At Hot Chips 35 in 2023, SK hynix presented expertise in the memory domain and described approaches to meet major demands of large-scale computing for artificial intelligence. SK hynix demonstrated its work on domain-specific memory for "memory-centric computing", seeking ways to mitigate one of the largest challenges in AI compute: the relationship between memory capacity and bandwidth and available compute resources. This article compiles that systematic presentation and clarifies key points.
Problem Statement
The issue SK hynix addressed is that the cost of generative AI inference is very high. Costs involve not only compute but also power consumption, interconnects, and memory, which significantly increase total expenditure.
Large Transformer Models' Compute and Memory Demands
For large Transformer models in particular, memory is a primary challenge. Models require large volumes of data and are often constrained by memory capacity and bandwidth.
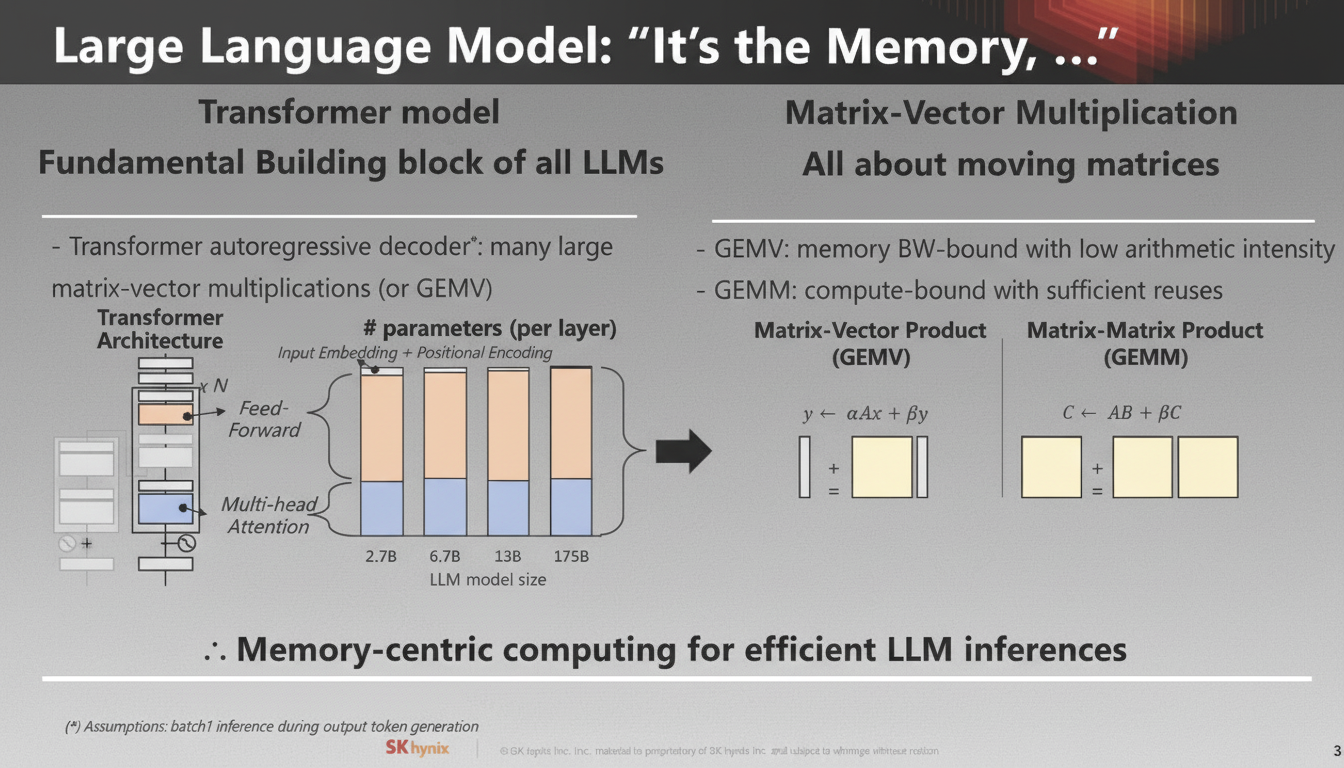
SK hynix argues that the AI hardware industry needs more than plain memory: it needs different types of memory with built-in compute capabilities, including domain-specific memory. The company is positioning memory with compute as a way to add value in the stack.

"Compute-in-Memory" or SK hynix AiM
In their GDDR6 implementation, each memory tile includes its own 1 GHz processing unit and can provide 512 GB/s of internal bandwidth.

Matrix-vector multiplication (GEMV) is performed inside memory for AI compute: the weight matrix data comes from the memory tiles, while vector data comes from a global buffer.
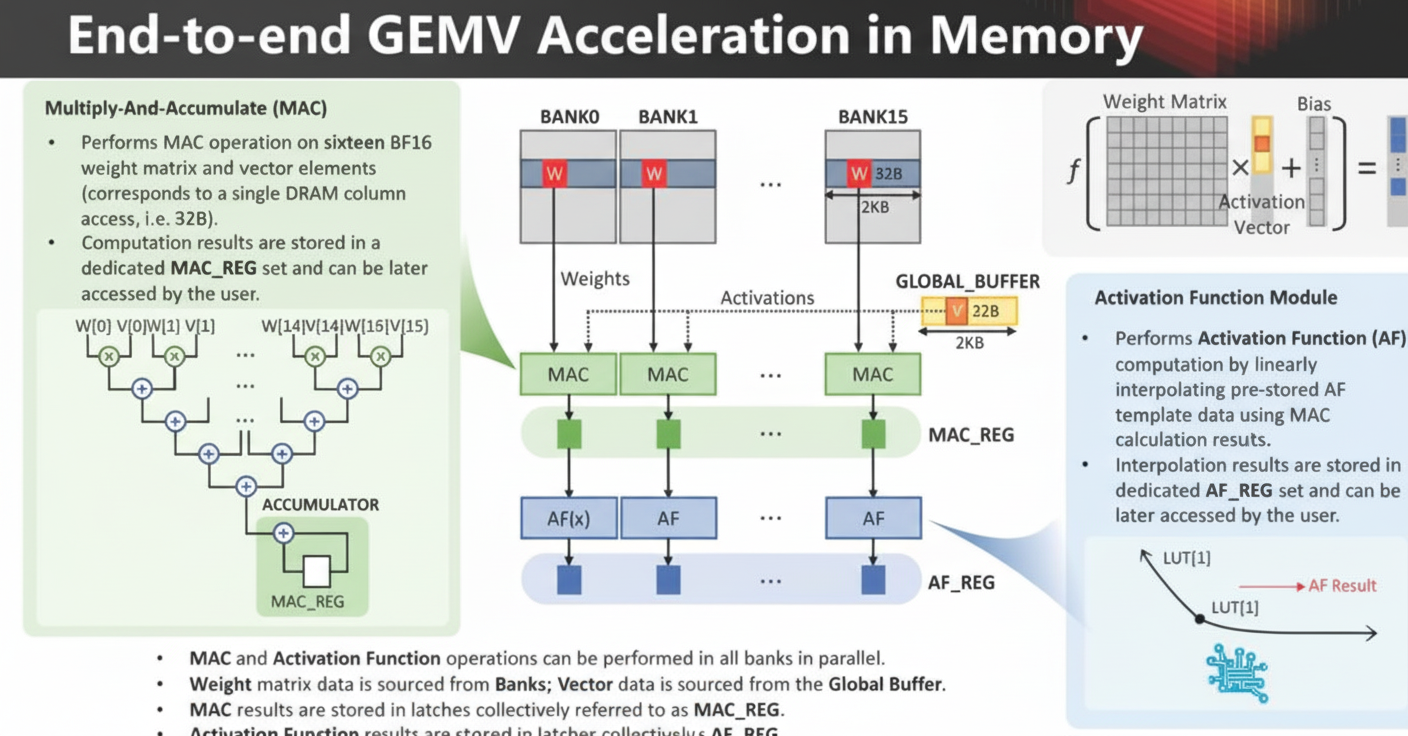
AiM in memory uses specific memory commands to perform computation.

Memory scalability and the AiM compute resources required by large language models were discussed.

Using this type of AiM presents major challenges: mapping at the software level, designing hardware architectures for AiM, and then providing interfaces. These are key barriers to adoption.
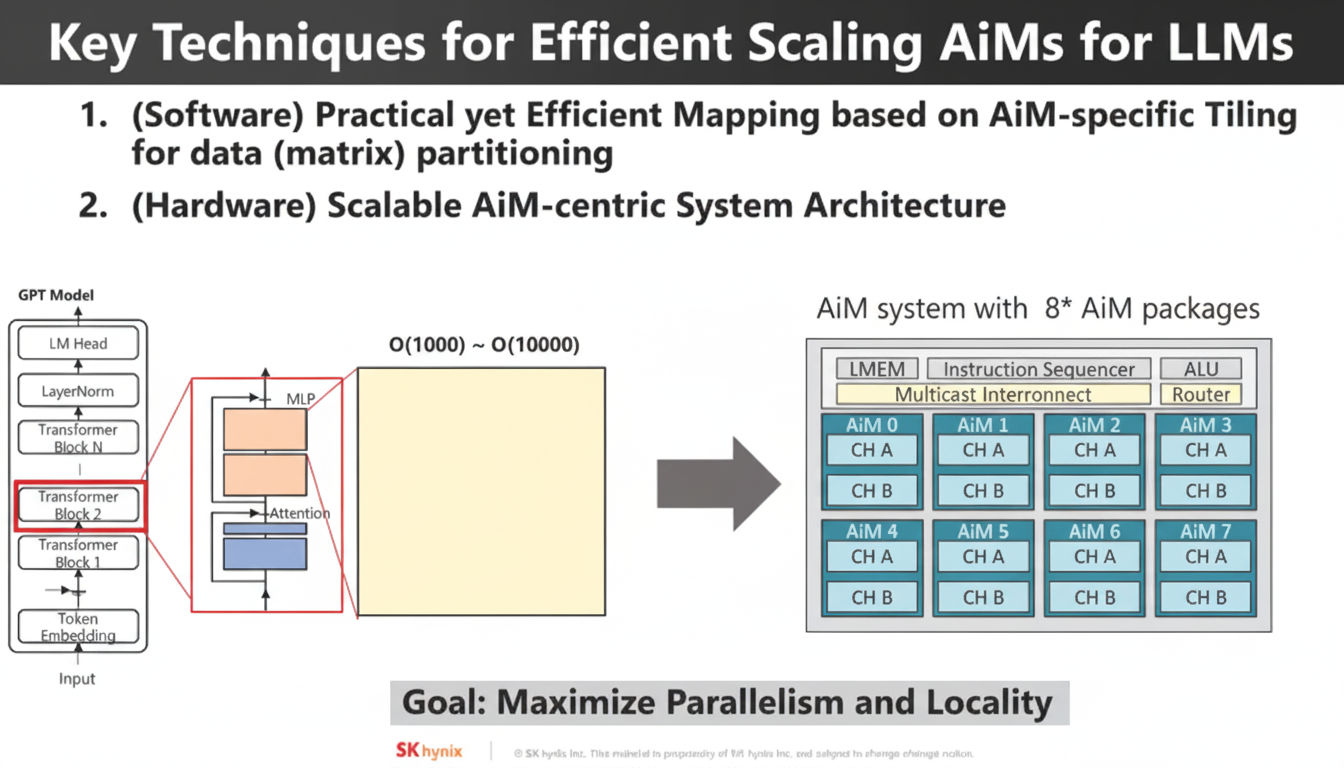
Mapping Problems to AiM
Research is needed on how to map workloads and algorithms to AiM-capable memory.
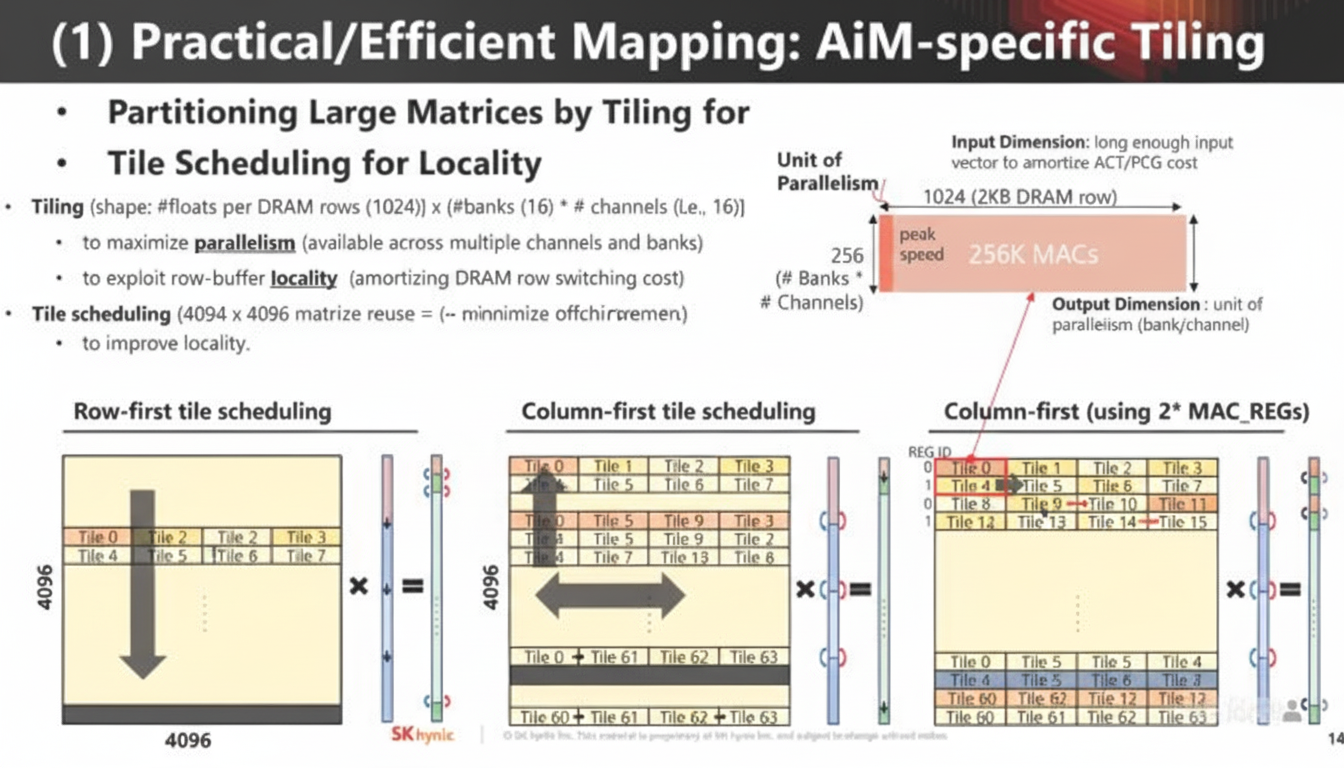
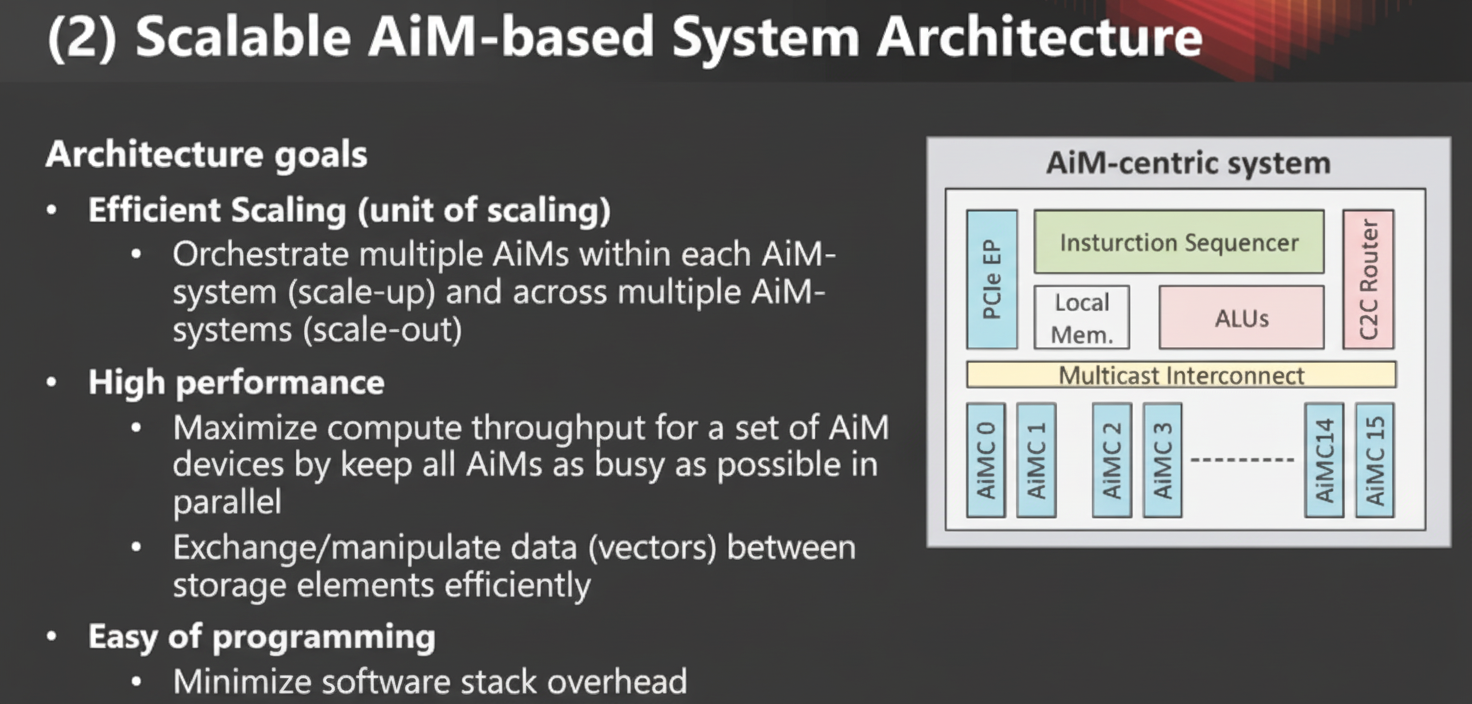
System Architecture and Scalability
System architecture must support scaling and extensibility to handle large models.
Key components of an AiM architecture include an AiM controller, scalable multicast interconnect, routers, compute units (ALUs), and an instruction sequencing controller.
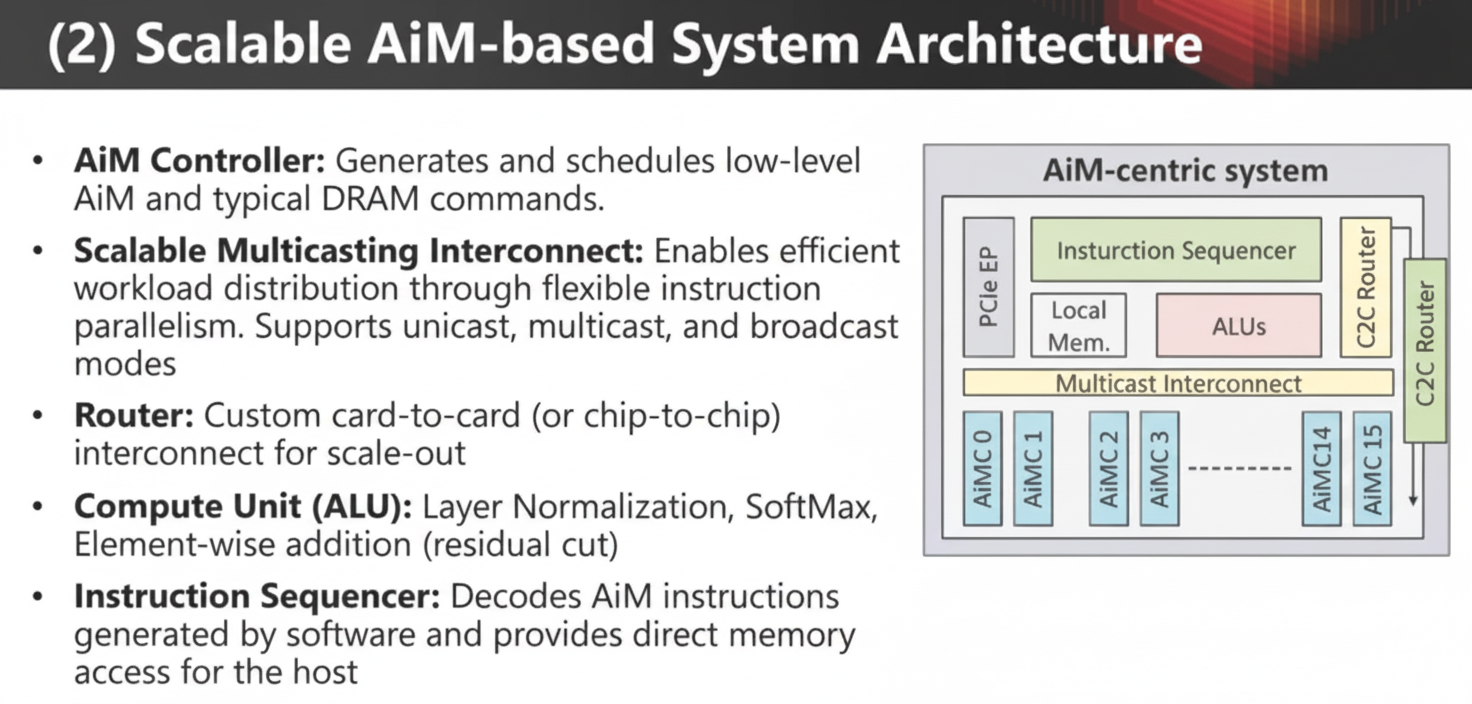
Matrix-vector accumulation functions are critical to AI workloads. AiM employs an instruction set similar to CISC to manage these functions.
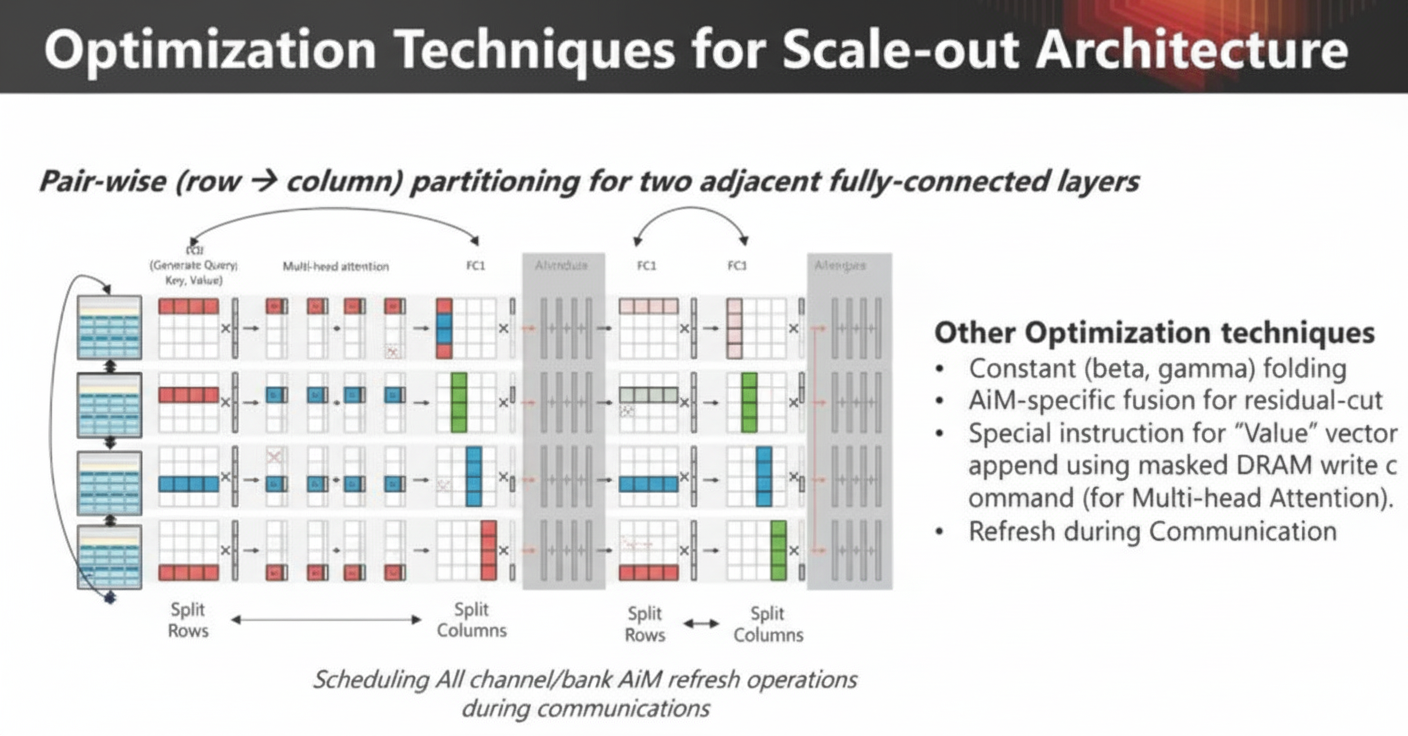
Optimizations
New architectures often contain subtle differences that can be exploited to improve performance.
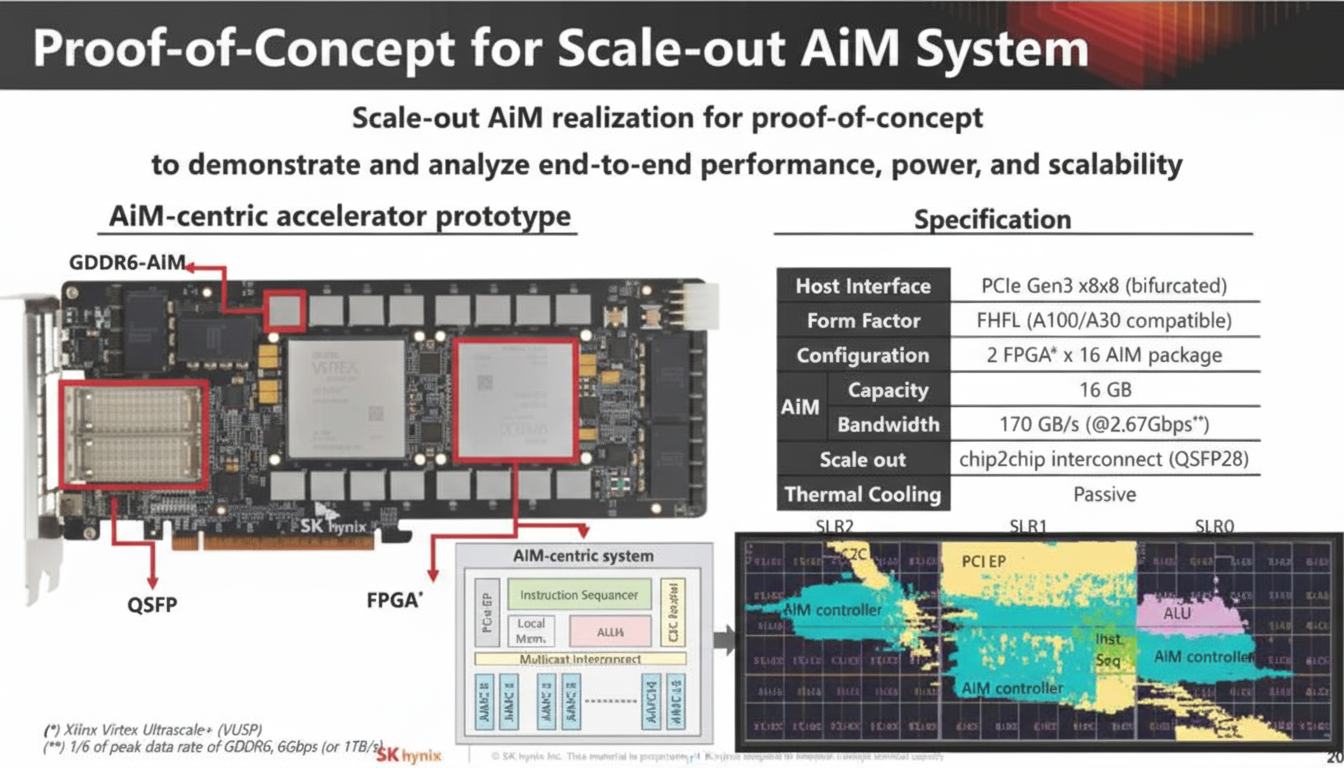
SK hynix demonstrated a proof-of-concept GDDR6 AiM solution using two FPGAs, moving beyond abstract discussion to a tangible demonstration.
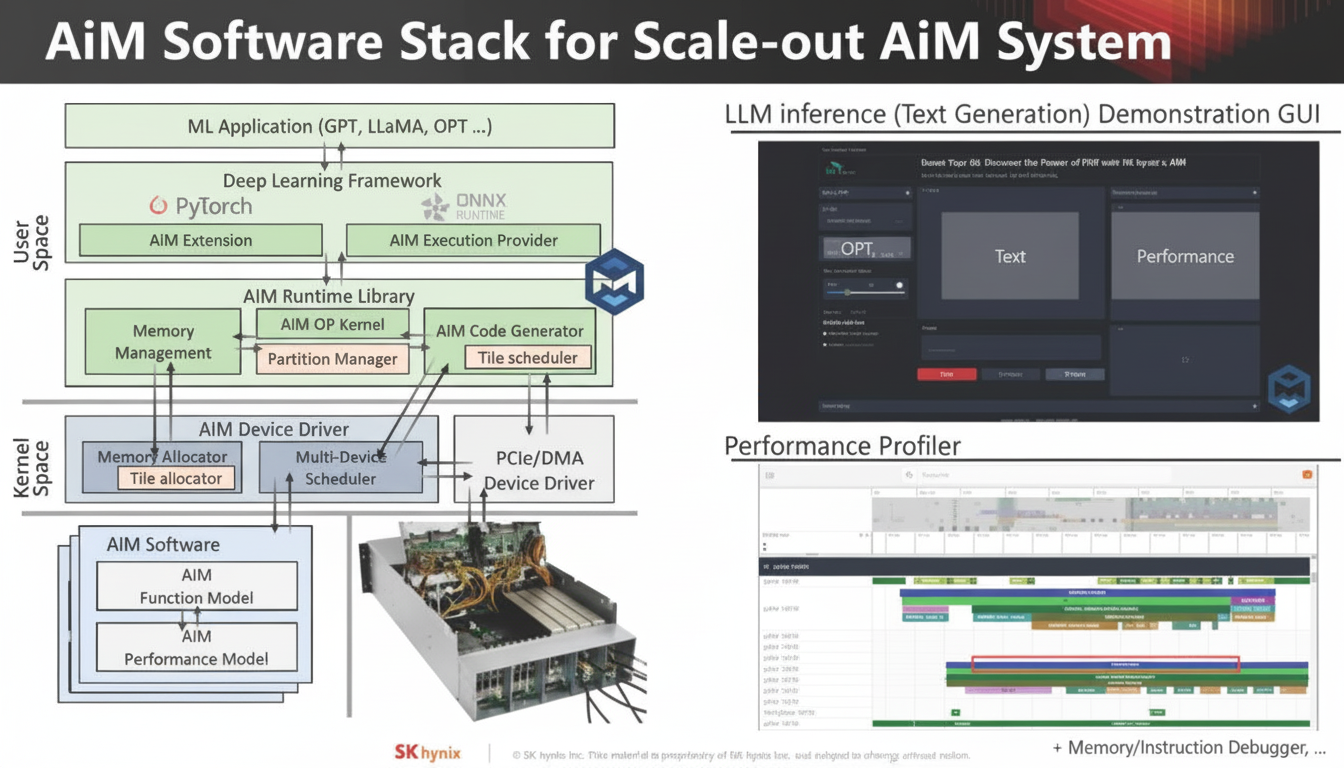
AiM Software Stack
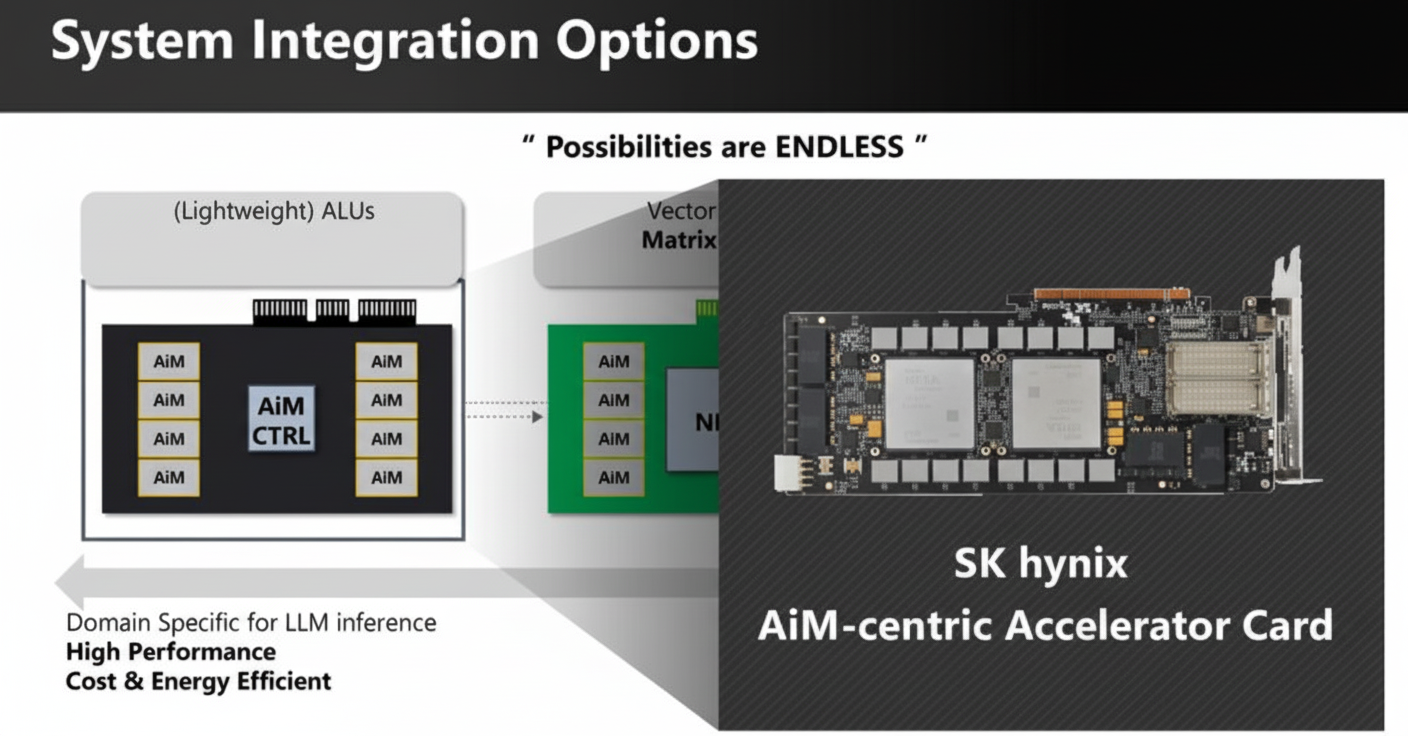
The proof-of-concept is still at the evaluation stage, with various analyses comparing this approach to conventional solutions. It represents a potential direction for future development.