1. Overview
LiDAR panoptic segmentation is a key technology for autonomous driving that enables comprehensive understanding of surrounding objects and scenes while meeting real-time constraints. Recent anchor-free methods speed up computation but face limitations in effectiveness and efficiency due to difficulty modeling nonexistent instance centers and high clustering cost for center-based grouping. To achieve accurate and real-time LiDAR panoptic segmentation, this work proposes a center-focused network (CFNet).
Specifically, the paper introduces a center-focused feature encoding (CFFE) module that explicitly models the relationship between raw LiDAR points and virtual instance centers by moving points and populating center points. A center de-duplication module (CDM) is also proposed to efficiently retain a unique center per instance and suppress redundant center detections. Evaluations on SemanticKITTI and nuScenes panoptic segmentation benchmarks show that CFNet significantly improves performance over existing methods while running 1.6× faster than the most efficient baseline.
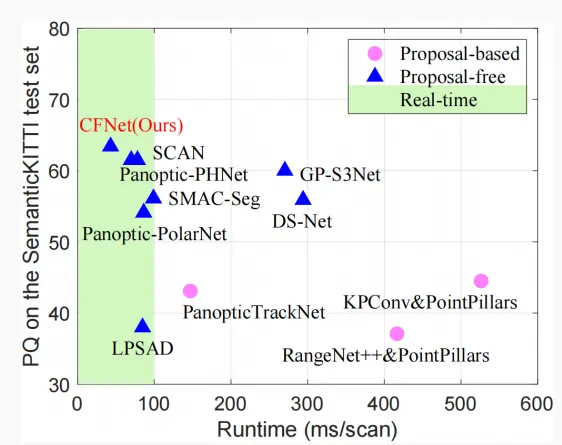
Figure 1. PQ versus runtime on the SemanticKITTI test set.
2. Problem statement
Panoptic segmentation combines semantic segmentation and instance segmentation. It assigns semantic labels to stuff classes (for example road, sidewalk) and both semantic labels and instance IDs to thing classes (for example car, pedestrian). LiDAR panoptic segmentation is a fundamental perceptual task for safe autonomous driving, using LiDAR sensors to capture point clouds that describe the environment. Existing LiDAR panoptic methods typically perform semantic segmentation first, then obtain instance segmentation for thing classes using either anchor-based or anchor-free frameworks.
Anchor-based methods follow a two-stage pipeline similar to Mask R-CNN in the image domain: a 3D detection network generates object proposals, then instance segmentation is produced inside each proposal. These pipelines are often complex and difficult to run in real time due to sequential multi-stage processing.
Anchor-free methods are simpler. To associate thing points with instance IDs, these methods commonly rely on instance centers. They regress per-point offsets toward corresponding centers and then apply category-agnostic center clustering modules or bird's-eye-view (BEV) center heatmaps. However, two main issues remain. First, because LiDAR points are often concentrated on object surfaces, instance centers frequently do not exist in the raw point cloud, making center feature extraction and modeling difficult and causing fragmentary instance segmentation (see Figure 2(a)). Second, clustering modules that handle redundant detected centers (for example MeanShift or DBSCAN) are computationally expensive and not suitable for real-time perception. BEV center heatmaps also fail to separate objects at different heights that fall into the same BEV cell.
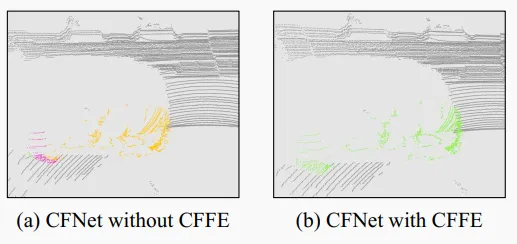
Figure 2. Instance segmentation example for a car. Different colors indicate different instances. Without the CFFE module, the car is segmented into parts (a). CFFE significantly reduces this issue (b).
To address accuracy and speed challenges, CFNet adopts an anchor-free framework. To better encode center features, CFNet introduces the CFFE module, which moves LiDAR points and fills in center points to obtain more accurate predictions (Figure 2(b)). CFNet decomposes panoptic segmentation into semantic segmentation and center offset regression and adds a confidence score prediction to indicate the accuracy of center offset regression. For efficient use of detected centers, CFNet includes a center de-duplication module (CDM) that selects a unique center per instance by keeping higher-confidence centers and suppressing lower-confidence ones. Instance segmentation is obtained by assigning moved thing points to their nearest centers. To improve efficiency, CFNet builds on a 2D-projection-based segmentation paradigm.
3. Method details
The input to the LiDAR panoptic segmentation task is a LiDAR point cloud dataset, where each point has 3D Cartesian coordinates and optional additional features such as intensity. The goal is to assign each point a set of labels: a semantic label (for example road, building, car, pedestrian) and an instance ID for thing classes. Stuff points receive instance ID 0.
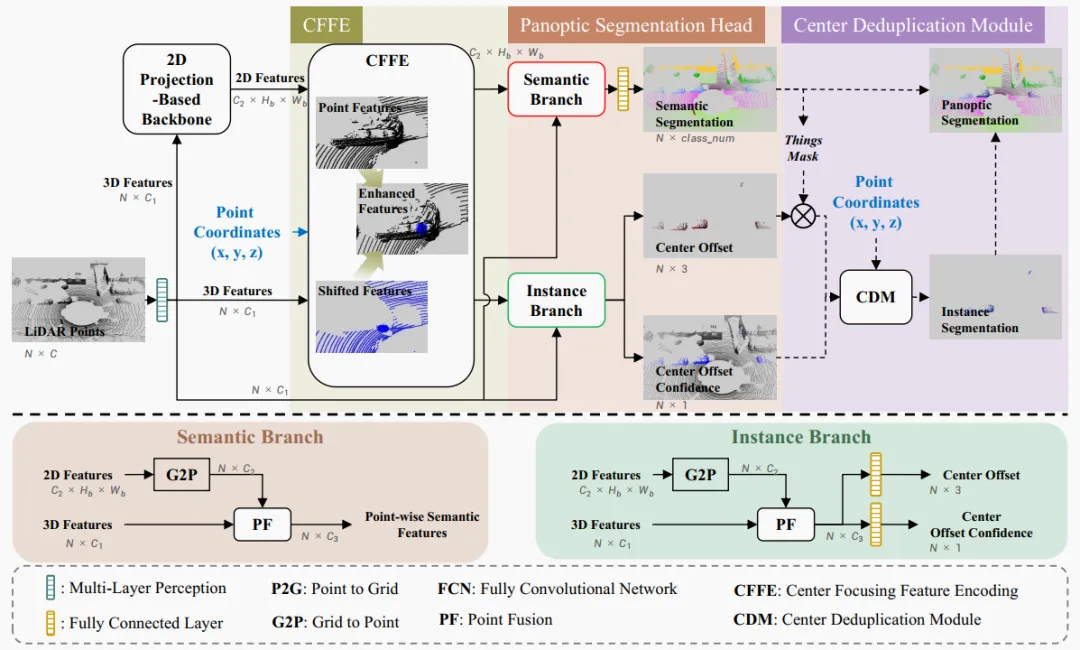
Figure 3. Overview of CFNet. The pipeline contains four steps: 1) a 2D-projection-based backbone extracts features efficiently in 2D space; 2) the proposed center-focused feature encoding (CFFE) synthesizes and enhances absent instance center features; 3) a panoptic segmentation head predicts outputs; 4) the proposed center de-duplication module (CDM) produces instance segmentation, which is fused with semantic segmentation to obtain the final panoptic result. Dashed operations are used only during inference.
CFNet predicts labels for the input point cloud through four steps shown in Figure 3: 1) use an off-the-shelf 2D-projection-based backbone to extract features efficiently in 2D; 2) apply the CFFE module to generate center-focused feature maps for improved prediction accuracy; 3) a panoptic head fuses features from 3D points and 2D space to predict semantic segmentation, center offsets, and offset confidence scores; 4) during inference, post-processing yields panoptic results: CDM selects one center per instance from moved thing points and assigns moved thing points to the nearest center to obtain instance IDs.
3.1 Center-Focused Feature Encoding
As described above, LiDAR points for an object are typically concentrated on surfaces, especially for cars and trucks, which makes instance centers virtual and absent from the point cloud. To encode features for nonexistent centers, CFFE takes backbone-extracted 2D features and 3D point coordinates as input and generates enhanced center-focused feature maps.
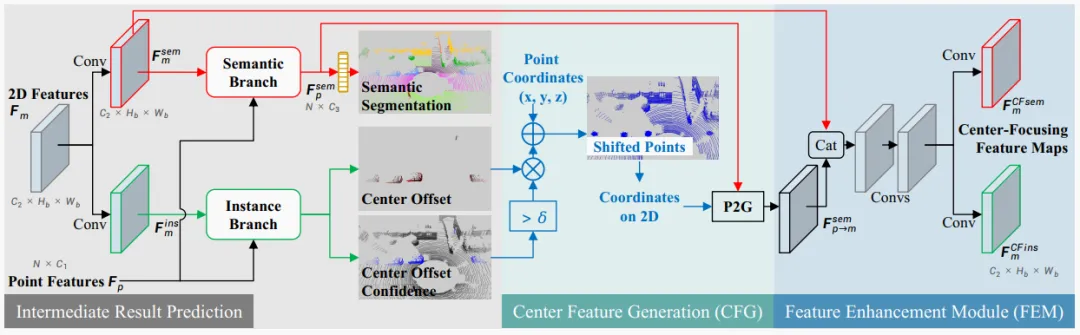
Figure 4. The proposed center-focused feature encoding (CFFE). "Conv" denotes a 2D convolution with a 3x3 kernel followed by batch normalization and ReLU. The semantic and instance branches are detailed in Figure 3. Blue arrows denote coordinate-related operations.
The CFFE module comprises three steps: intermediate prediction, center feature generation, and a feature enhancement module.
Intermediate prediction. CFFE predicts intermediate results (semantic segmentation, center offsets, and their confidence scores) from the 2D features and 3D point features to guide subsequent center feature simulation. Concretely, two convolution layers are applied on the 2D feature map to produce semantic features and instance features for a given 2D view (m denotes a specific 2D view, e.g., range view, BEV, or polar view).
Conv denotes sequential 2D convolution, batch normalization, and ReLU; their parameters are learned. The semantic branch fuses point features and 2D semantic features to generate per-point 3D semantic features. The semantic branch is denoted Seg with parameters. Intermediate semantic predictions are produced accordingly. Intermediate center offsets and confidence scores are predicted by the instance branch using point features and 2D instance features; Ins denotes the instance branch and FC denotes fully connected layers. The structure and training targets of the semantic and instance branches match those in the panoptic head (see Section 3.2).
Center Feature Generation (CFG). CFFE generates shifted center features by moving 3D semantic point features according to the intermediate predictions to their predicted centers.
First, the predicted center coordinate for a point is computed using the formula shown in the original material image.
The prediction uses the original 3D point coordinate and a binary indicator that determines whether the point is moved based on a confidence threshold. In other words, the module does not move stuff points or thing points with low confidence.
Then, the shifted 3D points serve as feature-bearing coordinates. The 3D semantic features are reprojected to the 2D projection feature map at these new coordinates via a point-to-grid (P2G) operation.
The resulting shifted feature map focuses more on the virtual centers, since many thing points have been shifted to their predicted centers.
Feature Enhancement Module (FEM). Finally, CFFE fuses the semantic feature map and the reprojected shifted center feature map to produce center-focused semantic and instance feature maps, which enable more accurate predictions by the subsequent semantic and instance branches. The enhancement module uses concatenation and several convolution layers; its detailed structure is provided in the supplementary material.
For backbones that support multi-view fusion, feature maps for each view (for example m in {RV, BEV}) are computed independently via the above process and then fused in a point fusion (PF) module to generate integrated 3D point features and per-point predictions.
3.2 Panoptic segmentation head
To better model instance centers, the panoptic head contains a semantic branch that predicts semantic segmentation and an instance branch that estimates center offsets and the introduced confidence score. These take the center-focused semantic and instance feature maps as input.
Semantic branch. For per-point prediction, the semantic branch first applies a grid-to-point (G2P) operation to obtain 3D point representations from the 2D semantic feature map. A PF module fuses the G2P point representation with original 3D point features to produce per-point semantic features. A fully connected layer predicts final per-point semantic outputs, where the output denotes the probability that point i belongs to class c. The predicted semantic label is obtained by argmax over class probabilities.
The loss function follows prior work and includes weighted cross-entropy loss, Lovász-Softmax loss, and transformation consistency loss.
Instance branch. The instance branch similarly uses G2P and a PF module to obtain per-point instance features. An FC layer predicts per-point center offsets. The ground truth offset for point i is the vector from that point to its instance center.
For center offset regression, the loss is optimized only over thing classes and is formalized as shown in the original material image, where the instance center is the axis-aligned center of the instance.
The total offset loss sums over all points and thing points as shown in the original material image, where N and M denote numbers of all points and thing points respectively.
For confidence score regression, an additional FC layer predicts per-point confidence scores to indicate the accuracy of predicted offsets. A sigmoid activation ensures scores lie in [0,1]. Ground truth confidence labels are generated by the formula shown in the original material image: for thing points, the lower the offset error, the higher the ground truth confidence, meaning points with more accurate offset regression receive higher confidence scores.
The confidence prediction is supervised using a weighted binary cross-entropy loss, shown in the original material image, where thing points are emphasized because they are much fewer than stuff points.
Finally, the loss for each prediction group (from CFNet or from CFFE intermediate results) is defined as shown in the original material image. The total loss is the sum of the two losses from CFNet and CFFE.
3.3 Center de-duplication module
Given final predicted semantic segmentation, center offsets, and confidence scores, this section describes how to utilize detected centers during inference to obtain panoptic results and details the center de-duplication module (CDM).
Post-processing. Instance segmentation is generated first, then fused with semantic segmentation labels to obtain panoptic results. The steps are:
- Select thing points based on predicted semantic labels and collect their offsets and confidence scores (M denotes the number of thing points).
- Each shifted thing point becomes a candidate instance center.
- CDM selects one center per instance based on coordinates and confidence scores while suppressing other candidates.
- Instance IDs are obtained by assigning each shifted thing point to the nearest center among all retained centers (D denotes the number of detected instances).
- Majority voting assigns the most frequent semantic label within a predicted instance to all points of that instance to ensure semantic consistency.
Center de-duplication module (CDM). CDM takes shifted points and confidence scores as input and returns one center per instance. Inspired by bounding-box NMS, if the Euclidean distance between two centers is smaller than a threshold, CDM suppresses the center with lower confidence. Pseudocode for CDM is given in Algorithm 1 in the original paper; two centers closer than the distance threshold are considered the same instance. CDM is simple and can be implemented efficiently in CUDA.
4. Experiments
CFNet is evaluated on SemanticKITTI and nuScenes panoptic segmentation benchmarks. Runtime measurements are reported on a single NVIDIA RTX 3090 GPU and panoptic quality (PQ) is used to assess performance. CFNet outperforms existing methods on both benchmarks and runs 1.6× faster than the most efficient prior method.
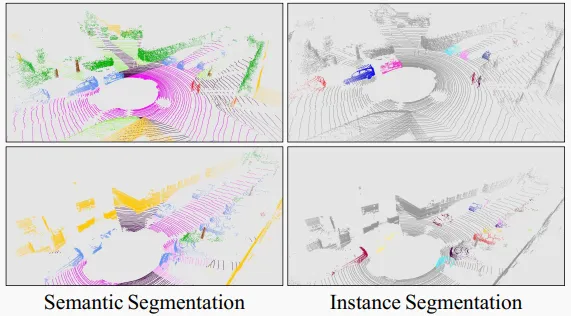
Figure 5. Visualization of CFNet results on the SemanticKITTI test set. Different colors represent different classes or instances.
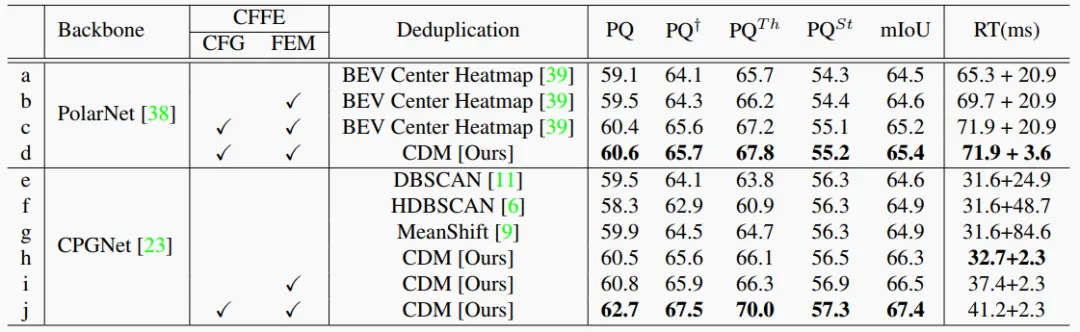
Table 1. Ablation study on the SemanticKITTI validation set. RT: runtime.
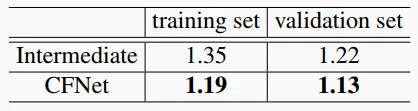
Table 2. Average thing center offset error on SemanticKITTI training and validation sets for intermediate predictions and CFNet with CFFE (units: meters).
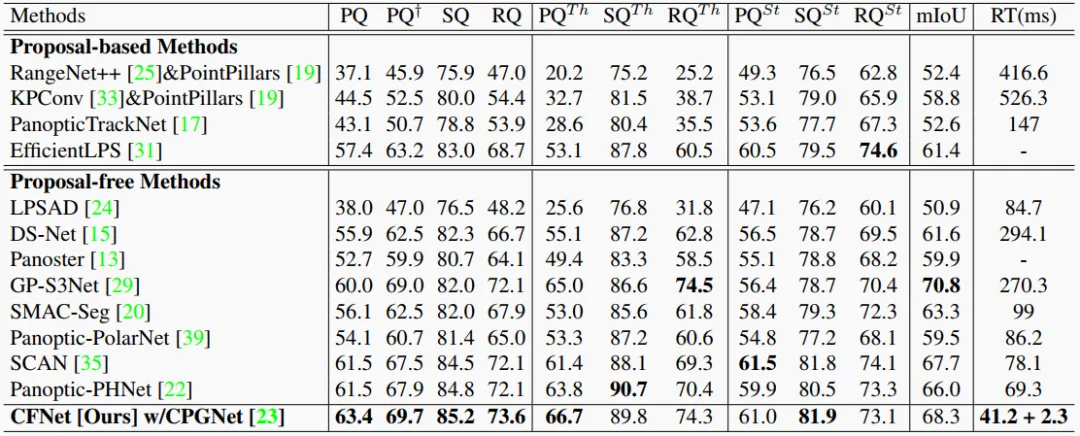
Table 3. Results on the SemanticKITTI test set.
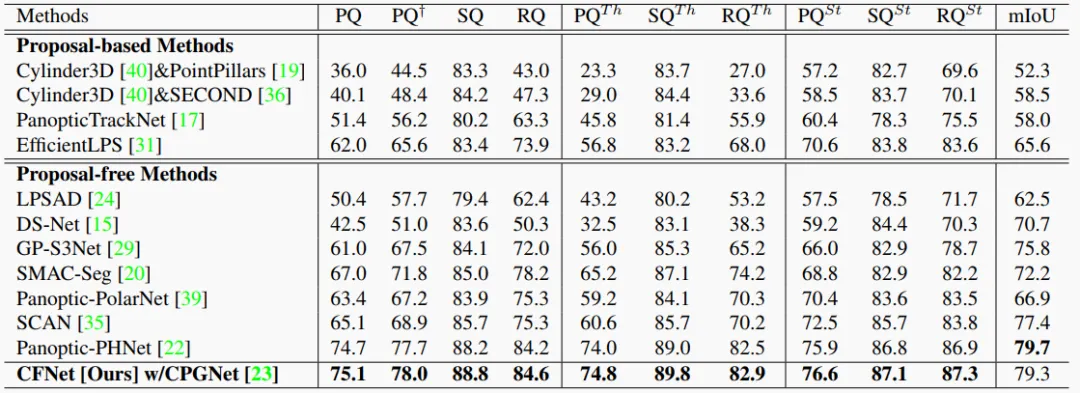
Table 4. Results on the nuScenes validation set.
5. Conclusion
This paper presents CFNet, a novel anchor-free center-focused network for real-time LiDAR panoptic segmentation. To better model and utilize nonexistent instance centers, the paper proposes the CFFE module to generate enhanced center-focused feature maps and the CDM module to retain a unique center per instance. Instance IDs are obtained by assigning shifted thing points to their nearest retained centers. Experiments show that center modeling and utilization are key challenges for anchor-free LiDAR panoptic segmentation, and simulating absent center features is a promising direction with clear benefits.