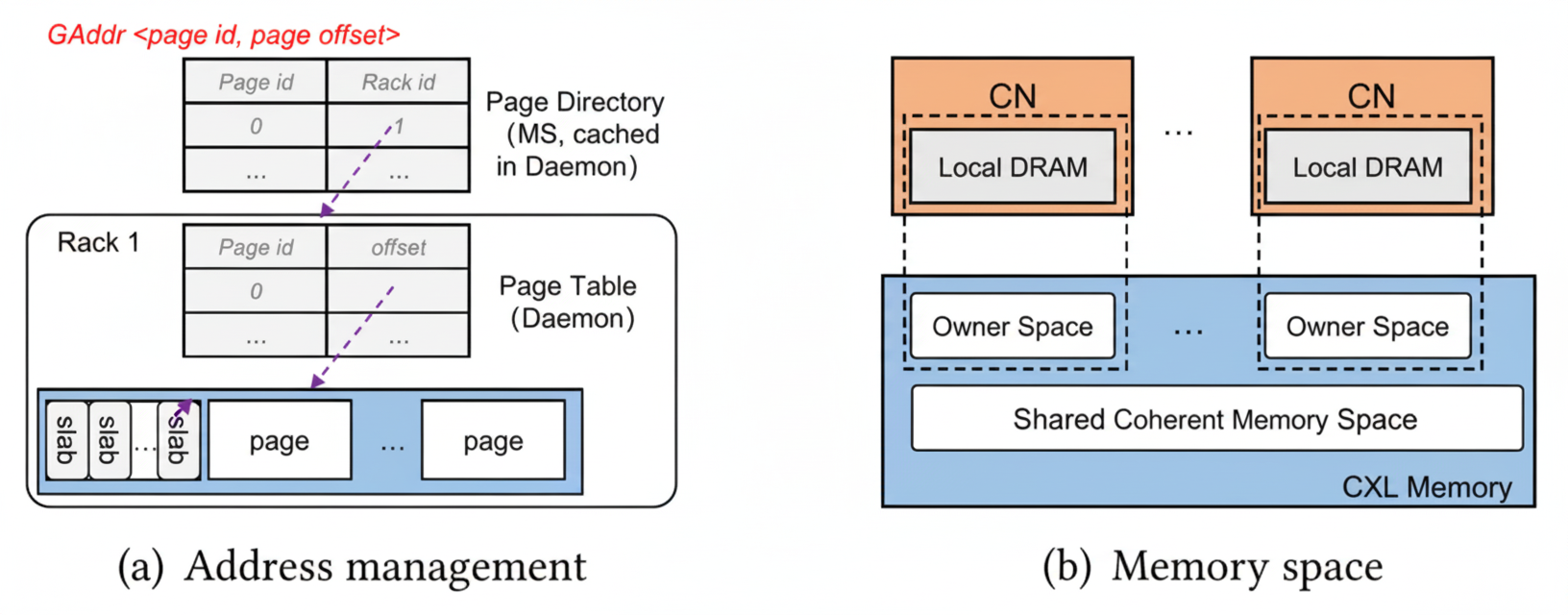
Figure 4. Global memory and address management
Memory space includes CXL memory plus local DRAM in CNs and the Daemon. Each CN maintains small local DRAM caches for page tables and hotness metadata for local-rack pages. The Daemon caches page directory and remote racks' page tables. CXL memory consists of a large shared coherent space and per-CN owner regions used as CXL caches for write buffering and page caching.
API: Rcmp exposes a memory pool API for open/close, allocate/free, read/write, and lock/unlock operations. Open returns a PoolContext pointer on success. Allocation assigns a free page in CXL memory and updates page tables; if no local free page exists, allocation follows a proximity policy or selects a remote rack using hashing. Read/write operations use CXL for local-rack accesses and RDMA for remote-rack accesses. Locking primitives (RLock/WLock) enable concurrency control.
Workflow: On a read/write request from an application in a CN, Rcmp first searches the local cached page table. If present, the CN accesses CXL via load/store. If not present, the CN consults the MS (page directory cached in the Daemon) to locate the rack hosting the page and then communicates with the corresponding Daemon. For local-rack accesses, the Daemon supplies the CXL offset and the CN performs CXL accesses directly. For remote-rack accesses, the Daemon communicates with the remote Rack Daemon to obtain the page offset and then performs one-sided RDMA READ/WRITE to access the data. If the page is hot, swapping may be triggered to migrate it locally. RLock and WLock operations enable read caching and write buffering to reduce cross-rack traffic.
5.2 Intra-rack Communication
CNs must communicate with the Daemon to determine local vs. remote accesses. To prevent communication blocking due to large latency differences, Rcmp uses two ring buffer structures.
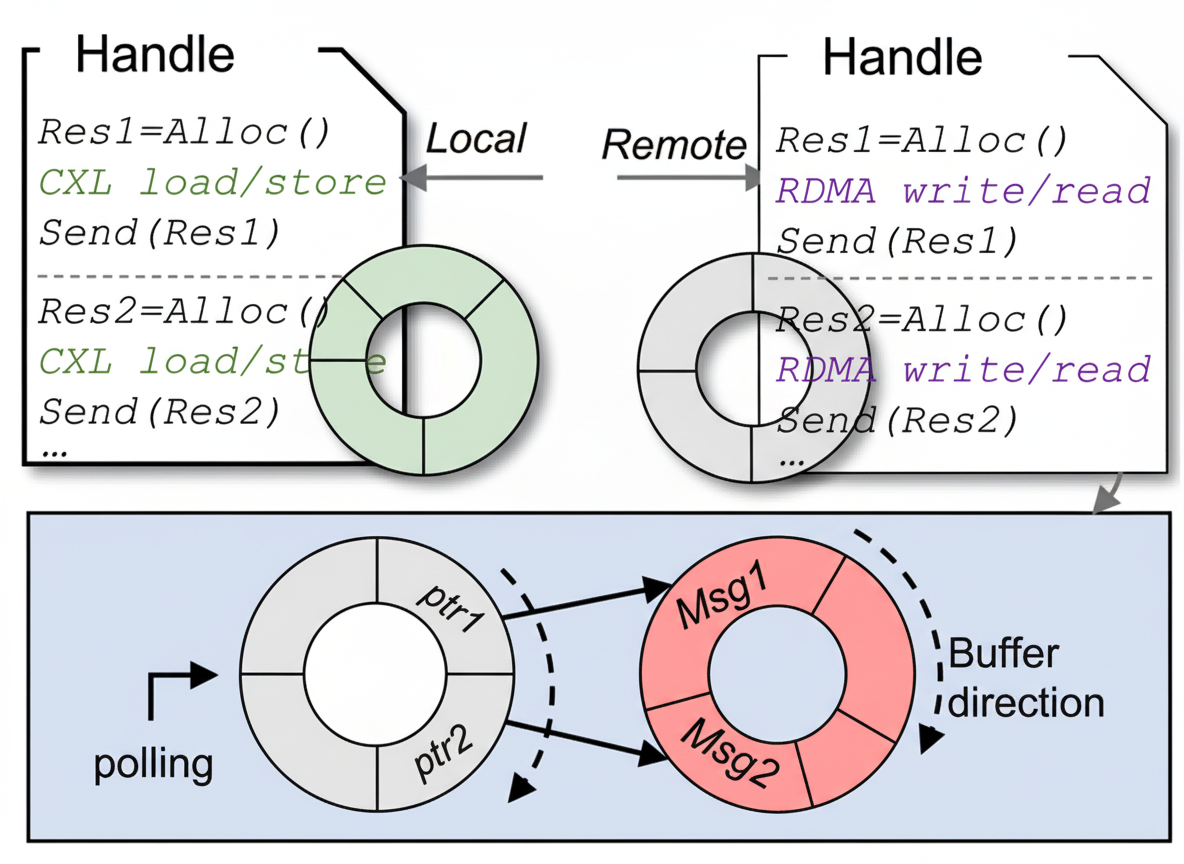
Figure 5. Intra-rack communication mechanism
For local-rack accesses, Rcmp uses a conventional ring buffer. Since CXL accesses are extremely low latency, contention is manageable. The ring and RDMA QP can be shared across threads using Flock-like techniques for high concurrency.
For remote-rack accesses, Rcmp uses a two-layer ring buffer: a polling buffer holds fixed-size metadata entries (type, size, pointer to data buffer), and a data buffer stores variable-length message payloads. Messages complete into the data buffer and then a metadata pointer is enqueued into the polling buffer. Daemons poll the polling buffer to process ready messages in arrival order without head-of-line blocking. The implementation uses a lock-free KFIFO for the polling buffer and a regular ring for the data buffer.
5.3 Hot-page Identification and Swapping
Rcmp identifies frequently accessed remote pages and migrates them to the local rack to reduce expensive remote accesses.
Hot-page identification: Each page maintains three variables: Curr (read count), Curw (write count), and lastTime (timestamp of last access). On each access, compute Δt = current_time – lastTime. If Δt exceeds a lifetime threshold Tl, Curr and Curw are reset. Page hotness is computed as α × (Curr + Curw) + 1, where α = e^(?λΔt) is an exponential decay factor. Curr or Curw is incremented depending on access type. If hotness exceeds threshold Hp, the page is considered hot. If Curr/Curw > Rrw it is read-hot. Thresholds are configurable. Local DRAM caches maintain hotness for local pages, while remote hotness metadata is kept at the Daemon. Per-page metadata is small (about 32 bytes) and updates are O(1).
Hot-page swapping and caching: Rcmp implements a user-level swap mechanism that differs from kernel-driven swapping used by page-based systems. Swap requests are queued in a FIFO to avoid duplicate swaps for the same page. The swapping Daemon selects a victim page to free (or uses heat comparisons across racks to avoid migrating pages that are hotter at the remote rack). A compare-based approach prevents ping-pong migrations: if the remote rack has higher hotness, the swap is rejected and the requesting rack may instead cache a read-hot page in its CXL memory. Actual page exchange is performed using two one-way RDMA operations and updated page tables are propagated to CNs.
5.4 CXL Caches and Synchronization
Rcmp provides cache-line-granularity lock-coupled caching and synchronization via Lock/Unlock primitives. For write owners obtained via WLock, the owner CN may buffer fine-grained writes in a per-CN CXL write buffer. When the buffer is full or the WLock is released, a background thread asynchronously flushes batched writes to the remote rack. The implementation uses two alternating buffers; when one fills, writes go into the other. Buffers are implemented with high-concurrency SkipList structures similar to in-memory LSM components.
For RLock, pages may be cached in a CXL page cache. When a cached page is about to be written or an RLock is released, the cache entry is invalidated. Rack-internal coherence is provided by CXL and requires no additional mechanism.
5.5 RRPC: RDMA-optimized RPC Framework
RRPC adaptively selects between pure RPC, RPC+one-sided RDMA, and RPC zero-copy modes based on data size and structure. Guided by communication tests, RRPC uses 512 B as a practical threshold:
- Pure RPC mode for small transfers < 512 B (e.g., locking, index lookups, allocation).
- RPC + one-sided RDMA for unstructured large or unknown-size objects: first obtain remote address via RPC, allocate local space, then fetch via RDMA READ.
- RPC zero-copy for structured, fixed-size large objects: RPC carries a local buffer address and the server performs an RDMA WRITE directly into that buffer.
Once a page address is learned via RPC, Rcmp caches it and subsequent accesses use one-sided RDMA. RRPC also employs QP sharing, doorbell batching, and other RDMA optimizations.
06. Evaluation
We evaluate Rcmp with microbenchmarks and a YCSB-driven key-value workload. We describe the implementation and experimental setup, compare Rcmp to four state-of-the-art remote memory systems, and analyze contributions of Rcmp's key techniques.
6.1 Implementation
Rcmp is a user-level system implemented in 6483 lines of C++. Default page size is 2 MB; write buffer size is 64 MB; the page cache is an LRU cache of 50 pages. Hotness parameters default to Tl=100 s, Hp=4, λ=0.04, Rrw=0.9. The RRPC framework is based on eRPC.
Although CXL-capable FPGA prototypes are emerging, we chose a NUMA-based simulation for CXL memory because early FPGA prototypes show higher latencies (>250 ns) and NUMA provides a cache-coherent load/store model similar to CXL for evaluation purposes.
6.2 Experimental Setup
All experiments run on five servers, each with dual Intel Xeon Gold 5218R CPUs @ 2.10 GHz, 128 GB DRAM, and a 100 Gbps Mellanox ConnectX-5 RNIC. OS is Ubuntu 20.04 with Linux 5.4.0-144. NUMA interconnect latencies between node 0 and 1 are 138.5 ns and 141.1 ns; node-local latencies are 93 ns and 89.7 ns. Rcmp is compared to: (1) Fastswap (page-based), (2) FaRM (object-based), (3) GAM (RDMA-based cache coherence), and (4) CXL-over-Ethernet (prototype). Fastswap and GAM run from open-source code; FaRM code was taken from prior reimplementations. CXL-over-Ethernet is prototyped using Rcmp codebase with RDMA as the transport for fairness.
Deployment: One server simulates one rack with a small compute pool and a memory pool (simulated CXL memory). For Rcmp and CXL-over-Ethernet, CNs run as separate processes on one CPU socket and a headless MN simulates CXL memory. The memory pool is about 100 GB DRAM per rack, and each compute pool has 1 GB local DRAM. Microbenchmarks use random reads/writes with default data size 64 B and 100 M items.
6.3 Microbenchmark Results
We run random read/write microbenchmarks across two racks and measure average latency across ten runs for different data sizes. Each rack preallocates an equal number of pages for fairness.
Overall performance: In two-rack setups, Rcmp achieves lower and more stable read/write latencies (<3.5 μs write, <3 μs read). Compared to other systems, Rcmp reduces write latency by 2.3–8.9x and read latency by 2.7–8.1x. Fastswap shows the highest latency (>12 μs) due to page-fault driven remote page fetches. FaRM achieves about 8 μs due to object-based management and efficient message primitives. GAM performs well for <512 B data (≈5 μs) but degrades for large cross-cache-line updates because it must maintain coherence state across multiple lines. CXL-over-Ethernet yields moderate latencies (6–8 μs) but fails to fully leverage CXL low-latency benefits since it relies on network transport and lacks network optimizations.
Scalability: We evaluate scalability by increasing clients and racks. With up to five racks simulated, Rcmp scales linearly with client count up to a point; a single Daemon per rack becomes a bottleneck at high client counts, which Rcmp mitigates by using multiple Daemons per rack in larger deployments. Fastswap scales nearly linearly due to page-fault driven remote accesses, while FaRM scales well for reads due to efficient primitives. GAM shows limited scalability beyond a few threads due to user-space library overhead and per-access locking for consistency. CXL-over-Ethernet suffers from proxy bottlenecks in the compute pool, limiting its scalability.
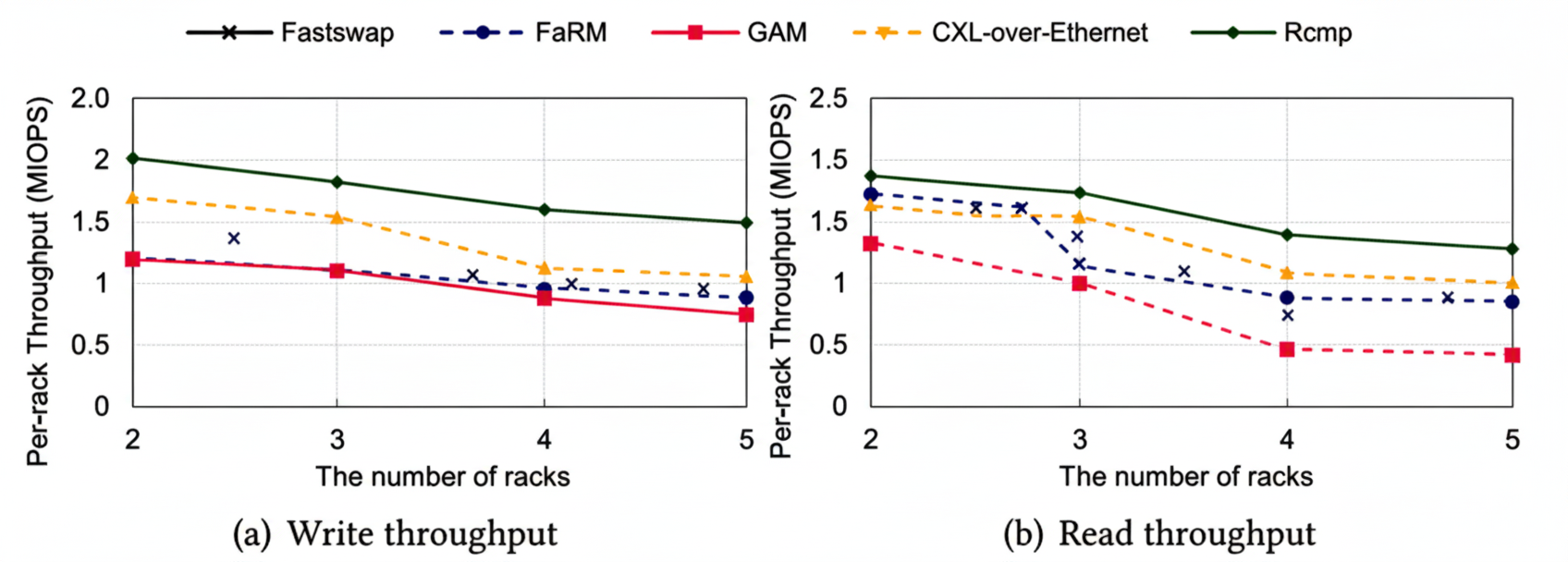
Figure 6. Per-rack throughput with varying racks
6.4 Key-value Store and YCSB Workloads
We evaluate a hash-table-based key-value store under six YCSB workloads. The dataset contains 100 M key-value pairs of 64 B each, with both uniform and Zipfian (skew 0.99) distributions, run in a two-rack environment. Throughput is normalized to Fastswap.
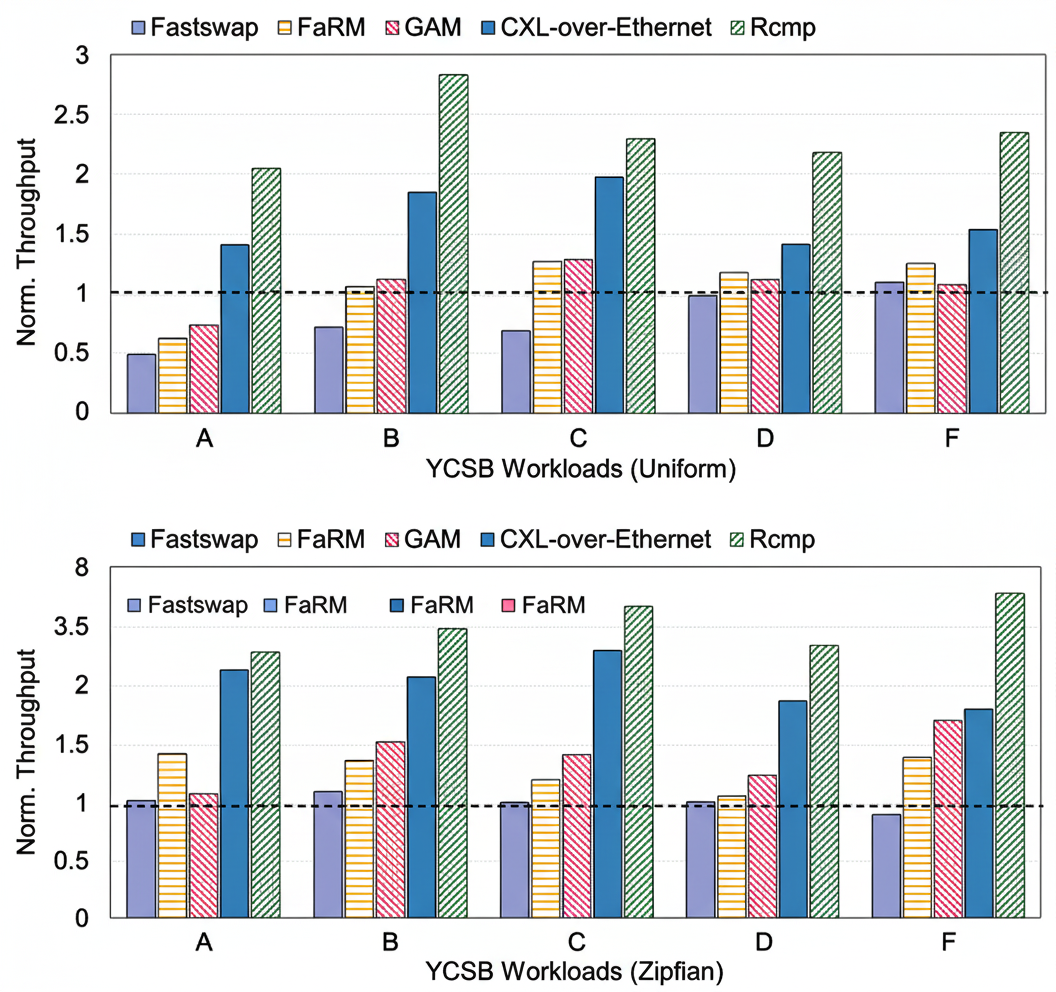
Figure 7. Normalized throughput for YCSB workloads
Results: Rcmp outperforms RDMA-only systems by 2–4x across workloads by leveraging CXL for low-latency local accesses and by reducing cross-rack traffic via hot-page migration and caching. For read-heavy workloads (YCSB B, C, D), Rcmp achieves around 3x higher throughput than Fastswap by avoiding page-fault overhead and reducing cross-rack transfers. For write-heavy workloads (YCSB A, F), throughput improves by about 1.5x. Under Zipfian skew, Rcmp gains up to 3.8x due to effective hot-page migration to the local rack, significantly reducing remote access cost. Other systems show improvements via caching benefits but are limited by local DRAM capacity, coherence overheads, or intrusive modifications required by object-based designs.
6.5 Impact of Key Techniques
We evaluate the individual contributions of Rcmp components: two-layer ring buffer, hot-page swapping, CXL write buffering, and RRPC. Figure 18 shows cumulative improvements from a baseline (single-ring buffer, eRPC) to the full Rcmp design. Rcmp-only-CXL denotes an idealized intra-rack-only CXL solution representing a performance upper bound. The evaluated techniques reduce the gap to this bound, though tail latency and read throughput remain areas for further improvement.
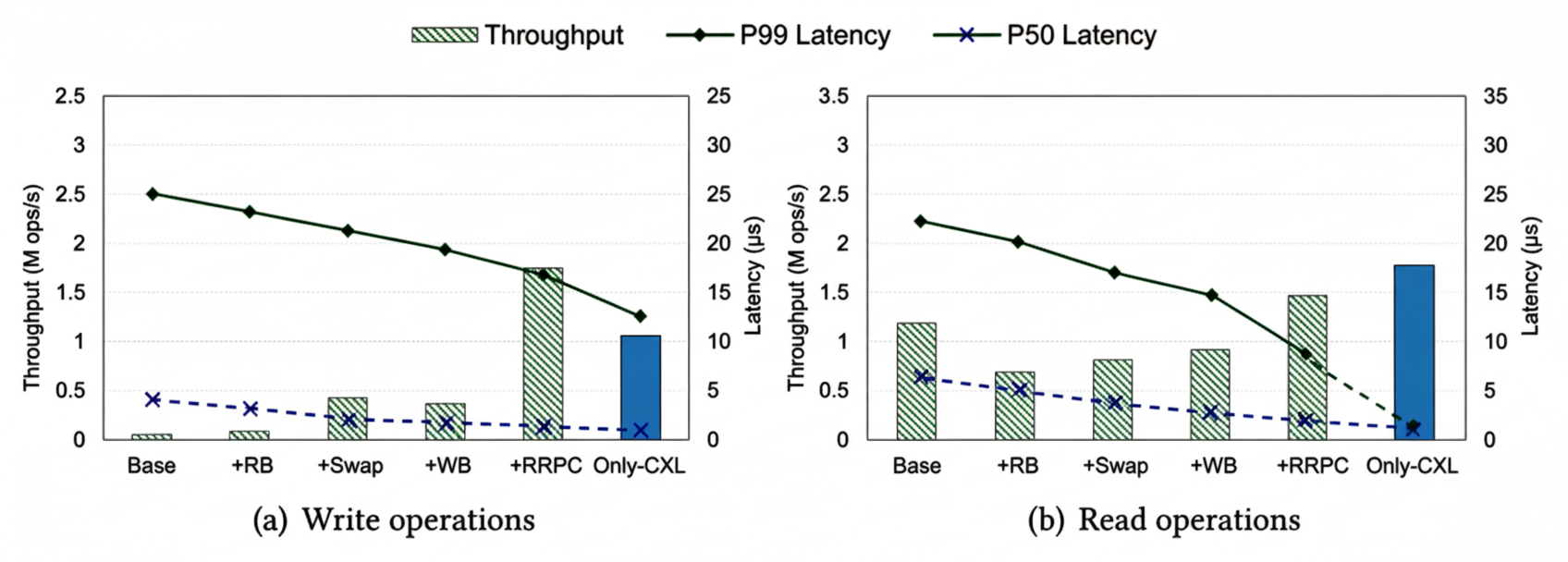
Figure 8. Performance contributions of techniques
Ring buffers: Two-layer ring buffers reduce p50/p99/p999 latencies by up to 21.7%, 30.9%, and 51.5% respectively by avoiding head-of-line blocking between local low-latency and remote high-latency accesses.
Hot-page swapping: In skewed workloads, hot-page migration significantly improves throughput. With Hp=3, throughput increases ~5% for uniform and ~35% for Zipfian workloads. Too-aggressive swapping (low Hp) hurts performance due to frequent migrations (Figure 20).
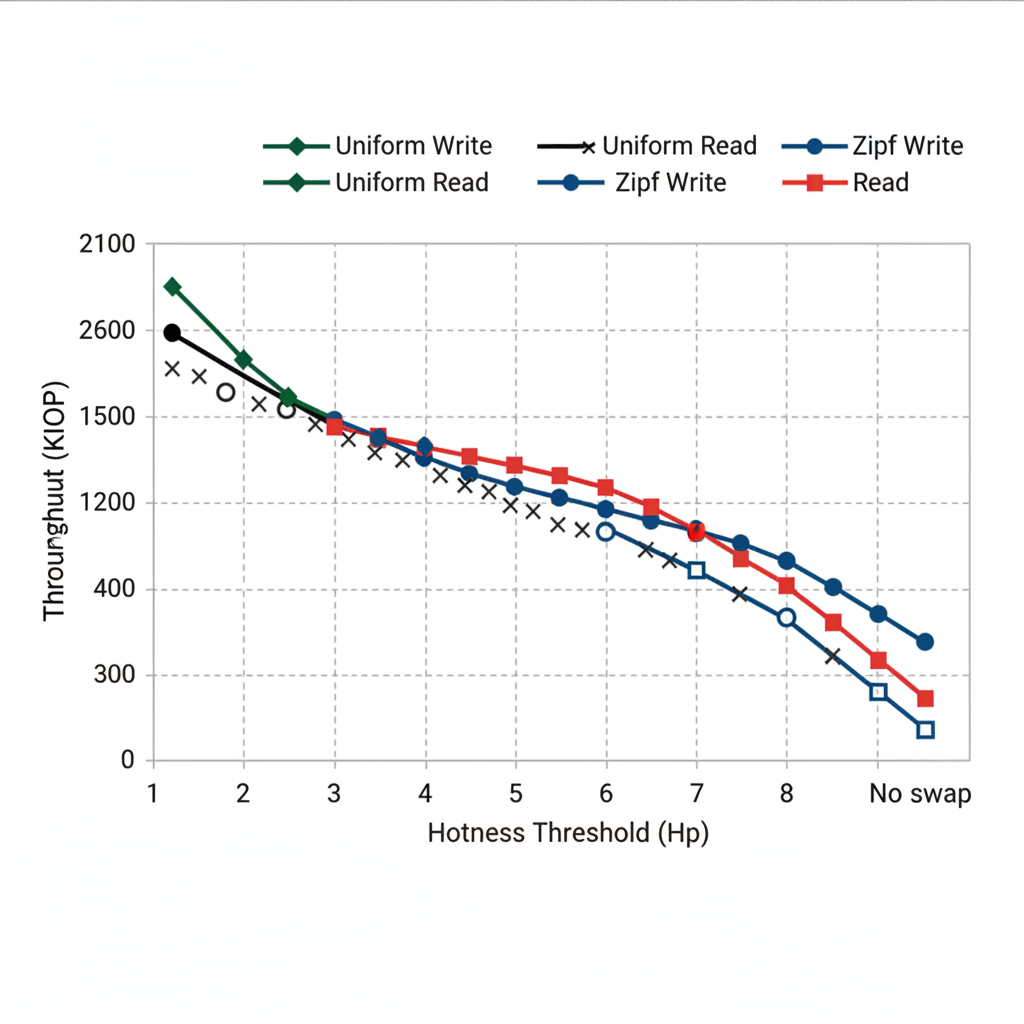
Figure 9. Hot-page swapping
Write buffering: For WLock scenarios, the write buffer improves throughput by up to 1.6x for sizes below 256 B by batching writes and offloading them from the critical path. Benefits diminish for larger payloads due to background thread CPU overhead; Rcmp disables buffering for payloads over 256 B.
RRPC: Compared to eRPC, eRPC+one-sided RDMA, and FaRM RPC, RRPC achieves 1.33–1.89x higher throughput than eRPC+RDMA and 1.5–2x higher than eRPC for large transfers by switching modes at 512 B and applying RDMA optimizations (Figure 10).
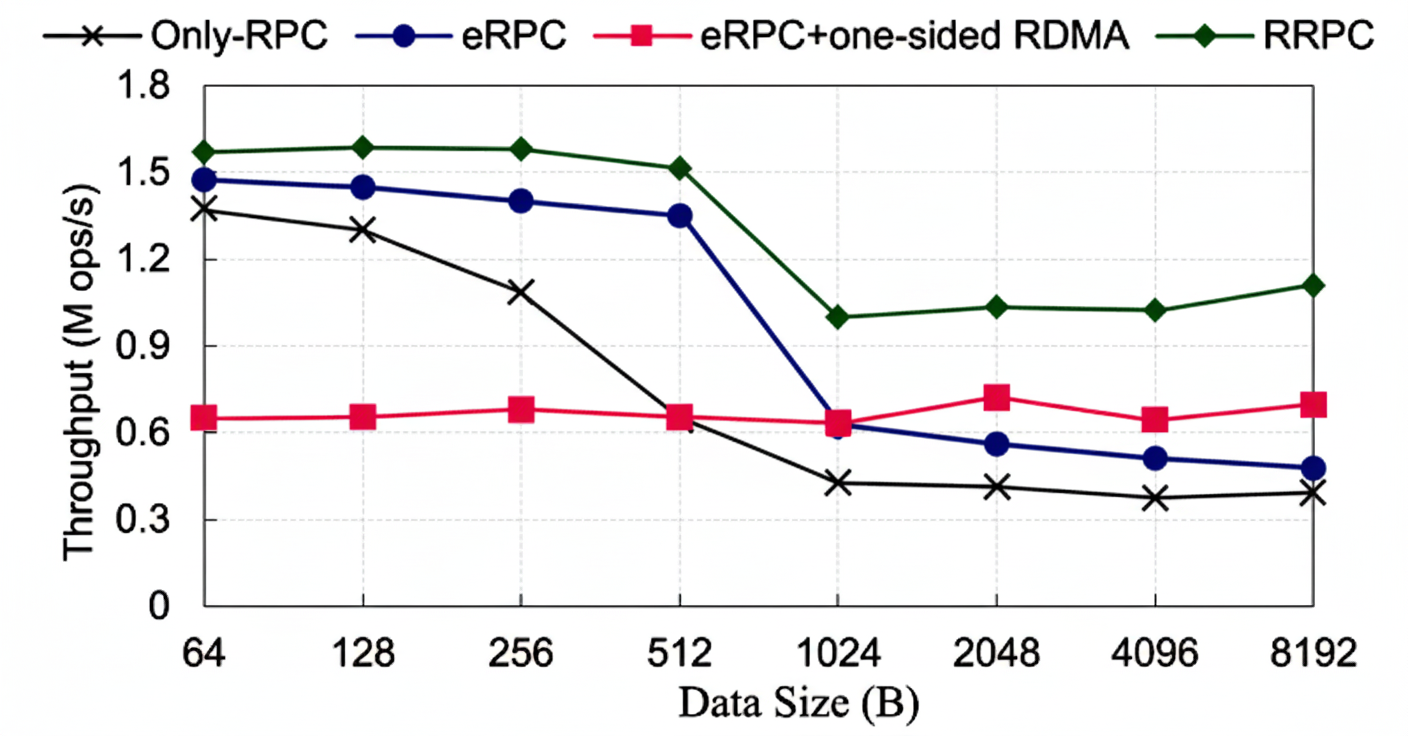
Figure 10. RRPC framework
6.6 Discussion
Decentralization: Centralized MS can be a bottleneck. Rcmp leverages local CN DRAM caches to reduce MS pressure and is exploring decentralized designs with consistent hashing and ZooKeeper-style membership management for reliability.
Cached I/O: Rcmp currently uses an uncached access model to avoid cross-rack coherence overhead. Decentralized extensions could enable CXL-based caching across racks with ZooKeeper-assisted consistency management.
Transparency: To ease migration of legacy applications, Rcmp integrates with FUSE to provide a distributed file system interface usable without source changes, similar to other systems. Usage instructions are provided with the Rcmp codebase.
07. Related Work
RDMA-based remote memory work includes page-based systems such as Infiniswap, LegoOS, Clover, and Fastswap, which use pages and suffer I/O amplification. Object-based systems like FaRM, AIFM, and Gengar expose object interfaces optimized for RDMA but often require larger local memory or intrusive changes. Communication optimizations such as lock-free rings, QP sharing, and doorbell batching have been explored extensively. Cache-coherent systems like GAM provide RDMA-based coherence at the cost of high metadata overhead. CXL-based disaggregation efforts such as DirectCXL and Pond demonstrate low-latency intra-rack benefits but face distance and deployment limits. CXL-over-Ethernet and FPGA-based prototypes attempt to extend CXL across networks but do not fully exploit CXL latency advantages.
08. Conclusion and Future Work
This work presents Rcmp, a hybrid RDMA+CXL memory pool system that combines CXL for intra-rack low-latency access and RDMA for cross-rack scalability. Rcmp addresses RDMA/CXL mismatches with global memory and address management, differentiated communication buffers to avoid blocking, hot-page identification and migration, lock-coupled fine-grained caching, and an RDMA-optimized RPC framework. Evaluations demonstrate that Rcmp outperforms RDMA-only systems across microbenchmarks and YCSB workloads, delivering lower latency and higher throughput without introducing excessive overhead.
Future work includes experiments with real CXL hardware, decentralized metadata and cache designs, and support for additional storage tiers such as persistent memory, SSD, and HDD.
References
[1] FUSE (Filesystem in Userspace). libfuse. Retrieved December 8, 2023.
[2] M. K. Aguilera et al. 2023. Memory disaggregation: Why now and what are the challenges. ACM SIGOPS Operating Systems Review 57, 1 (2023), 38–46.
[3] E. Amaro et al. 2020. Can far memory improve job throughput? In EuroSys.
[4] J. Bae et al. 2021. FlashNeuron: SSD-enabled large-batch training. In FAST'21.
[5] L. A. Barroso et al. 2013. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines.
[6] B. Benton. 2017. CCIX, GEN-Z, OpenCAPI: Overview & comparison.
[7] S. S. Biswas. 2023. Role of ChatGPT in public health. Annals of Biomedical Engineering 51, 5 (2023), 868–869.
[8] J. Bonwick. 1994. The slab allocator: An object-caching kernel memory allocator. In USENIX Summer 1994.
[9] Q. Cai et al. 2018. Efficient distributed memory management with RDMA and caching. PVLDB 11, 11 (2018), 1604–1617.
[10] I. Calciu et al. 2021. Rethinking software runtimes for disaggregated memory. In VEE'21.
[11] W. Cao et al. 2021. PolarDB Serverless: A cloud native database for disaggregated data centers. In SIGMOD'21.
[12] Z. Cao and S. Dong. 2020. Characterizing RocksDB workloads. In FAST'20.
[13] Y. Cheng et al. 2018. Analyzing Alibaba's co-located datacenter workloads. In Big Data'18.
[14] A. Cockcroft. 2023. Supercomputing Predictions: Custom CPUs, CXL3.0, and Petalith Architectures.
[15] B. F. Cooper et al. 2010. Benchmarking cloud serving systems with YCSB. In SoCC'10.
[16] Anritsu and KYOCERA. 2023. PCI Express 5.0 Optical Signal Transmission Test.
[17] A. Dragojevi? et al. 2014. FaRM: Fast remote memory. In NSDI'14.
[18] Z. Duan et al. 2021. Gengar: An RDMA-based distributed hybrid memory pool. In ICDCS'21.
[19] L. Floridi and M. Chiriatti. 2020. GPT-3: Its nature, scope, limits, and consequences. Minds and Machines 30 (2020), 681–694.
[20] P. X. Gao et al. 2016. Network requirements for resource disaggregation. In OSDI'16.
[21] D. Gouk et al. 2022. Direct access, high-performance memory disaggregation with DirectCXL. In USENIX ATC'22.
[22] J. Gu et al. 2017. INFINISWAP. In NSDI'17.
[23] P. Hunt et al. 2010. ZooKeeper: Wait-free coordination for internet-scale systems.
[24] A. Kalia et al. 2019. Datacenter RPCs can be general and fast. In NSDI'19.
[25] A. Kalia et al. 2014. Using RDMA efficiently for key-value services. In SIGCOMM'14.
[26] A. Kalia et al. 2016. FaSST: Fast, scalable and simple distributed transactions. In OSDI'16.
[27] K. Katrinis et al. 2016. dReDBox project vision. In DATE'16.
[28] Y. Kwon and M. Rhu. 2018. Memory-centric HPC systems for deep learning. In MICRO'18.
[29] S. Lee et al. 2021. Mind: In-network memory management for disaggregated data centers. In SOSP'21.
[30] H. Li et al. 2023. Pond: CXL-based memory pooling for cloud platforms. In ASPLOS'23.
[31] H. M. Makrani et al. 2018. Main-memory requirements of big data applications. In CCGrid'18.
[32] H. Al Maruf et al. 2023. TPP: Transparent page placement for CXL-enabled tiered-memory. In ASPLOS'23.
[33] H. Al Maruf et al. 2021. Memtrade: A disaggregated-memory marketplace for public clouds. arXiv:2108.06893.
[34] S. Matsuoka et al. 2023. Myths and legends in high-performance computing. Int. J. HPC Applications 37, 3-4 (2023), 245–259.
[35] G. Michelogiannakis et al. 2022. A case for intra-rack resource disaggregation in HPC. TACO 19, 2 (2022).
[36] S. K. Monga et al. 2021. Flock: Scaling RDMA RPCs. In SOSP'21.
[37] I. Peng et al. 2020. On memory underutilization in HPC. In SBAC-PAD'20.
[38] The Next Platform. 2022. Just How Bad Is CXL Memory Latency?
[39] A. Raybuck et al. 2021. HeMem: Scalable tiered memory management. In SOSP'21.
[40] C. Reiss et al. 2012. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. In SoCC'12.
[41] Z. Ruan et al. 2020. AIFM: Application-integrated far memory. In OSDI'20.
[42] R. Salmonson et al. 2019. PCIe Riser Extension Assembly.
[43] A. Shamis et al. 2019. Fast general distributed transactions with opacity. In SIGMOD'19.
[44] Y. Shan et al. 2018. LegoOS: A disseminated OS for resource disaggregation. In OSDI'18.
[45] D. D. Sharma and I. Agarwal. 2022. Compute Express Link specification.
[46] N. Shenoy. 2023. A Milestone in Moving Data.
[47] V. Shrivastav et al. 2019. Shoal: A network architecture for disaggregated racks. In NSDI'19.
[48] Intel. 2019. Intel Rack Scale Design Storage Services API Specification.
[49] Y. Sun et al. 2023. Demystifying CXL memory with genuine CXL-ready systems. arXiv:2303.15375.
[50] Linus Torvalds. Linux kernel kfifo implementation.
[51] S.-Y. Tsai et al. 2020. Disaggregating persistent memory exploration. In USENIX ATC'20.
[52] S. Van Doren. 2019. HOTI 2019: Compute express link talk.
[53] A. Verbitski et al. 2017. Amazon Aurora: Design considerations. In SIGMOD'17.
[54] M. Vuppalapati et al. 2020. Building an elastic query engine on disaggregated storage. In NSDI'20.
[55] J. Wahlgren et al. 2022. Evaluating CXL-enabled memory pooling for HPC. arXiv:2211.02682.
[56] C. Wang et al. 2023. CXL over Ethernet: FPGA-based memory disaggregation. In FCCM'23.
[57] X. Wei et al. 2020. Fast RDMA-based ordered key-value store. In OSDI'20.
[58] Q. Xin et al. 2003. Reliability mechanisms for very large storage systems. In MSST'03.
[59] J. Yang et al. 2020. Analysis of in-memory cache clusters at Twitter. In OSDI'20.
[60] Q. Yang et al. 2022. Performance evaluation on CXL-enabled hybrid memory pool. In NAS'22.
[61] Y. Yuan et al. 2023. RAMBDA: RDMA-driven acceleration framework. In HPCA'23.
[62] E. Zamanian et al. 2016. The end of a myth: Distributed transactions can scale. arXiv:1607.00655.
[63] M. Zhang et al. 2022. FORD: RDMA-based distributed transactions for disaggregated persistent memory. In FAST'22.
[64] Y. Zhang et al. 2021. Sherman: Write-optimized distributed B+Tree on disaggregated memory. arXiv:2112.07320.
[65] Y. Zhang et al. 2021. Towards cost-effective cloud database deployment via memory disaggregation. PVLDB 14, 10 (2021), 1900–1912.
[66] T. Ziegler et al. 2022. ScaleStore: A fast and cost-efficient storage engine using DRAM, NVMe, and RDMA. In SIGMOD'22.
[67] P. Zuo et al. 2021. One-sided RDMA-conscious extendible hashing for disaggregated memory. In USENIX ATC'21.