Abstract
SLAM algorithms are a key component for autonomous navigation of mobile robots. LiDAR offers high ranging accuracy, low susceptibility to external disturbances, and intuitive map construction, and is widely used for mapping large and complex indoor and outdoor scenes. With the adoption of 3D LiDAR, researchers in China and abroad have achieved substantial progress on SLAM algorithms based on 3D LiDAR.
This article reviews research on 3D LiDAR SLAM in front-end data association and back-end optimization, analyzes the principles, advantages, and disadvantages of current mainstream 3D LiDAR SLAM algorithms and improvements, and describes applications of deep learning and multi-sensor fusion in 3D LiDAR SLAM. It highlights multi-source information fusion, integration with deep learning, robustness across application scenarios, general SLAM frameworks, and the influence of mobile sensors and wireless signal systems as current research hotspots and future directions.
1. Introduction
The classic SLAM framework consists of a front end for data association and a back end for optimization. The front end registers consecutive LiDAR frames via scan matching, performs loop closure detection to obtain relations between frames, updates pose estimates, and stores map information. The back end maintains and optimizes the pose estimates and observation constraints from the front end to obtain maximum-likelihood estimates of the map and current robot pose.
LiDAR-based SLAM is typically divided into 2D and 3D LiDAR approaches. Compared with vision sensors, LiDAR provides higher ranging accuracy, is less affected by illumination and viewpoint changes, and yields more intuitive maps. 2D LiDAR is mature and widely used for planar environments but cannot handle full-terrain scenarios. 3D LiDAR emits multiple laser beams to capture geometric information and produces point clouds that reflect 3D structure; higher beam counts yield denser point clouds and clearer environmental descriptions.
With mass production of multi-beam LiDAR, lower power consumption and stronger embedded processing, 3D LiDAR is becoming more cost-effective and reliable, driving rapid development of 3D LiDAR SLAM algorithms. The LOAM (LiDAR Odometry and Mapping) algorithm proposed by Zhang et al. in 2014 is a representative method that separates odometry and mapping, offering high speed, accuracy, and robustness with low computation. Its drawbacks include lack of loop closure and degeneracy in feature-sparse open areas. Variants such as LeGO-LOAM add loop closure and ground segmentation to improve efficiency and robustness. A-LOAM simplifies LOAM implementation using linear and nonlinear solvers. Other frameworks include IMLS-SLAM, which uses implicit moving least squares surfaces for accurate pose estimation but is not real time, and SuMa, which uses surfel-based maps for robust global mapping from LiDAR alone.
Although many 3D LiDAR SLAM methods perform well on public datasets with low drift and high trajectory accuracy, practical limitations remain: robustness across environment transitions (indoor/outdoor, static/dynamic), real-time performance on resource-limited platforms, and robustness in feature-poor scenes.
Existing surveys often focus on visual SLAM or specific SLAM aspects; comprehensive overviews of 3D LiDAR SLAM are fewer. This article systematically presents mainstream 3D LiDAR SLAM approaches from front-end and back-end perspectives and discusses deep learning and multi-sensor fusion applications, current shortcomings, and future research directions.
2. SLAM Front End
The front end of 3D LiDAR SLAM handles data association: scan matching addresses local associations, while loop closure detection handles global associations. Both establish constraints between nodes from LiDAR frames.
2.1 Scan Matching
Scan matching accuracy and computational efficiency directly affect trajectory estimation and mapping accuracy, and they supply initial pose estimates and constraints to the back end. Scan matching methods are broadly classified as ICP-based, geometric-feature-based, and mathematical-feature-based.
ICP-based Methods
The classical Iterative Closest Point (ICP) algorithm minimizes distance error iteratively to find the best transform between scans, but it is prone to local minima and expensive for large point sets. Variants suitable for 3D LiDAR SLAM include point-to-plane ICP, point-to-line ICP, generalized ICP (GICP), and normal ICP (NICP). GICP unifies ICP variants in a probabilistic framework for improved accuracy. IMLS-ICP assigns weights and reconstructs local surfaces using implicit moving least squares. Methods like LiTAMIN introduce symmetric Kullback-Leibler divergence into the ICP cost to reduce correspondence counts. Despite improvements, ICP and its variants still require many iterations, depend on good initialization, and are sensitive to noise; raw point cloud matching remains computationally costly.
Geometric-Feature-Based Methods
Feature-based scan matching extracts edge and planar features and matches them between scans. LOAM extracts edge and plane features based on local smoothness and matches scan points to map features. Extensions such as LeGO-LOAM add ground separation before feature extraction to increase robustness. R-LOAM uses grid-based reference features to reduce long-term drift but requires accurate 3D grid and reference localization. Feature-based methods reduce computation by iteratively solving for specific geometric shapes, offering good real-time performance and high precision, but they degrade when geometric features are weak or ambiguous.
Surfel-Based Methods
Surfels approximate 3D surfaces with oriented points and can be used for registration and mapping, though they often require GPU processing. SuMa and Elastic-LiDAR Fusion approximate LiDAR scans as surfels and perform odometry and loop closure on surfel maps.
Mathematical-Feature-Based Methods
Mathematical-feature methods use properties such as normal distribution transforms (NDT). 2D-NDT and 3D-NDT represent point clouds with Gaussian distributions for efficient registration. Variants like occupancy NDT offer compact 3D map representations with low memory and high speed. RGC-NDT leverages clustering to capture natural details, improving accuracy and reducing runtime. VGICP voxelizes GICP to avoid expensive nearest-neighbor searches for faster, accurate 3D registration.
2.2 Loop Closure Detection
Front-end approximations and incremental back-end mapping accumulate error over time. Loop closure detection is critical to prevent excessive drift by recognizing revisited places and adding constraints to correct global poses and maps. False positives can cause severe global inconsistencies, while missed closures allow drift to grow. Loop closure quality directly affects global map consistency. Due to LiDAR point clouds being sparse and unordered, loop detection remains challenging and no universal best solution exists.

Simple geometric correlation strategies like those proposed by Olson and ICP-based loop checks in LeGO-LOAM can fail in large-scale scenarios due to accumulated odometry drift. An alternative is to construct descriptors from geometry, intensity, or other cues and compare them. Descriptors can be handcrafted or learned by deep networks. Local descriptors around keypoints and global descriptors for the entire point cloud are both used. Examples of local keypoint detectors and descriptors include 3D-SIFT, 3D-Harris, 3D-SURF, ISS, SHOT, B-SHOT, ISHOT, and FPFH. Global descriptors include M2DP, GLAROT-3D, and Scan Context. Hybrid methods such as SegMatch and SegMap segment a point cloud into parts and match segment descriptors, combining local and global strengths to handle sparse point clouds. SegMap also supports map compression and semantic extraction for navigation and operator visualization.
Deep learning has enabled learned global descriptors from point clouds, e.g., PointNetVLAD, DH3D, MinkLoc3D, PPT-Net, FastLCD, NDT-Transformer, Overlap-Transformer, and others. Learned methods often achieve high performance but require large training datasets and substantial compute, and they may not generalize across different terrains or sensing conditions. Lightweight architectures and real-time performance remain active research areas. Semantic descriptors, which encode object-level semantics and spatial relations, offer robustness in challenging environments and support long-term localization.
3. SLAM Back End
The back end aims to jointly optimize poses and inter-frame constraints to eliminate accumulated local error and produce a consistent map. Approaches include filtering and nonlinear optimization. Filtering methods, such as extended Kalman filters, can be adaptive but lack loop closure handling and scale poorly for large environments. Nonlinear graph-based optimization considers all constraints for high accuracy at the cost of higher computation. Efficient back-end optimization to correct motion and improve map accuracy is a key research focus.
3.1 Filtering-Based SLAM
Filtering-based SLAM uses Bayesian estimation. EKF-SLAM linearizes nonlinear motion and measurement models and suffers from linearization errors and lower robustness. Unscented Kalman Filters improve accuracy for nonlinear systems. Particle filter methods represent posterior distributions with weighted particles. RBPF and Fast-SLAM reduce complexity by separating pose estimation and map estimation; gmapping is a notable particle-based LiDAR SLAM implementation.
3.2 Nonlinear Optimization-Based SLAM
Graph optimization, introduced by Lu et al., maintains key nodes and optimizes a pose graph to balance precision and computation. Common open-source optimization libraries include Ceres Solver, iSAM, GTSAM, g2o, and bundle adjustment packages, which speed up backend iterative solutions. Modern back ends leverage factor graphs and sliding-window approaches for real-time and robust performance.
4. Deep Learning in 3D LiDAR SLAM
Deep learning provides data-driven models that can outperform handcrafted features in certain SLAM submodules. Deep models are applied to inter-frame pose estimation, loop closure detection, and semantic mapping. End-to-end and hybrid approaches exist for point cloud registration. Table images in the original article summarize feature-learning approaches for pose estimation and loop closure.
4.1 Inter-frame Estimation
Deep-learning-based inter-frame estimation often outperforms purely geometric methods but faces challenges due to point cloud sparsity and computation. Two main approaches are feature-learning methods for registration, e.g., 3DFeat-Net, FCGF, Siamese-PointNet, and UGMMReg, and end-to-end registration networks, e.g., DeepGMR, 3DRegNet, MLP_GCN, and IPCR. Combining deep learning with classical registration theory in hybrid frameworks offers a promising direction to achieve both accuracy and efficiency.
4.2 Loop Closure Detection
Traditional loop closure methods rely on hand-designed features and can be computationally heavy. Learned global descriptors from point clouds, such as PointNetVLAD, DH3D, MinkLoc3D, PPT-Net, FastLCD, and NDT-Transformer, improve robustness. However, learned methods require extensive training data and often need GPUs. Research priorities include lightweight networks, real-time capability, and generalization across environments. Combining geometric and semantic features, e.g., SSC and RINet, enhances descriptor discriminability and rotation invariance.
4.3 Semantic Segmentation and Semantic Maps
Semantic SLAM goes beyond geometric mapping by recognizing movable objects, sharing object representations, and constructing semantic maps to improve navigation and human-robot interaction. PointNet and successors (PointNet++, PointCNN), graph-based and attention models, and efficient architectures for large-scale point clouds such as RandLA-Net, SCF-Net, and DSPNet++ have advanced point cloud semantic segmentation. Projection-based methods like RangeNet++ and RangeSeg, and hybrid fusion networks such as RPVNet, address voxelization and density variation challenges. However, converting point clouds to structured representations can lose geometric detail and increase resource consumption. Designing reliable, fast semantic segmentation for LiDAR remains an open problem.
For semantic mapping, methods such as Recurrent-OctoMap, SuMa++, and SA-LOAM integrate learned semantics into map representations and loop closure processes, improving long-term mapping and localization. For example, SA-LOAM integrates semantic segmentation into LOAM to aid odometry and loop detection and can produce globally consistent semantic maps.

5. Multi-Sensor Fusion for 3D LiDAR SLAM
Each sensor modality has limitations. Fusion of multiple sensors yields more accurate, robust, and adaptive SLAM. Processing and fusing heterogeneous modalities remains a central challenge.
5.1 LiDAR and IMU Fusion
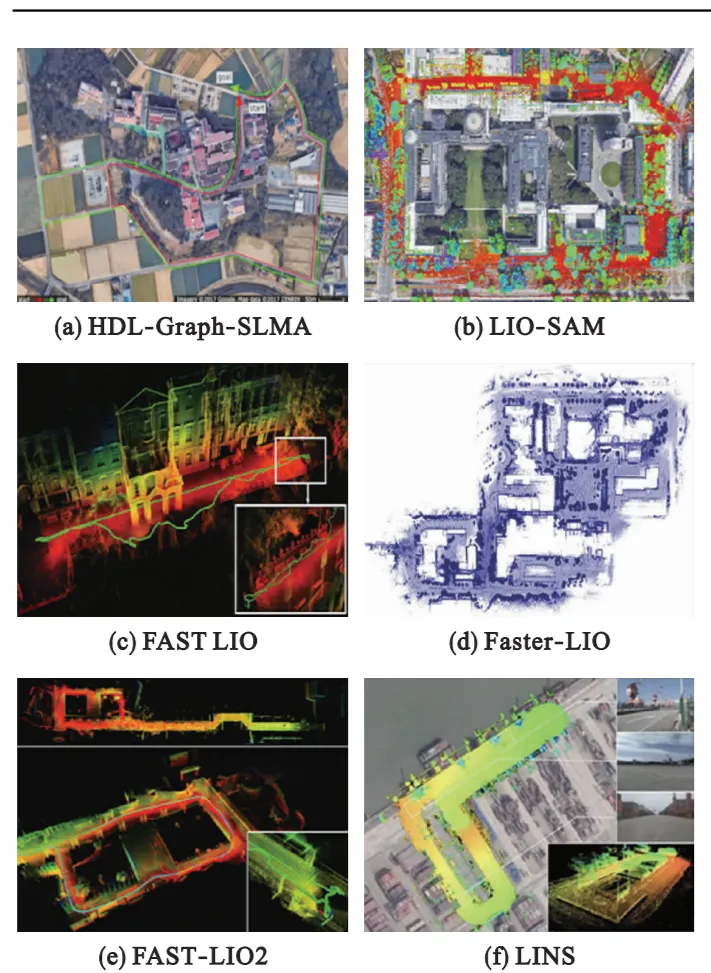
Fusing LiDAR with an inertial measurement unit (IMU) addresses low vertical resolution, low update rates, and motion distortion in LiDAR. Fusion can be tightly-coupled, jointly optimizing all measurements for accurate poses but at high computational cost, or loosely-coupled, fusing separate sensor estimates for lower complexity but limited accuracy. Representative approaches include HDL-Graph-SLAM, Inertial-LOAM, LIO-mapping, LIOM, LIO-SAM, LiLi-OM, FAST-LIO, FAST-LIO2, Faster-LIO, and LINS. FAST-LIO2 uses an incremental k-d tree to reduce computation while improving odometry and mapping. Tight coupling generally improves map accuracy and robustness, but calibration and synchronization between LiDAR and IMU remain challenging.
5.2 LiDAR and Vision Fusion
LiDAR offers strong local accuracy but weaker global localization and environment sensitivity; vision provides complementary global context. Combined systems such as V-LOAM, LVI-SAM, SuperOdometry, R2 LIVE, and R3 LIVE integrate LiDAR, vision, and IMU to produce robust, high-accuracy maps even in challenging scenarios. These multi-modal frameworks balance fast visual motion handling with LiDAR stability in poor lighting.
5.3 LiDAR and Other Radar Fusion
Millimeter-wave radar can complement LiDAR in low-visibility conditions such as smoke or dust. Fusion methods at the decision, scan, or map level have been explored to combine radar and LiDAR strengths. Multi-sensor pipelines combining camera, radar, LiDAR, and GPS have been proposed for robust detection, tracking, and mapping in diverse environments.
6. Trends in 3D LiDAR SLAM Research
6.1 Multi-Source Information Fusion
Single sensors cannot cover all scenarios. Research on fusion schemes—IMU, vision, radar, multiple LiDARs—remains a major trend. Open problems include robust online calibration, time synchronization, and generalizable geometric feature extraction and association across modalities. Joint nonlinear optimization and deep-learning-based point cloud processing will accelerate fusion techniques.
6.2 Integration with Deep Learning
Combining SLAM with deep learning improves robustness and efficiency in feature extraction, semantic mapping, and relocalization. Current limits include lack of physical interpretability, large training data needs, long training times, and the requirement for GPU resources. Lightweight models and better generalization remain active areas of work.
6.3 Robustness Across Application Scenarios
SLAM must operate reliably across varied scenarios: open spaces, dynamic environments, aerial and ground robots, and autonomous vehicles or AGVs. Algorithms should handle changing illumination, high dynamics, feature-sparse areas, and large-scale maps. Methods for multi-robot global localization, dynamic scene mapping, and long-term consistent mapping are important directions.
6.4 Exploring General Frameworks and Map Representations
Developing general SLAM frameworks has value. Many approaches build on LOAM; others propose frame-to-model matching or unified pipelines combining feature extraction, distortion compensation, pose optimization, and mapping. Richer map representations such as semantic maps improve robot understanding and SLAM robustness.
6.5 Sensor and Wireless System Impact
Solid-state LiDARs with low cost and compact form factors are gaining attention and will influence SLAM design. Advances in hardware, embedded processing, and wireless integration will shape SLAM deployment on mobile platforms. Dedicated processors and integrated modules can reduce computational bottlenecks and lower implementation barriers.
7. Conclusion
SLAM enables mobile robots to build maps of unknown environments and estimate poses for autonomous navigation, path planning, and exploration. As 3D LiDAR moves toward lower cost, lower power, and higher reliability, substantial progress has been made in 3D LiDAR SLAM research and applications. This article summarized front-end and back-end methods, deep learning contributions, and multi-sensor fusion approaches, discussed current limitations, and highlighted research directions including multi-source fusion, deep-learning integration, robustness for dynamic and diverse scenarios, general SLAM frameworks, and embedded implementations that leverage mobile sensors and wireless systems.